インシデント対応とその管理

はじめに
これはSRE Advent Calendar 2021の12/19記事です。
先日はSRE Lounge #13 にて Embedded SREs について取り上げました。
今回はインシデント管理について取り上げたいと思います。
誰かのお役に立てれば幸いです。
SREのインシデント管理についての記事は今までも多く出ています。
よって基本的な説明は他の記事をご覧いただくほうが良いと考え、本記事では以下にターゲットを絞っています。
本記事で取り上げること
- インシデント管理に取り入れて良かったこと
- 失敗例
- インシデント管理ツールについて
- 選ぶ上でのポイント
- SaaS
- OSS
本記事で取り上げないこと
- インシデント管理の基礎
- ITIL における問題管理とインシデント管理の話
- AIOps
想定読者層
- インシデント管理の基礎理解者
- SREs以外のエンジニアを含む
インシデント管理に取り入れて良かったこと
まず初めにインシデント管理で良かったと思ったものをいくつか紹介します。
インシデントコマンダー(IC)やウォールーム(War room)といった基礎的な組織体系の話は省きます。
良かったこと: インシデント管理ツールの存在
インシデントが起きた際に、ウォールームの設置が重要なことは皆さんも認識されていると思います。
昨今、コロナ禍の影響よりWFH(Work From Home. 在宅勤務)が広がり、緊急で皆で集まってという行動もすべてオンライン上で行われることが多くなりました。
また、文章として残しておくことは重要ということもあり、たとえばSlackで一時的なチャンネル(対応完了後にアーカイブで保存)を作成してそこで議論や調査結果報告のやりとりを行うケースが多いのではないでしょうか。
その際に単純にチャットでやりとりするだけではなく、インシデントをデータ管理することで「サービスの信頼性の傾向を見る」、「予測を立てる」といったことができるようになります。
インシデント対応記録は貴重な財産となるので、適切に管理することが望ましいです。
インシデントを分析できるようになると具体的には次のようなことができるようになります。
- 状況を把握する
- 発生数の多いインシデントのタイプ
- 原因の共通点
- インシデント発生数が多い、発生率が高いサービス
- 傾向を見る
- サービスの品質と信頼性の見通し
- 会社全体
- サービス単位
- サービスの品質と信頼性の見通し
これにより、さまざまな効果が期待できます。
たとえば、Playbook(手順書)を共通化した方が良いインシデントを見つけたり、自動化(自動復旧やRunbook。Runbookについては後ほど説明)の方が適しているインシデントも発見しやすくなる、または信頼性の向上に貢献することがしやすくなると考えられます。
本来「信頼性の向上に貢献」という観点ではその判断や意思決定を行う基準としてSLOを使う方が望ましいです。しかしSLOだけではインシデントを分析することは難しいです。
SLOはサービスの信頼性を保つための重要な目標値ですが、インシデントの内容や状況、そして傾向を直接示すものではないからです。
それにSLOの閾値を組織全体で常にすべて完璧にし続けるのは結構難しいことでもあり、インシデント分析はセカンドオピニオンとしての役割やそのサービス開発チームの外から全体を俯瞰する指標として役立つものだと考えています。
仮にインシデントの分析をする必要がないとしても単純に毎回手作業でチャンネルを作る運用にしてしまうと次のような問題が発生しやすいです。
- 探しにくい
- 参加しづらい
- どこにいつウォールームが作られるか不明確
- 専用チャンネルが作られたことに気がつけない
- どこにいつウォールームが作られるか不明確
原因として考えられるのは命名規則を含め、一時利用チャンネルの作り方に一貫性がないことによるものが考えられます。
