Written by:
Jose Carlos Badillo
Gabriela Martinez
- Introduction: : what is data science and why is it important?
- Amazon Web Services in the era of data science
- Data lakes and analytics on top of AWS
- Introduction to Artificial Intelligence, Machine Learning and Deep Learning
- AWS Adoption
Defining what data science is, is still a non-trivial task. One could say that this concept is related to the discipline of building smart applications that leverage the power of statistics, computer science and specific domain knowledge and produce valuable outputs from data. With regards to this, Mike Driscoll's, CEO of Metamarket, says:
"Data science, as it’s practiced, is a blend of Red-Bull-fueled hacking and espresso-inspired statistics.
But data science is not merely hacking—because when hackers finish debugging their Bash one-liners and Pig scripts, few of them care about non-Euclidean distance metrics.
And data science is not merely statistics, because when statisticians finish theorizing the perfect model, few could read a tab-delimited file into R if their job depended on it.
Data science is the civil engineering of data. Its acolytes possess a practical knowledge of tools and materials, coupled with a theoretical understanding of what’s possible".
The previous is a very illustrative definition of data science that leads us to think that in the end, data science is a science but also an art, in which the so well-known data scientists know more about statistics than a computer scientist and more about computer hacking than a statistician. See more at [1].
Approximately by 2016, the data scientist position was considered as the "sexiest" job of the 21st century. Apparently, this new role was top in many aspects: scarse, interesting and well-paid. But, why was that figure so important? and ultimately, why is the concept of data science so important? In a nutshell, data science matters because it helps us make better decisions and be more accurately prepared for the future. If we simply think about evolution, information leads to better decisions, and better decisions will make species live longer. As for a cooking recipe, a data scientist would be a chef that gathers and mix a set of previously well-known ingredients to produce new or better food.
As a consequence, data science is the extension of the scientific method applied to data in almost all fields of knowledge. From movies recommendations, fraud detection and financial risk prediction to preventive maintenance, data science has appeared to help us transform data into useful information, which in the end means increased wisdom. The following chart presents some key opportunities that data science offers to many of companies' current challenges:

Therefore, as may be expected, tech leader companies around the world have been working hard on the democratization of this concept, so that many other businesses and corporations can benefit themselves by making better decisions through data. In fact, data science is a business in which useful knowledge is sold as the most valuable product, something that most companies are willing to pay, as we are now aware of the fact that wrong decisions cost much more in the long term. See more at [3].
Amazon Web Services in the era of data science
Amazon Web Services is a whole ecosystem hosted by Amazon Inc. that offers on-demand cloud computing platforms to individuals, companies and governments through a pay-as-you-go basis. Also known as "AWS", this framework makes possible for its customers to access a variety of services in which data science utilities are included. The purpose of this brief repository is to approach the main products that AWS has disposed to perform data science, a concept that for the scope of this project will gather the following key topics:
- Data lakes.
- Data analytics and visualization.
- Artificial intelligence: machine learning and deep learning.
AWS offers a set of services that allow companies create an environment that is able to process heterogeneous data and apply machine learning or analytics on it, as shown in the following schema:

In the following sections, we will approach the different stages that the previous environment covers.
Using AWS services for analytics or machine learning, requires first having the data in a centralized repository, called lake, which is located in the AWS cloud. Building a lake, however, is a further step that can only be completed once the data coming from different sources has been moved to the cloud. Therefore, AWS offers a comprehensive set of tools to perform data movement, depending on if the data needs to be processed in real-time or in batch.
- AWS Direct Connect solution aims to establish a dedicated network connection between local premises and the AWS cloud. This connection uses the standard 802.1q VLANs and hence can be partitioned into multiple virtual interfaces, which allows the access to both public and private resources through different IPs. This solutions works as follows:

- AWS Snowball is a data transport solution for data in the scale of petabytes. According to AWS Snowball official website, "customers today use Snowball to migrate analytics data, genomics data, video libraries, image repositories, backups, and to archive part of data center shutdowns, tape replacement or application migration projects". By creating a job in the AWS Management Console, a Snowball device will be shipped to the customer address, and no code or hardware purchasing is required. The whole process works as follows:

- Similarly, AWS Snowmobile is a data transport solution built for an exabyte-scale. Each snowmobile (a 45-foot long ruggedized shipping container, pulled by a semi-trailer truck) can transfer up to 100PB, which makes easy "to move massive volumes of data to the cloud, including video libraries, image repositories, or even a complete data center migration". AWS Snowmobile requires local installation and configuration by AWS experts. After setting up the connection and the network, data can be imported into Amazon S3 or Amazon Glacier.
- Amazon Kinesis is a tool to collect, process and analyze streaming data in a real-time basis, "such as video, audio, application logs, website clickstreams, and IoT telemetry data for machine learning, analytics, and other applications". It works as follows:

-
AWS IoT Core is aanother real-time data capturing solution that focuses on Internet of Things devices data. This tool can connect billions of devices between them and also to other external endpoints or devices that use additional AWS services, such as AWS Lambda, Amazon Kinesis, Amazon S3, Amazon SageMaker, Amazon DynamoDB, Amazon CloudWatch, AWS CloudTrail, and Amazon QuickSight. Additionally, these apps can track the connected devices 100% of the time, even if they are not connected because the app "stores the latest state of a connected device so that it can be read or set at anytime, making the device appear to your applications as if it were online all the time". The logic behind this concept is as shown:
First, connect devices:
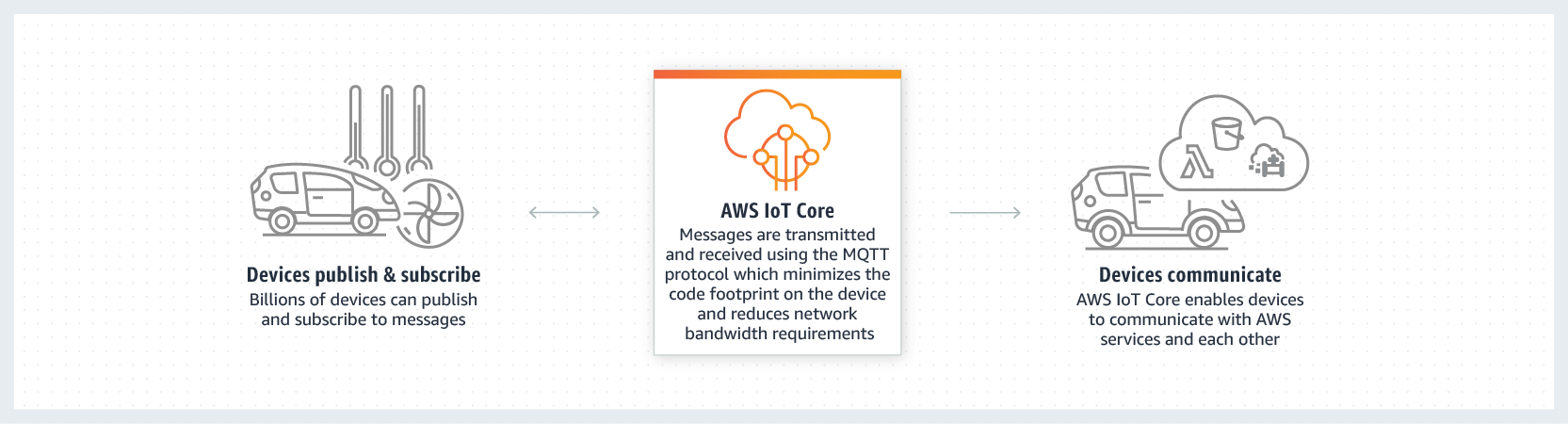
Second, secure connections and data:
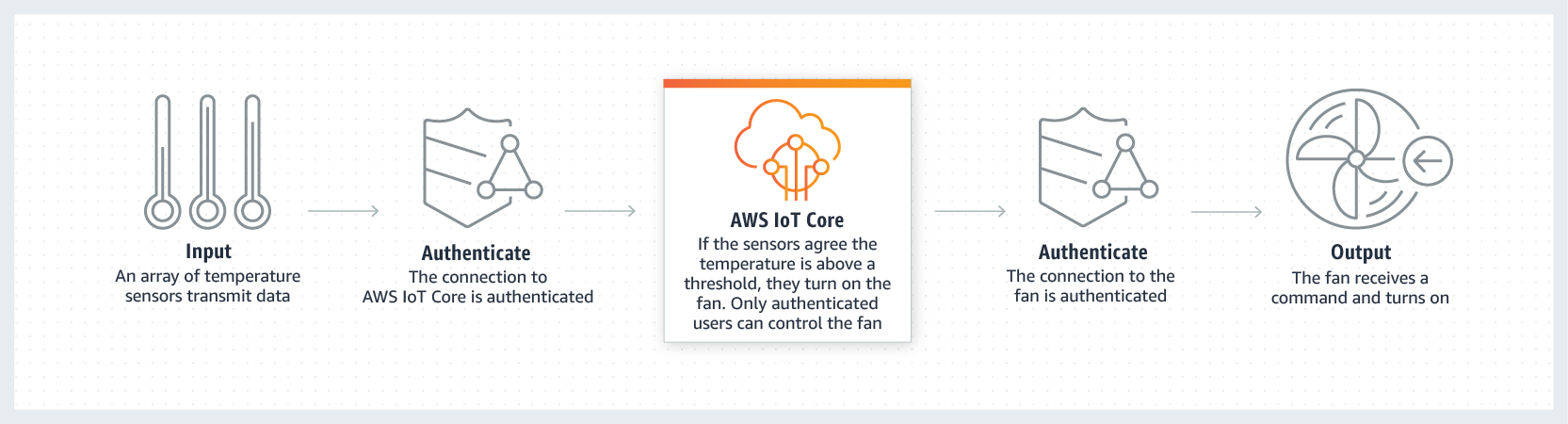
Third, process collected data according to predefined business rules:




The paradigm of having Data lakes with raw structured and unstructured data is becoming the standard within the industry, because they allow storing the data coming from a wide set of sources in its most natural form so we can build Analytic views on the top.
Some use cases within industry of data going into the lake are log files data from click-streams, social media, internet connected devices. Meanwhile the future analysis to be done from this data could answer the needs of attracting and retaining customers, improving productivity, plan appropriate maintenance, make informed decisions.
AWS offers the data lake solution that automatically configures core AWS services to generate a data lake architecture on the AWS Cloud. This solution have the following architecture:

The entry point to the data lake is done through the Amazon API Gateway which is a service that allows you to create, publish, maintain, monitor, and secure REST and Websocket APIs acting as the exposed "front doors" to access data, business logic, or functionality from the back-end services.
The AWS solution provide access to the following data lake microservices:
- Admin microservice handles administrative services including user and group management, settings, settings, API keys, and role authorization for all operations within the data lake.
- Cart microservice handles all cart operations including item lists, adding items, removing items, and generating manifests for user carts.
- Manifest microservice uploads import manifest files, which allows existing Amazon S3 content to be bulk imported into a package.
- Package microservice handles all package operations including list, add package, remove package, update package, list metadata, add metadata, update metadata, list datasets, add dataset, remove dataset, process manifest, run AWS Glue on-demand crawler, list and access AWS Glue tables, and view dataset on Amazon Athena
- Search microservice handles all search operations including query, index document, and remove indexed document.
- Profile microservice Handles all profile operations for data lake users, including get and generate secret access key.
- Logging microservice interfaces between the data lake microservices and Amazon CloudWatch Logs.
All the previous microservices use AWS Lambda as the provisioner of the back-end services that can be consumed through a CLI or through the web console deployed as part of the solution. Some advantages of AWS Lambda are: avoid the use and management of servers and the continuous scaling of the application by running each code request in parallel.
In a data lake the structure of the data or schema is not defined when data is captured. In fact, We can store data without considering design or caring about the information we must extract from this data in the future.
The AWS data lake solution stores and registers datasets and manifest files of any size in their native form in an Amazon S3 bucket. A second S3 bucket configured for static website hosting hosts the data lake console which is exposed via the Amazon CloudFront to avoid direct access through the S3 endpoint.
When we work with data lakes there is a complexity added as there is not oversight of the contents. Therefore it is important to track the metadata. The data lake solution uses Amazon DynamoDB tables to persist metadata for the data packages, settings, and user cart items. The following tables are available:
- data-lake-packages: persistent store for data package title and description, and a list of groups that can access the package.
- data-lake-metadata: persistent store for metadata tag values associated with packages.
- data-lake-datasets: persistent store for dataset pointers to Amazon S3 objects.
- data-lake-cart: persistent store for user cart items.
- data-lake-keys: persistent store for user access key ID references.
- data-lake-settings: persistent store for data lake configuration and governance settings.
Additionally this solution automatically configures an AWS Glue crawler within each data package and schedules a daily scan to keep track of the changes. The crawlers crawl through the datasets and inspect portions of them to infer a data schema and persist the output as one or more metadata tables that are defined in the AWS Glue Data Catalog.
AWS Glue is an ETL service that make easier the preparation of data for analytics. AWS Glue provides built-in classifiers to infer schemas from common files with formats that include JSON, CSV, Parquet, Apache Avro and more.
