User:Waldyrious
| Babel user information | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ||||||||||||
| Users by language |
About me: Waldir@meta.wikimedia
Work in progress
[edit]- We need a way to explain the reason for constraints.
- I've proposed this here.
- There should be a "TED event ID" property, to complement TED speaker ID (P2611), TED topic ID (P2612) and TED talk ID (P2613).
- I've proposed it here.
- There should be a "source code archives" property to complement source code repository URL (P1324) (which should only contain links to repositories using version control systems).
- See for example the entries at GNOME System Monitor (Q3756198).
- full work available at URL (P953) is meant for the full text of a written work. It could be expanded to include this case, but I think it's better to keep things explicit.
To do
[edit]Recurring tasks
[edit]- Clean up Repology's Problems in Wikidata report
- Clean up the tricky items in Mix'n'match Exoplanets list
Assorted todo
[edit]- Descriptions (semi-automated?)
- TODO: Add "country of citizenship (P27)→demonym (P1549) occupation (P106)" as description for human (Q5) items that have both properties and no English description
WIP query, for Portuguese people only: https://w.wiki/4K6h- Update: this doesn't correctly filter for
count(?occupation) = 1; Lukas Werkmeister explained why in Telegram: "you’re grouping by?occupationLabelas well, so unless two occupations have the same label,COUNT(?occupation) = 1will always be true", and offered an improved version: https://w.wiki/4K75 - TABernacle version
- Update: this doesn't correctly filter for
- Sample of the QuickStatements v2 (CSV) commands to add the missing descriptions (based on the data outputted by the query):
- qid,Den
- Q10261736,Portuguese Catholic priest
- Q10262996,Portuguese banker
- Q10277601,Portuguese sailor
- Some bots that add descriptions (their code could be useful for inspiration): User:Mr.Ibrahembot, User:Edoderoobot, User:MatSuBot.
- TODO: Add "country of citizenship (P27)→demonym (P1549) occupation (P106)" as description for human (Q5) items that have both properties and no English description
- Is there a way to generate a list of Wikidata items that should have a Universal Decimal Classification (P1190), but don't?
- Is it perhaps specific to books?
- Should it not be extended to other domains (in which case, where to get authoritative mappings?)
- See also: Wikidata:WikiProject Ontology
- Change MediaWiki:Wikibase-entitytermsforlanguagelistview-more from "All entered languages" to "Show all entered languages" (and the same for MediaWiki:Wikibase-entitytermsforlanguagelistview-less ("Fewer languages" → "Show fewer languages")
- Suggest a new property accepting values of the math datatype (list of current ones), for multilevel formulas such as this one.
- Something like "has part", but equivalent to the mathematical "where".
- See also discussion here.
- TODO: split first and last names; group by count; check for existence of the top ones; create when needed.
- Colors: Color mapping (Q5148617), palette (Q2357944)... colormap? viridis?
Geography
[edit](Moved to Workflowy.)
Cape Verde
[edit]- Wikidata:WikiProject Cape Verde
- TABernacle dashboard of Cape Verdean people
- TODO: Ensure items whose labels are pseudonyms have a full name statement with the actual birth name
- TODO: Add languages spoken, written or signed (P1412)Cape Verdean Creole (Q35963) and ancestral home (P66)Cape Verde (Q1011) (or any location within it)
- TODO: build a version in the Profiling Wikidata tool, like this one: https://prowd-prototype.herokuapp.com/profile/33
Lexemes (kea dictionary)
[edit]- Books I own
- Dicionário Caboverdiano—Português (Manuel Veiga)
- Léxico do dialecto crioulo do Arquipélago de Cabo Verde (Armando Napoleão Rodrigues Fernandes)
- Google Sheets file
- Stats in the Ordia tool
- Tools to work with lexemes (To experiment with)
- Apparently Wikidata-Toolkit-9.0 (written in Java) was used to convert Basque Wiktionary entries into Wikidata entries
- Here's another one that aims to convert Wiktionary data to Lexemes: https://github.com/nyurik/lexicator (written in Python)
- TODO: Create Wikidata:Lexicographical data/Documentation/Languages/kea, documenting the intended structure for kea lexemes, showing examples of lexemes for various word classes, etc.
- Examples
- Contents
- Guidelines: what language to use for "spelling variant"; how to model dialect variations; which properties to set in the senses, which grammatical features to set in the forms, etc.
- Instructions for how to create lexemes, add pronunciation, etc.
- TODO: set up completion dashboards for lexemes
- Senses: translations, glosses in en/pt/kea, item for this sense, etc.
- Forms: badiu & sampadjudu, IPA transcription, pronunciation audio
- Perhaps a simplified interface (as a toolforge tool?), similar to how ninjawords.com did for Wiktionary. Example image:

- Hauki (listed here, source code here) appears to be one such attempt (example)
- Maybe Jon Harald Søby could work his magic like he did for the Compact items gadget? 😁
- Automatic list of kea lexemes: Try it!
SELECT ?item ?lexemeLabel WHERE { ?item a ontolex:LexicalEntry ; dct:language wd:Q35963 ; wikibase:lemma ?lexemeLabel . }

TEDxPraia
[edit]Goal: Add items for the TEDxPraia event (tedxpraia.com, TED event ID 19377) and talks
- video playlist
- Existing instances of TEDx talk: https://w.wiki/LJ6
- Rendered version, updated regularly: Wikidata:TED/TEDx Talks
- Note: at the moment not all of these (https://w.wiki/LJ7) have a TED talk ID (P2613). I believe that ID is only available for those that have been featured on the main TED.com site.
- That said, they should all have author (P50), title (P1476) and YouTube video ID (P1651). At the moment most of them (https://w.wiki/LJ9) only have the author (but the title can be easily extracted from the label)
- Existing subclasses of TEDx conference: https://w.wiki/LJA
- Lists that should be synced with the result of the query above:
Scripts / gadgets
[edit]- Auto-fill item titles (labels) with corresponding language's article title (using the same algorithm as link piping to cut out parentheticals, etc.)
- User:Waldir/autoFill.js
- Use button to auto-save (dialog asking to confirm)
- Support fallback languages
- Suggest content for unfilled descriptions, with:
- First sentence of corresponding language's article
- Automatic translation of description in other languages, in the order defined by translatewiki's fallback chain (should be accessible through API), ultimately falling back to English
- Highlight (bolden) the label for the current interface language, or move it to the top
Musical chords
[edit]Goal: model musical chords in Wikidata.