これらは人間全員がルールを覚えてそれに従うよりも仕組みでどうにかしたほうが良いです。
自動生成してくれるツール(Slackのスラッシュコマンドなど)があるとそれらの問題を解消してくれます。
まとめると次のようなものが自動化されていると便利です。
- チャンネル名は命名規則に従う名前を付ける
- e.g.,
#incident-${NUM}#incident-1- インシデント発生時に影響範囲や原因の特定ができていないことが多々あるので、チャンネル名に内容は含めない方が良いです
- e.g.,
- チャンネルの説明をする
- 関連するアラートのURL
- チャンネルをクローズできる条件などを記載したインシデント管理手順へのリンク
- ポストモーテム用のドキュメントが生成され、そのリンク
- チャンネルが生成されたことを通知する
- 通知先のチャンネルを決めておく
- e.g.,
#incidet,#alert-****
- e.g.,
- 通知先のチャンネルを決めておく
- ポストモーテムを管理する
- 恒久対策を管理する
- 分析をする
- インシデントデータを集めて発生件数の推移を見たり、予測を立てられるようにする必要があります
- 過去データの検索ができる
これらをすべてを自前で作るのは、結構作り込む必要があります。(とくににデータ分析基盤やInsight Dashboardなど諸々を作る部分まで含めると)
SaaSでも色々あるので紹介していきたいと思います。
たとえば代表的なページャーツールのPagarDutyでもSlackチャンネルのウォールーム作成は標準機能で備わっています。(私は使用していませんが) それに分析ダッシュボードも備わっています。 また、APIも用意されているのでカスタマイズ分析なども行えるようになっています。
他には Blameless があります。(これは筆者が使用経験あります)
BlamelessにもAPIが用意されているのでカスタマイズ分析ができます。
たとえば、タグ機能を使いインシデントデータを分類し、それを使った統計や傾向の分析、予測ができるようになります。
個人的にはポストモーテムのドキュメントがanchor link(Google Docのブックマーク機能のように)やドキュメント内にコメント機能、Markdownに対応だとよりコラボレーションしやすいので嬉しいですが、現状でも困ることは起きていません。
好き嫌いはあるかも知れませんが、総合的にみて誰でも使いやすい方が良いですしすぐにインシデント管理からポストモーテム、分析までが一気通貫してできる方が望ましいので、個人的にはこれはこれで良いツールだと思います。(SlackスラッシュコマンドとGoogle Docだけでも良いのでは?と思っていた時期が私にもありました)
他には、 Rootly なんかも同じ事ができるようです。(筆者はこちらの使用経験もありません)
その他の可視化方法として有益だと思っているのがSRE Lounge #13 で紹介した「SRE課題計測ダッシュボード」です。

これは、上記のインシデント対応履歴データ以外の監視データ(Metrics、Errors)を含めた会社全体のSRE課題を俯瞰するものです。
将来的にはインシデント対応履歴データ(PagerDutyやBlamelessなど)+ 監視データから作るSRE課題の計測データ(DatadogやPrometheusなど)をまとめて1つのダッシュボードにできるとSLOの補助ツールとして凄く良さそうだと思っています。
最近の状況としては、DatadogやSplunkなんかはインシデント管理にも力を入れ始めているので、今後は監視+インシデント管理というその流れが加速していくのではないかと見ています。
各SaaSでシェアの奪い合いが起こっているようです。競争が起きて発展することは利用側としては良いことです。
なお、「SLOが完璧に運用できているならSLOダッシュボードだけで十分」という意見がもしもあればそれを完全に否定するものではありません。