This services works very easily following 3 simple steps:
- Build your catalog: Pointing a crawler into data stored on AWS and then it discovers the data and stores the appropriate metadata in the AWS Glue Data Catalog.
- Generate and Edit Transformations: By selecting a data source and data target. AWS Glue will generate ETL code in Scala or Python to extract data from the source, transform the data to match the target schema, and load it into the target.
- Schedule and Run Your Jobs: Schedule recurring ETL jobs or chain them or invoke them on-demand.
The security on a data lake is very important because the data stored inside might be very sensitive and the access allowed to each user need to be controlled. Therefore all the dataset objects stored in AWS S3 are encrypted using the AWS KMS Key service. This security will be handled through Amazon cognito which will work as the authentication media for the different users of the data lake.
The solution uses an Amazon Elasticsearch Service cluster to index data lake package data for searching. See more at [4].
- Amazon Athena is a platform to query data stored in Amazon S3 through standard SQL, once a schema has been defined. Moreover, Athena is a serverless tool, so no infrastructure costs are associated with the use of the service and it only charges final users for the queries they run. Besides this, no ETL processes need to be defined prior to start querying data. Also, Amazon Athena is integrated with AWS Glue Data Catalog, which allows users create unified metadata repositories available across all the Amazon suite of products and also schema versioning.
- Amazon EMR provides big data processing capabilities by enabling the use of frameworks such as Spark and MapReduce and more than 19 open source projects that include Presto, Hive, HBase and Flink, which can also be connected to Amazon S3 or DynamoDB. Amazon EMR operates through notebooks based on the Jupyter interface and allows users create ad hoc queries, exploratory analysis, ETLs, machine learning, log analysis, web indexing amongst others.
- On the traditional OLAP side, data warehousing querying is also possible thanks to Amazon Redshift, the tool for building scalable data warehouses that can access petabytes of data. Moreover, according to the official documentation "Redshift delivers ten times faster performance than other data warehouses by using machine learning, massively parallel query execution, and columnar storage on high-performance disk" and additionally, it costs "less than 1/10th the cost of traditional data warehouses on-premises", with prices that start at $0.25 per hour.
- As mentioned before, Amazon Kinesis enables the collection, processing and further analysis of streaming data that includes Internet of Things telemetry data, logs generated from applications running and streams from clicks on websites.
-
Amazon Elasticsearch Service is the Amazon tool that enables the use of Elasticsearch APIs (for Java, Python, Rubi, PHP, Javascript and Node.js), Kibana and Logstash. This service is also compatible with the AWS cloud stack and can be configured in a scalable way. Elasticsearch is a highly scalable open-source search and analytics engine built on top of MongoDB that performs extremely fast searches for all types of data and big volumes almost in real-time. This source is behind the searching and indexing processes that companies such as Wikipedia and LinkedIn implement, as in general, Elasticsearch is used as the underlying search engine for complex search features in applications. Some of the advantages of Elasticsearch can be summarised as follows:
- Document-oriented: storing is made through structured Json documents in which all fields are indexed by default using the Lucene StandardAnalyzer. This results in a higher performance when searching because it offers powerful full-text search capabilities.
- Supports extremely fast full-text search through its inverted index. According to the official documentation "an inverted index consists of a list of all the unique words that appear in any document, and for each word, a list of the documents in which it appears".
- Restful API that allows querying Elasticsearch while providing a user interface.
Moreover, the Amazon Elasticsearch Service works as shown below, offering a bunch of different analytical services on top of Elasticsearch besides its main capability associated with full-text search:

- Amazon Quicksight is AWS business intelligence scalable tool that allows presenting insights up to a 10.000 users simultaneously. Through this tool, it is possible to create and publish dashboards not only with descriptive information but also with machine learning capabilities. Moreover, dashboards can be accessed from any device and can be embedded into different applications. In particular, this solution offers a Pay-per-Session pricing schema that allows giving access to everyone to the data they need, while only paying for what they use. This service works as described in the following graph:

Often abbreviated as "AI", "Artificial Intelligence (AI) is the field of computer science dedicated to solving cognitive problems commonly associated with human intelligence, such as learning, problem solving, and pattern recognition". Taken from: [5].
According to professor Pedro Domingos, a researcher of the field at University of Washington, there are five main tribes that conform the Machine Learning. One of them is related to the Bayesians, people engaged with statistics and probability that have developed the field into different real-world applications thanks to the advancements in statistical computing, the reason why we can talk about "machine learning" for advanced bayesians techniques applied into use cases.
Moreover, another tribe within the machine learning paradigm is conformed by the connectionists, whose root comes from neuroscience. They have led this subfield of study to become what is commonly known as "deep learning" due to advances in network computation. Both Machine learning (ML) and deep learning (DL) are science fields derived from the discipline of Artificial Intelligence. See more at: [6]. Those subfields are generally composed of several techniques that are often referred to as supervised or unsupervised, depending on if the training data includes the desired output (which corresponds to the first split) or not.
According to the previous, machine learning "is the name commonly applied to a number of Bayesian techniques used for pattern recognition and learning". Taken from: [5]. This is usually translated into a variety of algorithms that learn from historical data and make predictions based on it. Unlike typical computer code developed by software programmers, statistical models aim to return back a variable of interest based on patterns found in historical data rather than generating an output from a specific given input. Within an organization, ML is often following this lifecycle:

Use cases in which ML is applied include some of the following:
- Anomaly detection: to identify observations that do not comply with a expected pattern.
- Fraud detection: to identify potential fraudulent actions in industries such as banking or retail.
- Customer churn: to predict when customers are prone to leave a business and engage them through a specific marketing mix.
- Content personalization: where most of the product recommenders fit.
ML or predictive analytics on top of AWS can be performed through different alternatives, depending on if teams look for predefined interfaces to deploy deep learning models or if they want to built machine learning models from scratch in a platform or application service.
-
AWS Deep Learning AMIs: Amazon provides different machine images where pre-installed EC2 instances can be launched together with established common deep learning models such as TensorFlow, PyTorch, Apache MXNet, Chainer, Gluon, Horovod, and Keras that train either customized or pre-defined artificial intelligence models. Those Amazon Machine Images (AMIs) can be supported in Amazon Linux, Ubuntu and Windows 2016 versions.
Besides the deep learning framework support, this special AMIs accelerate the model traning phases by means of the following:
- GPU Instances: Amazon EC2 P3 instances can be configured with up to 8 NVIDIA® V100 Tensor Core GPUs and up to 100 Gbps of networking throughput, which speeds machine learning applications. Specifically, Amazon EC2 P3dn.24xlarge is the most recent machine within the P3 family. According to the vendor, "Amazon EC2 P3 instances have been proven to reduce machine learning training times from days to minutes, as well as increase the number of simulations completed for high performance computing by 3-4x". See more at [5].
- Demanding computing CPUs: the C5 family is part of the Amazon EC2 instances offered for running advanced compute-intensive workloads. These instances are powered by the Intel Xeon Platinum 8000 series (Skylake-SP) processor and a Turbo CPU clock speed of up to 3.5 GHz. Also, they can provide up to 25 Gbps of network bandwidth. See more at [6].
- Python and Anaconda: both Jupyter notebooks and the Anaconda platform are straight away available for the installation of required packages and also to access their specific scientific computing tools such as Orange 3 and Spyder. See more at [7].
-
Amazon SageMaker is the Amazon platform to build, train and deploy machine learning models into production environments. This tool, as well as the Deep Learning AMIs, automatically configures TensorFlow, Apache MXNet, PyTorch, Chainer, Scikit-learn, SparkML, Horovod, Keras, and Gluon frameworks, as well as hosted Jupyer notebooks, which altogether can host more than 200 pre-built trained models from the AWS marketplace and can also host any other algorithm or framework by building it into a Docker container. See more at [8]. Note, however, that they can connect to other EC2 Amazon instances that are not necessarily optimized for speeding up artificial intelligence or machine learning models, as happens in the case of the Amazon Deep Learning AMIs.
One interesting feature to highlight has to do with an additional data labeling service that is offered together with Amazon SageMaker. It is called Amazon SageMaker Ground Truth and allows access to public and private human labelers that can accelerate the data labeling process and help in the automation of the labeling within the machine learning models in further stages. According to the official documentation, Ground Truth has contributed to a 70% in the reduction of the costs associated to labeling in all the business cases it has been used. Also, note that this service is similar to the initial one provided by Amazon Mechanical Turk, which is an outsourcing crowdsourcing marketplace for different jobs and business processes. The whole functioning of the tool is as follows:

Main disadvantages related to Amazon SageMaker
Amazon SageMaker has been released by the end of 2017, which makes it a relatively new service open to the market. Even though it has been graded with an average grade of 4.5 out of 5 by end users (see more at [10]), some disadvantages have been addressed as well, such as:
- A less user-friendly interface for non-technical workers.
- It lacks enough documentation that is publicly available.
- Can result in expensive costs at the beginning due to usage of GPU instances to accelerate models trained.
- It is not still possible to schedule training jobs.
Main advantages related to Amazon SageMaker
Overall advantages related to the product are summarized as:
- It signifincantly reduces time-to-market.
- It allows intuitive visualization for trained models.
- Easily scalable.
The AWS Marketplace puts together different external techonology products and services that can be integrated to the whole Amazon cloud computing ecosystem in the form of applications. Popular products in the marketplace are related to one of the following categories: operating systems, security, networking, storage, business intelligence, databases, DevOps and machine learning.
Some popular examples within the business intelligence category are:
- Tableau Server for device-agnostic visual analytics.
- Qliksense Enterprise, also for building business intelligence and reporting dashboards.
- SAS University Edition "for teaching and learning statistics and quantitative methods".
- Matillion ETL for Amazon Redshift to build ETL/ELT pipelines oriented to data storage in Amazon Redshift.
Similarly, for machine learning it is possible to find remarkable products such as:
- H2O Driverless AI, which is an artificial intelligence platform that automates machine learning workflows such as feature engineering, model validation, model tuning, model selection, model deployment and also data visualization. Moreover, according to their own description, the platform "aims to achieve highest predictive accuracy, comparable to expert data scientists, but in much shorter time thanks to end-to-end automation," something that could eventually put many employments within the data science industry at risk.
- KNIME Server Small for AWS aims to deploy KNIME Analytics Platform within the Amazon cloud ecosystem to automate machine learning models and ETL/ELT workflows.
- Databricks Unified Analytics Platform: powered by the creators of Apache Spark and MLflow "it provides data science and engineering teams ready-to-use clusters with optimized Apache Spark and various ML frameworks(e.g., TensorFlow) coupled with powerful collaboration capabilities to improve productivity across the ML lifecycle".
- ML Workbench for TensorFlow provides a zero-admin solution that includes the architecture necessary to run machine learning jobs in an optimal way. It includes Ubuntu 18.04 with Jupyter, JupyterLab, TensorBoard and preconfigured conda environments for Tensorflow 1.13.1 and TensorFlow 2 Alpha including the latest matching versions of CUDA 10.0 and cuDNN 7.5.0 for GPU-accelerated computing.
Finally, it is important to acknowledge that the concept of deep learning is also related to ML, as DL involves layering algorithms that often allow a greater understanding of the data. These algorithms, as opposed to classical ML models such as regressions, do not aim to create a explainable set of relationships between variables, but instead they are relying on their "layers of non-linear algorithms to create distributed representations that interact based on a series of factors", which allows scientists to find more patterns than it is possible to code or even recognize and take them into consideration to train complex prediction models See more at [9]. Some of the use cases of deep learning include:
-
Amazon Rekognition is the tool that Amazon has built for including image and video analysis into applications. The Rekognition API and its service can identify objects, people, text, scenes, and activities, as well as any inappropriate content within a service. This tool also provides facial analysis, facial recognition and even celebrities recognition.
The following graph depicts the general workflow of the tool:

Some examples of the outputs generated from this API are:



Main critics related to Amazon Rekognition
Launched in 2016, this tool used to be compared against the Google Cloud Vision solution and seemed to be less powerful, as Amazon Rekognition did not use to detect logos and violent content, features that have been included into the product by January 2019. However, many still say that Google Cloud Vision has a better performance due to the training set it uses. See more at: [11].Another criticism made to Amazon Rekognition is related to the ethnic and gender bias it is claimed to have. According to MIT researchers, this tool has several issues recognizing black and asian people, with an average of 77% of accuracy compared to a 99% for white people (see more at [12]). To illustrate this, the team found that according to the software, Oprah Winfrey is a male with 76.5% of likelihood. See more at: [13].



-
Amazon Polly is a Text-to-Speech service that synthesizes speeches through deep learning algorithms so that they sound like human voices and can enable speech-based products. Voices included in this tool are both male and female for more than 15 languages.
Content creation is also possible through Amazon Polly by adding speeches to media communication. The following is an use case in which an article is converted into a speech and then downloaded as MP3:


-
Amazon Comprehend uses Natural Language Processing to find insights and patterns in text. Unstructured data coming from customer emails, support tickets, product reviews and social media can be analyzed through this service, which is useful to find key phrases, places, people, brands, or events. Moreover, sentiment analysis is also possible through the AutoML capabilities of the service that allow users to explore tailored machine learning solutions.
Also, Amazon Comprehend Medical is the extended solution of this service to process complex medical information from unstructured text. Medical information such as "medical conditions, medications, dosages, strengths, and frequencies from a variety of sources like doctor’s notes, clinical trial reports, and patient health records". See more at [9].
In general, Amazon Comprehend works as follows:


- Amazon Personalize is a tool to perform customer engagement by offering personalized product and content recommendations, tailored search results, and targeted marketing promotions. With only a stream provision of each particular business application, any additional information about the final customers and no prior ML knowledge, companies can access recommendations tunned by several algorithms, which allows them to use the most accurate one in each situation and reach their customers almost in real-time. The workflow of the tool is depicted as follows:

Companies such as Domino's, spuul and zola already use this app to provide personalized notifications.
Additional Amazon AI services also include document analysis (Amazon Textract), conversational agents (Amazon Lex), translation (Amazon Translate) and transcription (Amazon Transcribe).

The graph above shows the adoption rates of the main cloud providers. Although it is difficult nowadays to get the specific figures for the adoption of Data Science services on the cloud we acknowledge that once a customer is on the cloud the tendency is to use the full stack of services on it. Therefore we can trust AWS is still the service with the highest number of apps Running on its cloud services.
One case of study using Amazon data science related services can be found here: Formula One Group.