- Currently there are various *subclass of (P279)chord (Q170439)but they should be separated into two families: relative chords (i.e. chords comprised of a specific relationship between the component notes, like Elektra chord (Q5358758)), and "absolute" chords (i.e. chords built around a specific root note, like C♯ chord (Q24076679)). Then there should be items for the individual chords at each intersection of those two categories. There are other categories as well, e.g. chords by number of notes (e.g. triad (Q944899))
- TODO: Synthesize and record audio samples of all chords, upload the files to Commons, and add them to the Wikidata items
- TODO: Generate standardized diagrams for all main chords and add them to the items
- sheet music diagrams
- pitch constellation images
- guitar fretboard diagrams (in standard tuning). Possibly using vexchords
- piano chord diagrams (see also the parent categories Category:Chords on musical keyboards and Category:Musical keyboard diagrams)
- Lissajous knots (preferably animated, or even in actual 3D)
- Besides chords, notes should also be represented — both the generic ones (aka pitch classes) like C (Q843813), and the specific ones belonging to a given octave, like C6 (Q96254632).
- Wikidata:List of properties/work#Wikidata property for items about musical works
- Dynamic list (query): Music-related (non ID) properties
- Plus Parsons code (P1236)
- TODO: request creation of properties for instances/subclasses of musical term (Q20202269) that aren't tied to specific musical works.
- Perhaps as instances of a new direct subclass of Wikidata property related to music (Q27525351)
- currently there's only Wikidata property for items about musical works (Q22965078)
- Should include:
- melody-related properties: ambitus (P2279), tonality (P826), instrumentation (P870), ...
- timing-related properties: time signature (P3440), tempo marking (P1558), beats per minute (P1725), rhythmic pattern (Q21655334), ...
- Perhaps as instances of a new direct subclass of Wikidata property related to music (Q27525351)
- Wikidata:WikiProject Music
- Specifically the sections Musical scales and Chords
- Relevant properties: tonality (P826), sheet music (P3030), chord progression (P6116), and others.
- Properties:
- Some notes from the top of my head:
- Open vs. barre chords
- tuning
- playing method
- Positioning of each finger (tab notation? Perhaps something similar to Parsons code (P1236)?)
- Possibly useful:
- Help:Modelling/arts/music (empty ATM)
- Subcategories of commons:Category:Guitar chords (currently: Guitar chords by tuning; Hendrix chord; Open chords; Power chords)
- The cleanest style can be found at commons:Category:SVG guitar fretboard diagrams (LilyPond style)
- ChordPro provides a custom format for encoding a chord, including fingering data:
- Acoustic Guitar Notation Guide: Overview of the various methods
- How to Read a Chord Diagram and Other Chord Notation (section "Numeric Chord Notation")
- The gist of it is:
x32010represents this diagram (the C major (Q55706505) chord)
- The gist of it is:
- Some notes from the top of my head:
- New data type: musical notation
Software data
[edit]- Pathways for Discovery of Free Software (slide deck from LibrePlanet 2018)
- SoftwareHeritage.org
- Libraries.io
- Repology (not mentioned)
- Release-monitoring.org
- Several others mentioned
- Clean up license data
- license = copyright (Q12948581)
- and more generally, any item that has a license set to an item that is not a subclass of license (Q79719)
- or any instance of software (Q7397) that has a license set to an item that is not a subclass of software license (Q207621)
- proprietary software (Q218616) vs. proprietary license (Q3238057) vs. proprietary software (Q31202214) vs. commercial software (Q1340793)
- license = copyright (Q12948581)
- Example query: free software that can read the OBJ file format → https://w.wiki/LJ3
- See info at User:MichaelSchoenitzer/FLOSS
- Maybe use toolforge:integraality to produce a dashboard of properties coverage
- Mix'n'match catalogs under the "Software" group
- Wikidata:WikiProject Informatics/Software/Properties
- TODO: cross-check (merge?) with list of properties
- TODO: propose a "development status" or "lifecycle" property that can complement end time (P582), with values like "active", "dormant", "abandoned", "archived", etc. Check for existing ontologies, such as http://repostatus.org or something more formal
- Repology
- See Comment by Repology's maintainer
- See discussion in the property talk page
- Automated report of outdated software versions in Wikidata
- TODO: to connect this with one of the software version updater tools
- Automated reports of packages missing in Wikidata that are in other repos: Arch, DistroWatch, etc.
- TODO: convert these into a Mix'n'match catalog. Ideally weighted/filtered by number of (unrelated) repos?
- Identifiers (see also programming-language-specific package managers/repositiories, aka application-level package manager (Q98400282), such as PyPI, NPM, etc.; non-exhaustive list here)
- Software versions
- software version identifier (P348)
- How does one point to the URLs of the release? The URL property seems to be disallowed...
- In table form: tabular software version (P4669)
- Should the existing data be converted?
- Can the tables have a common schema?
- The MediaWiki example seems to define its own schema inline...
- In particular, I'm wondering about the addition of support periods.
- TODO: Import all versions of Julia (and maybe additional metadata) from https://github.com/jlenv/julia-versions.
- Also add support periods. For instance, minor versions don't have LTS, so newer releases supersede previous ones, as described here.
- User:Github-wiki-bot (usage) can import releases data from GitHub
- software version identifier (P348)
Unix distro manifests
[edit]I.e. the set of packages that come pre-installed with (specific versions of) Unix-like operating systems (distros)
- Not in scope for Repology: https://github.com/repology/repology/issues/494
- Early, very incomplete attempt: https://github.com/waldyrious/unix-manifests
- Instances of Linux distros: https://w.wiki/LJD
Listeria
[edit]Try replacing the table at pt:Prémio Camões#Premiados with Listeria, based on a query like this: https://w.wiki/LJB
Lexemes
[edit]See also Useful stuff § Lexemes below, for general information about these.
- Add list of EN-PT false friends (false friend (Q202961)), and link them using false friend (P5976)
- Add lexemes at the top of Wikidata:Lexicographical coverage/pt/Missing
Fonts and characters
[edit]- typeface (Q17451) ← typeface/font used (P2739)
- font (Q4868296)
- type foundry (Q377688) ← type foundry (P4586)
- metrically compatible typeface (P4099)
- GlyphWiki ID (P5467)
- Compilation of serif fonts and their inclusion in various repositories
- TODO: Complete missing information on Wikidata based on that
- TODO: propose a property for fileformat.info character pages, like this (and also their file format pages, while we're at it; they are already linked to from various items as "described at URL").
- Individual letters should be modeled by an abstract grapheme item with additional items for specific characters linked as representations thereof.