しかし先に述べたとおりSLOは直接インシデントを管理するものではありません。信頼性を守るという本質的な観点で必要か判断することを私は推奨します。
OSS
OSSのインシデント管理ツールはどうなんでしょうか。
GitHubにはIncident-managementというトピックがあります。
Incident-managementのトピックには事例集なども多いので、探しづらいのですが以下がそれに近いツールです。
Response
これは Monzo というUKで展開しているBanking Serviceを開発している会社が作って公開しているツールです。
(USでもローンチしている模様)
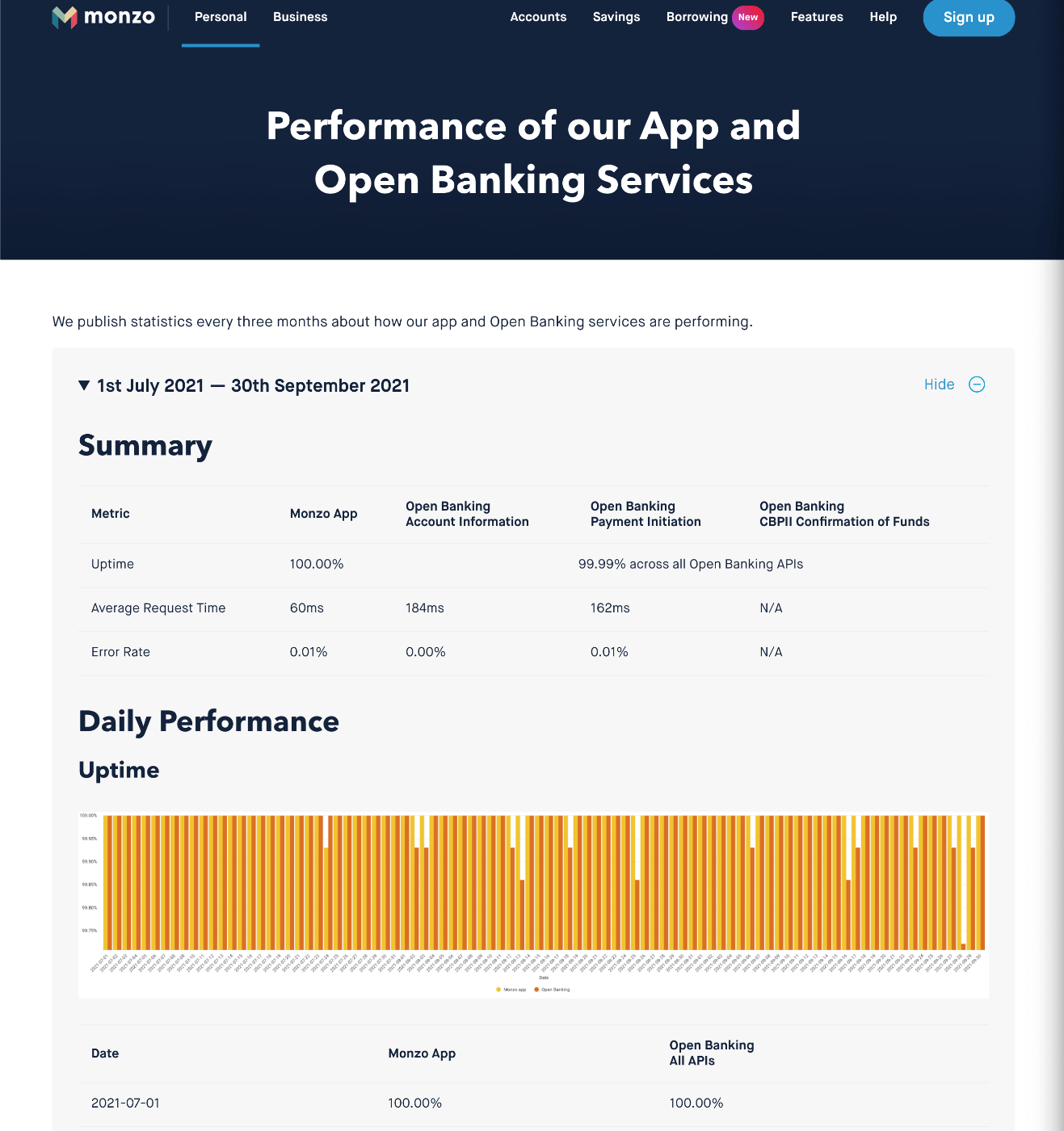
Monzoは、KubeConに何度か出ているので、ご存知の方も多いと思います。
話が反れますが、MonzoはUptime、Avg Request Tiem, Error RateといったServiceのPerformanceを公開している信頼性への意識が高い企業です。
- How we respond to incidents
- Incident Repponse With Monzo Incident
- Building a Bank with Kubernetes by Oliver Beattie, Monzo
- Modern Banking in
15001600 Microservices - KubeConで失敗を紹介したMonzo Bankのキーノート
- Banking on Kubernetes, the Hard Way, in Production
私はResponse の業務使用経験はありませんが、この記事を書く上でdemoを動かしてみました。
データ分析機能はありませんが、それ以外のインシデントへのレスポンスはこなせるようです。
Slackでウォールームの一時利用チャンネルが生成されます。





いくつか注意点があります。
- 開発が停止している
- demoがそのままでは動かない
- 更新していくやり方が分かりにくい
- シンプル
- ポストモーテムや分析機能およびテンプレートは備わっていない
- APIも存在しない
- ウォールームでやりとりした内容の補助機能がない
- たとえばBlamelessだとその専用チャンネル内で画像添付した場合、自動的に関連するインシデント管理チケットに添付されたりします
- 細かい時系列記録が出来ない
さまざまな機能を求める場合は、やはりSaaSを使う方が良いと思います。
また、ResponseはForkもそれなりにされているのですが、派生もとくに生まれていません。
もし使うならforkして自分たちで運用保守などしていけるか考えてからが良いと思います。
demoがそのままでは動かなくなっている件についてですが、
動くようにしたので、試される方は以下を使用するか参考にしてください。
※OSSで他に良いツールをご存知の方がいましたらコメントくださると嬉しいです。
良かったこと: Five Whys(なぜなぜ分析)を取り入れる
次に紹介するのは、Five Whys(なぜなぜ分析)と呼ばれる分析方法をポストモーテムで恒久対策を練る際に実施していることです。
トヨタから発祥した問題管理方法です。
当然ながら「他者を非難しない」ということはここでも徹底されます。
なので、「原因の究明を”人”にフォーカスせよ」なんてことはありません。
トヨタは「なぜ」の繰り返しで原因を掘り下げることで、「原因を安易に特定した気にならないよう、注意する」ことを提唱しています。
これは非常に重要な考えです。
とくに忙しいときにポストモーテムを実施し、恒久対策を練る余裕があまりないときこそ、根本原因を早期に特定させたくなる気持ちが強く出やすくなります。
そうなると早合点しがちになります。