- For example:
- ć (Q87497006)facet of (P1269)Ć (Q14667)
- ﹫ (Q87544199)facet of (P1269)@ (Q10714)
- Maybe also use for symbols variants like text/emoji representations, gender variations or skin tones?
- Unicode character (P487) should only be used in the individual characters, not the abstract grapheme (I've seen it modeled as Č (Q14662)Unicode character (P487)Č
applies to part (P518)uppercase letter (Q98912), but that's redundant and unnormalized. - The link could be manifestation of (P1557) too, not sure which one is more appropriate.
- What would be the appropriate reverse property?
- The abstract grapheme should have IPA transcription (P898) and pronunciation audio (P443) properties, possibly qualified with language of work or name (P407) if needed.
- For the audio files, see c:Category:Audio files of phonetic samples, w:Help:IPA, w:Template:IPA charts and audio
- Besides the templates listed at w:Template:IPA charts and audio, there appear to be three duplicates: w:Template:IPA affricates/audiotable, w:Template:IPA co-articulated consonants/audiotable and w:Template:IPA non-pulmonic consonants/audiotable — I've asked about the duplication here.
- For the audio files, see c:Category:Audio files of phonetic samples, w:Help:IPA, w:Template:IPA charts and audio
- For example:
Useful stuff
[edit]Assorted useful stuff
[edit]- Wikidata:Tools
- wikidata-edit: Edit Wikidata from NodeJS
- wikidata-cli: A command-line interface for Wikidata
- Wikidata:List of properties and the pages linked from it
- For example, see the tables at Wikidata:List of properties/number of entities (populated by entries that are instances of Wikidata property for quantities (Q52513243))
- Note: these pages updated by a bot, based on the "instance of" statements in the properties. So it's a good idea to add those statements to properties (similar to categories), and link properties via "related property" statements (similar to "see also" links). This allows navigating the existing properties and discovering potentially useful properties. It's also useful to add aliases (similar to redirects) and even create more specific Wikidata items to categorize properties more accurately in case the existing/available "instance of" entities are too broad or apply to many properties that could be grouped further. I did this, for example, by creating Wikidata property for number of people (Q111974592) as a subclass of Wikidata property for quantities (Q52513243) and of Wikidata property associated with people (Q64830420)
- Tools for browsing/searching properties
- Wikidata Propbrowse
- Wikidata Property Explorer (source code repository) — essentially an interactive representation of the pages under Wikidata:List of properties?
- SQID's property browser
- Wikidata:Property proposal
- For example, see the tables at Wikidata:List of properties/number of entities (populated by entries that are instances of Wikidata property for quantities (Q52513243))
- languages to skip on wikidata game:
zh,ja,ru,uk,hu,ko,pl,tr,et,el,ar,bg,vi
- languages to prefer on wikidata game:
pt,gl,es,it,ro,fr
- Useful templates
- link to an item given one of its sitelinks:
{{Item}}(there's no option for "item by label", since multiple items with the same label can't be automatically disambiguated) - link to an item given its ID:
{{LinkedLabel|Q1}}→ Universe - statement (full or partial semantic triple):
{{statement||P31|Q5}}→ instance of (P31)human (Q5) - graphical statement display, emulating Wikidata's interface:
{{Statement+| P={{P-|27}} |V={{Q-|145}} }}- Use qp/qv to add a qualifier property and value, and rp/rv to add a reference property and value, as demonstrated here.
- block query:
{{SPARQL|query = ...}} - inline query:
{{SPARQL Inline|label = foobar|query = ...}}→ foobar (query)
- link to an item given one of its sitelinks:
- Wikidata Diff: compare two entries (example: Portugal vs. Cape Verde)
- Doesn't work with more than two entries :(
- Perhaps there should be a way to filter out external identifiers (which by definition are going to be all different anyway)
- Graph relationship between items / shortest path between two items
- Wikidata Graph Builder
- Wikitree (mostly for family trees, but not just that)
- EntiTree (defaults to family tree, but has many —hardcoded— properties to build graphs from)
- All of these require the user to provide the property. None of them discovers the best connection. I'd like one that would find the shortest path between two items (sort of playing the Getting to Philosophy game, but on Wikidata).
- Xefer's tool and Six Degrees of Wikipedia sort of do this, but using links in the text of the Wikipedia articles, rather than explicit relationships in Wikidata.
- I've suggested this feature to EntiTree in this tweet.
- More entries may be added to Wikidata:Tools/Visualize data or Wikidata:Tools/Query data later
- Narrowing down search results: <translate> To search for Wikidata items by their title on a given site, use Special:ItemByTitle.</translate>
- Cradle
- Forms to create Wikidata items by filling all the relevant properties given the type of entity
- Presets are listed at Wikidata:Cradle (like the query examples, this is a shared list that everyone uses)
- Similar to QuickSettings, but has two major differences
- It is used to create new items, rather than edit existing items
- There's no way to create custom presets, so the full shared list is a little noisy, with e.g. multiple forms for the same kind of entity depending on what properties one wants to fill in
- Feedback
- It should be possible to create multiple items at once, e.g. a book as a work, its edition(s), and its author(s)
- It should be possible to load custom presets, not just those from Wikidata:Cradle
- The presets should allow a description field besides just the name
- The presents should allow usage of the
{{P}}template to make the page more readable - Optional fields should be collapsed under a "more" section, to make the forms less overwhelming
- The
+icons should stay in place, rather than be to the left of the-icon when multiple items are added - The form should not be fillable if one's not logged in, since logging in loses all input 😱
{{Instances of}}
- According to Special:MyLanguageFallbackChain, the languages that appear in item pages are determined by the contents of the
{{#babel}}box in the userpage.
- TODO: Figure out how to use Quarry
- Wikidata:Quarry
- mw:Wikibase/Schema (database schema)
- Wikibase: Item & Property Terms
- Alternatives to of (P642): Wikidata:WikiProject Data Quality/Issues/P642#Use cases by property being qualified
Data model
[edit]- Wikidata:Glossary
- Help:Basic membership properties — mentions instance of (P31), subclass of (P279) and part of (P361) (and the latter's inverses, has part(s) (P527) and has part(s) of the class (P2670))
- Perhaps it should include facet of (P1269) as well. Proposed here.
- Shouldn't member of (P463) have an inverse, similar to part of (P361) <--> has part(s) (P527)?
- Wikibase/DataModel/Primer
- Help:Modelling/General
- Help:About data § Modeling data
- Wikidata:Data model
- Wikidata datatype demonstration (Q115569934) — item containing sample statements to demontrate all supported data types
Modeling specific topics
[edit]EntitySchemas
[edit]- Can be used to define the expected statements (and their values) of an item of a given type (e.g. humans should have a given name, a gender with specific values, etc.). This is done using uses the Shape Expressions (ShEx) syntax.
- Reference links
- Wikidata:Schemas
- Wikidata:WikiProject Schemas
- Wikidata:Database reports/EntitySchema directory
- Shape Expressions workboard on Phabricator
- Let's write a schema together: slides from Data Modelling Days 2023 — lots of useful info (for future reference) but a bit overwhelming to consume standalone.
- Tools to work with schemas
- Shape Designer — GUI to create schemas (similar to the visual query builder)
- Wikidata Shape Expressions Inference — infer schemas from a set of items
- User:Teester/CheckShex.js — allows selecting an EntitySchema and validating the current item against the schema directly from the Wikidata interface
- Idea: tool to locate similar schemas and merge/consolidate them
Model items
[edit]- Wikidata:Model items
- List of items with model item (P5869) property
Property constraints
[edit]- Property constraints are scoped to a property, so they have to be broad/generic, and can't offer nuanced recommendations depending the type of item (e.g. a different constraint for a human and a country)
- Entity Schemas and model items, on the other hand, pertain to items as a whole, so they provide restrictions/recommendations as cohesive sets, and are more and won't apply to items that don't match that schema).
- Both property constraints and EntitySchemas are amenable to mechanical application/validation, whereas Model items require manual lookup and application.
- Property constraints are much easier to edit and are well integrated with the Wikidata interface than EntitySchemas, though that could change in the future
WikiProjects
[edit]- Many Wikiprojects have lists of properties that can be applies to items in the subject areas they cover. They can also have explicit recommendations about which properties are mandatory, recommended or ancillary.
- TODO: Add some examples
Recoin
[edit]OpenRefine
[edit]- Wikidata:Tools/OpenRefine
- Now accessible via the browser (since may 2021), without installing anything!
- The URL is user-specific; this dynamic link will point to it: https://hub-paws.wmcloud.org/hub/user-redirect/openrefine
- Watch the tutorial videos and take notes on ideas for using it
TABernacle
[edit]- TABernacle: provide a list of items for the rows, and a list of properties for the columns; the tool fills up the matrix and helps identify missing data, and add it directly.
- There are short descriptions at Wikidata:Tools/Query data and the Tools directory
- The help page at Help:TABernacle is very sparse, but Wikidata:TABernacle has more detail
- Issues / needed improvements:
- No way to sort the table columns (e.g. to locate empty cells)
- Tracked as issue #15
- No way to sort the table columns (e.g. to locate empty cells)
SPARQL queries
[edit]Query building interfaces
[edit]- Wikidata Query Service
- Wikidata Query Builder
- Based on Wikidata Query Builder (2017 prototype, no longer updated)
- Previously called "Simple Query Builder", in relation to the 2017 prototype
- VizQuery less visually polished; no options for sorting the results or which properties to show
Notes:
- Neither VizQuery nor Wikidata Query Builder allow combining conditions with
OR - Neither VizQuery nor Wikidata Query Builder allow specifying non-property conditions (number of sitelinks, label/description, ...)
See also User:SpinachBot (more info below)
REST endpoint
[edit]- DataModel/JSON
- GitHub: wikimedia/wikidata-query-rdf: docs/exploring-linked-data.md
- SPARQL REST endpoint
- Special:EntityData
- API
- Example (get only the claims): https://www.wikidata.org/w/api.php?action=wbgetentities&props=claims&ids=Q42&languages=en&format=json
- Supported values for the
propsparameter:info,labels,descriptions,aliases,sitelinks,claims,datatype. Multiple values can be provided, separated with|.
Documentation
[edit]Introduction / general reference
[edit]- Visual demonstration of how to build queries using the autocompletion feature: Wikidata:SPARQL query service/A gentle introduction to the Wikidata Query Service#Text to SPARQL walkthrough
- Wikidata Query Service Tutorial
- Wikidata:SPARQL tutorial (see below for extracts)
- Complete syntax reference: SPARQL 1.1 Query Language
- Wikibook: SPARQL
- Optimization tips: Wikidata:SPARQL query service/query optimization
- Example of query that was optimized to split out the label service calls: https://w.wiki/6dfX → https://w.wiki/6dfb
Prefixes
[edit]- General reference
- Prefixes (
wd:,wdt:, etc.) are used to qualify elements of a query (operators and operands) depending on their type (e.g. item, property, value, etc.) - About prefixes
- Full list
- Prefixes (
- List of prefixes
wd= Wikidata entity (e.g. ___)wds= Wikidata statement (e.g. ___)wdv= Wikidata value (e.g. ___)wdt= Wikidata property (equivalent top+psas shown below)- "p: links to a statement node which has various things (the main value, rank, qualifiers, etc), you'll need to use p:P123/ps:P123 to get the value. wdt: is simpler to use if it does what you want (return just the main value of preferred rank statements if they exist, otherwise of normal rank ones), but for anything else it has to be p: and ps:" (Nikki in the Wikidata group on Telegram, 21 June 2023)
p= a property statement (e.g.?item p:P123 ?prop.)ps= prop/statement/ — the value of a property statement (e.g.?item p:P123 ?prop. ?prop ps:P123 ?propValue.)psv= prop/statement/value/ — the numeric value of a property as written in the statement (i.e. disregarding the unit)psn= prop/statement/value-normalized/ — the numeric value of a property, normalized to the base unit of the measured quantity.
pq= prop/qualifier/ — a qualifier for a property statement (e.g.?item p:P123 ?prop. ?prop pq:P456 ?propQualifier.)pqv= prop/qualifier/value/ — ?
pr= prop/reference/ — ?prv= prop/reference/value/ — ?
- TODO: add examples above where missing
Query syntax cheatsheet
[edit]Condensed/edited from the excellent —but awfully verbose— Wikidata:SPARQL tutorial)
- The core structure of any query is a semantic triple (subject, predicate, object).
The "predicate" represents the relationship between subject and object, so I'll call it "relation" to make this clearer:?subject wdt:relation wd:object.
- The object of one triple can be the subject of another triple, which allows building more complex queries:
?nephew wdt:child ?father. ?father wdt:brother wd:uncle.- There are also two shorthands for this:
?nephew wdt:child/wdt:brother wd:uncle.— using the path separator character/to chain predicates together, creating a "property path" from the subject to the object.?nephew wdt:child [ wdt:brother wd:uncle ].— using[]to nest a partial triple, where the omitted part is the missing piece in the outer triple.
- Use
,to append another object to the previous triple, reusing both the subject and the predicate:?subject wdt:relation wd:object1, wd:object2.
- Use
;to append a predicate-object to the previous triple's subject:?subject wdt:relation1 wd:object1;wdt:relation2 wd:object2.
- Predicates can be combined using regex-like syntax:
- Use the regex-like quantifiers
*,+and?to represent how many times a predicate appears in the query:?descendant wdt:child+ ?ancestor.
- The two constructs above are commonly used to specify the notion "instance of X or of any subclass of X":
?subject wdt:P31/wdt:P279* ?object.
- As in regex,
()groups expressions. - As in regex,
|means OR:?itemA wdt:relation1|wdt:relation2 wd:itemB.- Note that this is not an OR for entire triples, but for parts thereof!
- Parenthesis may be needed to mark the limits of the OR expression:
?itemA (wdt:prop1|wdt:prop2)/wdt:prop3 wd:itemB.- Note: for OR-ing entire "sentences", wrap them in curly brackets and use the
UNIONoperator between the two blocks.
- Note: for OR-ing entire "sentences", wrap them in curly brackets and use the
- Use the regex-like quantifiers
- Sorting results
- Add
ORDER BY ?fooBarafter the closing}of theSELECTstatement
- Add
- Negative assertions
MINUS { ?item wdt:P3999 ?closure_date }FILTER NOT EXISTS { ?item wdt:P3999 ?closure_date }- Both of the above work... not sure if one is preferable over the other.
- Remove specific items
FILTER(?item != wd:Q12345)for a single itemFILTER(?item NOT IN (wd:Q123,wd:Q456,wd:Q789))for multiple items
- Optional assertions
OPTIONAL { ?city wdt:P1082 ?population. }
- More useful info: https://www.slideshare.net/LeeFeigenbaum/sparql-cheat-sheet
UNION/MINUS(slide 8)- literal values (strings, numbers, ...)
- comparison operators (
!,&&,||,<,=,!=, ...) - more predicate path operators (
^,!, ...) - underspecified triples (e.g. two or even 3 variables)
- Wikidata-specific helpers
- label and description
- Include
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". } - For a variable
?foorepresenting an item, that automatically binds its label to?fooLabel, and its description to?fooDescription - To add custom names for the label variables (other than ?fooLabel), use
rdfs:label:SERVICE wikibase:label {
bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en".
?variableName rdfs:label ?customLabel .
}
- Include
- Associated Wikipedia article ("sitelink")
?sitelink schema:isPartOf <https://pt.wikipedia.org/>; schema:about ?item.
- lexeme representations (lemmas)
?item wikibase:lemma ?lemma.- Filter lemmas by plain string matching:
FILTER (str(?lemma) = "foobar") - Filter lemmas by regex matching:
FILTER (regex(?lemma, '^foobar$'))
- label and description
Example queries
[edit]- Using the UNION operator: https://w.wiki/3Txr (organizations and communities of which Cape Verde (Q1011) is part)
- Using the FILTER operator and custom names for the label variables: https://w.wiki/44h (items that are the object in a "father" triplet, but have gender != male)
- Items whose label (in the language(s) specified in the
wikibase:labelservice command) match a given pattern: TODO - Instances of X sorted by number of statements and sitelinks (https://w.wiki/44e)
- Useful to find good representatives as a showcase
- Something like https://w.wiki/44c ought to work for the statement count query, but the number of statements seems quite off, not sure why. Maybe I'd need a nested query for that to work.
- Items with a given qualifier in a given property: https://w.wiki/X6s
- Chain of located in the administrative territorial entity (P131), all the way to a country (P17):
?item wdt:P131*/wdt:P17 ?country - Remove duplicates (show only unique items):
SELECT DISTINCT ... - Filtering by number of values in a given property (e.g. persons with double nationality, articles with a single author, etc.)
- List of all statements (property/value pair, including qualifiers) of an item (thanks to Santhosh.thottingal): https://w.wiki/9XTp
Written works
[edit]books, scholarly/academic/scientific publications (papers, reports, theses/dissertations), etc.
- Wikidata:WikiProject Source MetaData#Projects
- Scholia, for searching data already on Wikidata
- Source Metadata, for creating/importing individual scholarly articles (e.g. by DOI)
- Get DOIs from title at Crossref Metadata Search
- Wikipage with more info: Wikidata:SourceMD
- See also ORCIDator
- Search Google Scholar author profiles: <search terms> site:scholar.google.com/citations
- Mix'n'match, for linking Wikidata items with identifiers in external catalogs
- Resolve authors (search by name, with fuzzy match option; can create Wikidata item from ORCID)
- Distributed game #9: identify authors in publications
- meta:WikiCite/Shared Citations is a proposal for a new Wikimedia project that hosts metadata for reference works in a structured, reusable and machine-readable way.
- Standard format for descriptions of instance of (P31)scholarly article (Q13442814) with author (P50) or author name string (P2093)
- One author:
scholarly article by <First Last> published in [<month>] <year> - Two authors:
scholarly article by <F. Last1> and <F. Last2> published in [<month>] <year> - Three authors:
scholarly article by <F. Last1>, <F. Last2> and <F. Last3> published in [<month>] <year> - Four or more authors:
scholarly article by <First1 Last1> et al. published in [<month>] <year> - With journal name:
[<month>] <year> scientific article by <author(s)> published in <publication> - TODO: generate a query to get instances of scholarly article (Q13442814) with no description, or description = "scholarly article", but with author and year of publication, and use it to build a QuickStatements batch to fill the English description using the appropriate format above.
- Start by those with a single author (based on this perhaps?) and no author name string (P2093) property
- WIP query
- One author:
Items of personal interest
[edit]Authors
[edit]- Luís Paulo Santos (Q43411442)
- David Pinto (Q48192056)
- Luis Unzueta (Q50810545)
- Kieran Larkin (Q52407619)
- Rik ter Horst (Q109325951)
- Author of the solid Schmidt–Cassegrain telescope (Q109328432)
- The telescope might warrant its own item, and should eventually be mentioned in w:Schmidt–Cassegrain telescope#Derivative designs and w:List of telescope types, and possibly w:History of the telescope too.
- Why is this Space Telescope so Tiny? (YouTube video)
- The monolithic telescope concept from Rik ter Horst presented by Huygens Optics (Reddit thread in r/telescopes about the video above)
- A SOLID 30 mm F/10 Schmidt Cassegrain (original forum post about the concept by the author, in 2013)
- Author says the first inception was made in 1998
- One of the commenters said: «This is a variation of the "Solid Cat" Vivitar 800mm f/11 which used the same principle, except a larger scale», to which the author responded: «the optical configuration of the Vivitar consists of several (bonded) components with different refractive indices and with some air gaps. For comparison [my] Solid SCT [...] is made from just one piece of BK7, no bonding whatsoever...»
Publications
[edit]- Towards a linear algebra of programming (Q50292399)
- Efficient generic face model fitting to images and videos (Q50810415)
Books
[edit]Useful links
[edit]- Wikidata:WikiProject Books § Bibliographic properties
- Template:Book properties (exhaustive list, no editing guidance)
- Wikidata:WikiProject Periodicals
- User:Marianika/Historical Bibliographic Data#Documentation
Creating new books
[edit]- Check the Wikidata section below for properties
- Ideally there should be an interface to create, at once, all items related to a book (the work, edition and author items), all with the appropriate connections, with a good autocomplete system, and able to import public data given e.g. an ISBN.
- For now, we can use the Cradle forms for book (work), book (edition) and author
- There's a strict book edition preset, but requires authors to exist first (it doesn't accept author name string (P2093), nor empty author fields); the flexible preset, linked above, accepts both, and also has a field for Google Books ID.
Data models
[edit]- Re-thinking Open Library’s Book Pages
- Explains very well the intricacies of distinguishing between a book as a work with multiple representations, a specific edition of a book, physical instances of books, etc.
- Slightly edited quote: To simplify the experience for readers, we released a new type of Book Page which combines the affordances of the Work and Edition Pages into a single view. Two pages become one: By default, the Book Page attempts to automatically feature the “best” (previewable, available) edition of a book and places an editions table front-and-center to enable readers to quickly switch which edition is selected.
- Wikidata's model is based on this
- From What is FRBR? A conceptual model for the bibliographic universe, quoted in b:Introduction to Library and Information Science/Information Organization#Cataloging:
- When we say the word book in everyday language, we may actually mean several things.
- For example, when we say book to describe a physical object that has paper pages and a binding and can sometimes be used to prop open a door or hold up a table leg, FRBR calls this an "item."
- When we say book we also may mean a "publication" as when we go to a bookstore to purchase a book. We may know its ISBN but the particular copy does not matter as long as it's in good condition and not missing pages. FRBR calls this a "manifestation."
- When we say book as in "who translated that book," we may have a particular text in mind and a specific language. FRBR calls this an "expression."
- This is the most confusing aspect to me. It may help to think of different versions of a work by the same author as it evolves in time (draft/manuscript, first edition, revised edition, etc.) as different expressions of the work; and similarly, a translation is a separate expression, authored by the translator. But, as hinted in v:pt:Transcrição digital#Definição formal, a transcription (e.g. from a manuscript to a printed book) transforms one manifestation in another, but preserves the expression.
- When we say book as in "who wrote that book," we could mean a higher level of abstraction, the conceptual content that underlies all of the linguistic versions, the story being told in the book, the ideas in a person's head for the book. FRBR calls this a "work."
- Diagram:


- Meant to replace MARC
- Diagram:

- (MARC, UNIMARC, MARC 21...
IFLA Library Reference Model (Q54410458) (IFLA-LRM)
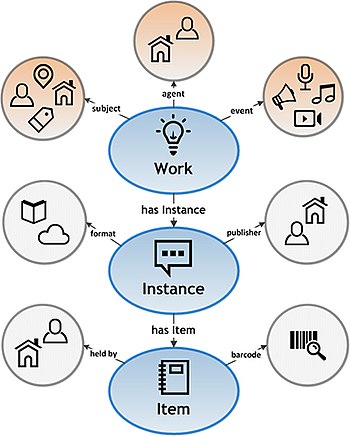
[edit]- Diagram:

(Probably a simplified diagram would be helpful, containing just the work/expression/manifestation/item chain, plus the agent box (with an indication that this could be a single person or a collective.)

- They seem to focus on three main levels of the "book" concept:
- works, i.e. written work (Q47461344) (example)
- instances/manifestations, i.e. version, edition or translation (Q3331189) (example)
- They actually store this information separately from Wikidata, due to the inconsistency in how books are modeled in Wikidata (as of Nov 2022, there are +100K instances of version, edition or translation (Q3331189) without a edition or translation of (P629) property)
- items, i.e. individual copy of a book (Q53731850) (example)
- They don't actually encode this in Wikidata, because the individual copies of books owned by users of the platform are almost certainly not notable enough to have their individual item on Wikidata.
- Glossary § Concepts
- Guides § Entities
- Diagram (old):

- Diagram (new - source):

- Railroad diagram:




{kind=link}
{kind=link}
.svg){kind=link}
{kind=link}
{kind=link}
- Glossary
- Getting started — describes the data model composed of the following elements:
- Author
- Work
- Edition
- Edition group (e.g. paperback, hardcover, e-book)
- Publisher
- Series (sequential grouping of works)
- Allows creating private or public collections
- In this sense, it's similar to Inventaire, although the latter tries to rely more on Wikidata
- instance of (P31)written work (Q47461344) (not instance of (P31)book (Q571)? How does that play with individual copy of a book (Q53731850)?)
- author (P50)
- For compilation works: contributor to the creative work or subject (P767) and editor (P98)
- No author (P50)?
- How does one note contributors that don't have dedicated items, i.e. equivalent of author name string (P2093)?
- For compilation works: contributor to the creative work or subject (P767) and editor (P98)
- title (P1476)
- subtitle (P1680)
- language of work or name (P407)
- inception (P571)
- has edition or translation (P747)
- main subject (P921)
- form of creative work (P7937) (novel, poem, comic book, etc.)
- genre (P136) (mostly for fiction? science fiction, fantasy, romance, adventure, drama...)
- Identifiers
- ...more
- author (P50)
- instance of (P31)version, edition or translation (Q3331189)
- edition or translation of (P629)
- translator (P655)
- edition number (P393)
- publisher (P123)
- publication date (P577)
- height (P2048)
- width (P2049)
- number of pages (P1104)
- illustrator (P110)
- cover art by (P736)
- distribution format (P437) (paperback, hardcover, ...)
- Identifiers
- ISBN-13 (P212)
- Google Books ID (P675)
- Wikisource index page URL (P1957)
- Open Library ID (P648)
- OCLC control number (P243)
- Amazon Standard Identification Number (P5749) (TODO: check if this indeed is meant for editions only)
- ...more
- instance of (P31)individual copy of a book (Q53731850)
- exemplar of (P1574) (target should be version, edition or translation (Q3331189), but the constraints on the property are much laxer ☹️)
- location (P276) (sometimes edition or translation of (P629) is used instead)
- owned by (P127)
- condition / preservation status? (intact, missing pages, water damage, annotated...)
- significant event (P793) (destruction (Q17781833), acquisition (Q22340494), change of ownership (Q14903979), restoration (Q107036510)...)
- collection (P195)
- donated by (P1028)
- ...more
- TABernacle list of such items
- From Wikidata talk:WikiProject Books/2013#First of all, a definition for Book entity: the relationship between works and book is (unluckily) many-to-many. Having a list of works, they are collected into many kind of books: single work books, collections of many works into a single book, or a single work can be published in different books.
QuickStatements reference
[edit]- Help:QuickStatements
- QuickStatements v1 (deprecated)
- QuickStatements v2 (recommended)
- Can import commands in the v1 format
- The CSV format is pretty straightforward (and actually easier to author than v1):
- cells are comma-separated instead of tab-separated
- there's a header row, which allows avoiding the repetition of the same prefixes in every row (thus halving the number of fields per row)
- Queries in the query service can be tweaked to produce near-ready QuickStatement commands; see e.g. these steps to remove the "NAME" prefix from the label of exoplanets).
- The batch mode ("run in background") doesn't seem too reliable; I got some errors, but then wasn't able to see what they were
- Update Nov 2021: still getting some "no API success flag set" errors. Better just stick to the sequential mode.
Examples
[edit]Example 1 → RescueTime (Q34637733): software version identifier (P348) = "2.12.5.1503"; publication date (P577) = +2017-06-09T00:00:00Z/11; platform (P400) = Microsoft Windows (Q1406); version type (P548) = stable version (Q2804309) (others listed here); reference URL (P854) = "https://www.rescuetime.com/updates/win_release_notes.html"; title (P1476) = "RescueTime for Windows Release Notes" (English).
Q34637733 P348 "2.12.5.1503" P577 +2017-06-09T00:00:00Z/11 P400 Q1406 P548 Q2804309 S854 "https://www.rescuetime.com/updates/win_release_notes.html" S1476 en:"RescueTime for Windows Release Notes"
Simplified template:
<item> P348 "<version number>" P577 +<date>T00:00:00Z/11 S854 "<url>" S1476 en:"<title>"
Observations:
- Note how source (reference) properties must be provided using the nonstandard "S" prefix — so "S854" instead of "P854".
- Note that the whitespace characters are tabs, not spaces
- Note that timestamps must have zero time
- Note that the reference title requires a language specifier, here indicated by the
en:prefix.
Example 2 → (TODO: human-readable translation)
CREATE LAST Len "Buying Lumber" LAST Den "song from the sountrack of the 2000 game The Sims" LAST P361 Q7764364 P1545 "4" P2047 306U11574 LAST P31 Q217199 LAST P86 Q943225 CREATE LAST Len "Mall Rat" LAST Den "song from the sountrack of the 2000 game The Sims" LAST P361 Q7764364 P1545 "5" P2047 164U11574 LAST P31 Q217199 LAST P86 Q943225
Observations:
- Note the usage of CREATE and LAST directives, since we're creating new items, rather than adding statements to an existing item
- Note the Len and Den, for the English label and description
- Note now each line can only contain a single statement triplet, but a given statement (e.g. part of (P361)) can have any number of properties/qualifiers.
- Note now the duration (P2047) is provided as seconds which are marked U11574, when in reality the item is second (Q11574).
- Note how the number for series ordinal (P1545) is provided as a string, even though a plain number should work as a quantity, according to the docs ("unit is optional")
Example 3 → (TODO: human-readable translation)
Q2986828 P348 "CLDR 30.0.1" S854 "http://cldr.unicode.org/index/downloads/cldr-30#TOC-CLDR-30.0.1-Maintenance-Release" S1476 en:"CLDR 30 Release Note" S958 "CLDR 30.0.1 Maintenance Release"
Example 4 → (TODO: human-readable translation)
Q839063 P1324 "http://git.savannah.gnu.org/cgit/oddmuse.git/" P8423 Q186055
Example 4 → Add software versions, release dates and reference URLs
qid,P348,qal577,S854 Q109462071,"""v0.0.3""",+2020-05-17T00:00:00Z/11,"""https://github.com/bigskysoftware/htmx/releases/tag/v0.0.3""" Q109462071,"""v0.0.4""",+2020-05-26T00:00:00Z/11,"""https://github.com/bigskysoftware/htmx/releases/tag/v0.0.4""" Q109462071,"""v0.0.5""",+2020-06-19T00:00:00Z/11,"""https://github.com/bigskysoftware/htmx/releases/tag/v0.0.5"""
Observations:
- Note the usage of triple quotes for string values
- Note the same clunky v1 syntax for dates
- Other than that, this is actually quite an improvement: less repetition, and no reliance on tabs
Lexemes
[edit]See also To do § Lexemes above, for tasks related to lexemes.
- Template:Lexicographical properties
- Wikidata:Lexicographical data/Documentation#Data Model
- commons:Category:Lexeme presentations in English
- Lexeme examples
- Wikidata:Lexicographical data/Best practices
- Wikidata:Lexicographical data/Documentation/Languages (en, fr, es, pt, gl, kea)
- List of lexemes
- Links to "Portuguese" (Q5146) in the Lexeme namespace (hack to get an approximation of all lexemes in Portuguese)
- All lexemes in Portuguese (Q5146) (query)
FAQ
[edit]TODO: Create a quickstart / FAQ / examples page in Wikidata:Lexicographical data. See also Wikidata:Lexicographical data/Glossary (which isn't linked from the main page, for some reason)
- What are lexemes?
- words, phrases/expressions, prefixes, acronyms, etc.
- Wikidata vs. Wiktionary
- User:Rua/Wikidata for Wiktionarians
- In Wiktionary each page contains all homographs of a word, with sections for each language, and subsections for each lexical category (verb, noun, etc.)
- In Wikidata, each Lexeme page contains the homographs that share the same spelling+language+grammatical class (verb, noun, etc.)
- The same Wikidata Lexeme page groups the different forms in the same word — e.g. "houses" is represented as a form in the house (noun) lexeme
- Words that are spelled the same but belong to different languages are placed in different Lexeme pages. These homographs in other languages can be connected via homograph lexeme (P5402)
- Additionally, there can be the same word spelled in alternative ways (e.g. loiça/louça). These can be connected via alternative form (P8530) (or probably synonym (P5973), for those that aren't similar, e.g. cruzeta/cabide)
- Lexemes (L...) vs. items (Q...)
- A lexeme has statements that describe the word
- An item has statements that describe the concept
- noun-type lexemes link to items via the item for this sense (P5137) property; verb-type lexemes link to items via the predicate for (P9970) property
- Senses and forms
- Each sense represents a meaning of the word — e.g. "screen" (noun) as a display, and "screen" (noun) as a net
- A sense can therefore be linked to an item, via item for this sense (P5137)
- Senses can also be linked to the same sense in other languages, via translation (P5972)
- Each form represents variations (inflections and declensions) of the same word — e.g. house/houses, go/going/gone, pequeno/pequena/pequenos/pequenas, etc.
- Both senses and forms can have statements assigned to them, describing their properties
- e.g. statements for a form: the gender, number, tense, pronunciation, etc.
- e.g. statenents for a sense: item for this sense (P5137), translation (P5972), synonym (P5973), antonym (P5974), image (P18), usage example (P5831), location of sense usage (P6084) etc.
- Each sense represents a meaning of the word — e.g. "screen" (noun) as a display, and "screen" (noun) as a net
- Spelling variations
- A lexeme can have different representations in different spelling variants (e.g. color vs. colour in en-us and en-gb).
- These spelling variants need to have an official language code assigned, so thinks like Sampadjudu (Q2217638) and Sal Creole (Q18707467) can't be used.
- A poor man's spelling variant can be done with separate lexemes connected via alternative form (P8530) (in the Forms section of the lexeme)
Tools
[edit]- Tools
- https://tools.wmflabs.org/lexeme-forms — Create new lexemes from scratch, using templates specific to a language-lexical category combination
- Templates can be created like this: https://tools.wmflabs.org/lexeme-forms/template/spanish-noun-masculine/
- https://tools.wmflabs.org/lexeme-forms — Create new lexemes from scratch, using templates specific to a language-lexical category combination
- Wikidata:Lexicographical data/Ideas of tools
- How can Wiktionary be converted?
- There could be a Mix'n'match-like tool that imports and converts data but waits for human confirmation
Data model
[edit]- Lexeme
- Top level
- Lemma
- e.g. "run"
- Language
- e.g. English (Q1860)
- Lexical category
- e.g. adjective (Q34698)
- Statements (properties of the lexeme that are not specific to a Form or Sense). E.g. derived from, region, period, homonym, etc.
- Lemma
- Forms (i.e. inflections)
- string representations of variants per gender, number, conjugation, etc.
- one for each combination, tagged with the relevant qualifiers/properties (e.g. 2nd person, singular, past tense...)
- Representation
- Grammatical features
- e.g. (TODO)
- Senses
- string representations different meanings
- link to items for the actual concepts (see "lexemes vs. items" above)
- e.g. the lexeme "bank" (English noun) would have the senses "financial institution" and "edge of a body of water"
- Gloss
- Top level
Diagrams:


Also:
- Etymology (derived from lexeme (P5191), combines lexemes (P5238)...)
- Translations
- Pronunciation (IPA transcription (P898), pronunciation audio (P443))
Problems
[edit]- The creation form shows a "language variant" field when the entered language is not recognized.
- See Help:Monolingual text languages and the tracking ticket phab:T144272.
- For some reason the list of languages is restricted to the one approved by the Language committee for new Wikipedias, rather than e.g. the full list of languages from CLDR
- To request a language to be supported, a new Phabricator task needs to be created in the same model as one of the child tasks of the one linked above
- As a workaround, new lexemes can still be created by using the
misas described in the help page linked above. - For Kabuverdianu, the code is actually already available/linked (since phab:T127435), but the extra field was appearing nonetheless in the creation form; possibly that was due to a "no value" value for the language code, which was just removed in this edit.
- TODO: if the problem persists, maybe a new Phabricator issue needs to be created.
- Update Jun 2021: the problem still occurs — may be related to phab:T284870?
Question-answering
[edit]Tools:
- Answering Questions using Web Data (Q42365752): website / source / overview
- The Talk Page (Q47525695): website / source / my fork
- Ask Wikidata (Q47525820): website / source / overview?
- Platypus (Q20726406): website / source / overview?
- Lucida (Q28381936) (formerly "Sirius"): website / source (archived)
- From http://sirius.clarity-lab.org/downloads/: "Sirius uses a Wikipedia knowledge database, download the database (compressed 11GB): wiki_indri_index.tar.gz
- User:SpinachBot — an LLM-based natural-language interface for SPARQL queries via exchanging messages on-wiki.
- There's also an interactive UI at at https://spinach.genie.stanford.edu/.
See also:
- w:Template:Computable knowledge
- Wikidata:WikiProject Reasoning
- Mycroft (an open source voice assistant) has a "wiki" skill
Benchmarks:
- The Voice Assistant Battle! (2017)
- Google Assistant vs Siri! (2016)
- Wolfram|Alpha: Examples by Topic
- Question Answering Benchmarks for Wikidata
Maybe there should be a completeness/coverage/parity dashboard, similar to w:Wikipedia:WikiProject Missing encyclopedic articles, that maps how much of the Wolfram Language can be modeled in terms of properties/qualifiers.
Mini-bios
[edit]Thanks to the Wikidata Game, it will be possible to move quickly to a state where we Wikidata will have all the information needed to build automated mini-bios in the form
- <label> (<place of birth, <date of birth> — <place of death>, <date of death>) was a <country of citizenship> <occupation> who <description>.
In fact, the description field for people in Wikidata should probably forgo occupation and nationality, and go straight to their claim to notability, since the former are redundant with the corresponding fields.
This proposal was originally posted here.
Related resources
[edit]- Tool:Reasonator generates automated stubs based on Wikidata info
- Extension:ArticlePlaceholder embeds data boxes for a Wikidata item directly within a wiki, under Special:AboutTopic
- Tool:AutoDesc provides auto-generated descriptions for Wikidata items; I believe it is used by Reasonator, and the user script version provides in-place content in search result pages on the wikis themselves
- MediaWiki:Gadget-autoEdit.js allows users to automatically add descriptions to Wikidata items, from a list of commonly used descriptions.