インシデント発生時の初動で止血としてはスピード重視が良いときも多いですが、ポストモーテムで恒久対策を検討している際にそれでは悪い結果を招くこともあります。
そこは気持ちを切り替えて、このFive Whysを取り入れていくのは良いと実感しました。
ただし、注意点として紹介しますがFive Whysは誤解されていることがあるようです。
"Why"と書いているのになぜかそれを"Who" に置き換えてしまい、誰かを避難してしまうケースがあるようで、それが原因のようです。
たとえば以下の記事ではその問題を指摘し、「Five Whysは危険だ。無限のHowにしよう」と提唱しています。
※ただし、記事内のコメントでも「それはトヨタのFive Whysではない」と指摘されています。
Hi, I I’m not sure which definition of “The Five Whys” you are referring to but the first one that comes to my mind is the Toyota one. And, if we are talking about this one, I think this was very badly represented in this article. To me It looks like you are arguing against the wrong application and interpretation of the Five whys.
I’m quite sure you are talking about reality here: someone in a company reads a blog about the Five Whys and tries to apply it leading to all the bad effects you address.
But I did not found anything of this in the beautiful book Toyota Kata where the Five Whys are described exactly as your “Hows”: deep and neutral observation of the event to fully understand it. The tendency to rush to a solution is described as something to avoid.
もし"Why" を "Who" に度々に置き換えられてしまうギスギスした環境なら私もいきなりFive Whysはオススメしません。まずは誤解を解くところから始めると思います。しかし私は幸いなことに今まで遭遇したことありません。環境に恵まれてきたのだと思いました。
以下の記事でもFive Whysの注意点が記載されています。
なお個人的に思うことは、まず "Why" が "Who" に変わる時点で意味もまったく変わってしまっているため、その時点で「違う」のは明白だと思っているのですがそれが起きやすいと警告されている根本的な原因は "ポストモーテムのやり方が間違っている" ことだと見ています。
ですからまずはその土台をしっかりとする必要があり、「他人を避難しない」を徹底することが重要だと捉えています。
それを前提とした上でFive Whys使用すると、とても強力な武器になります。
ちなみに5回は目安だと思っています。
良かったこと: 「問題解決の5段階」を問題の認識合わせに使う
全員が問題を共通に認識しているかどうかは分かりません。
そのときに役立つのが以下のようなコミュニケーションの組み立てです。
問題解決の5段階、5階層
以下の順でコミュニケーションを図り、認識の齟齬をなくす。
- 何が起こっているのか
- 具体的にどう困るのか
- なぜそれが発生するのか
- どのような解決策があるのか
- どの施策が効果あるのか
3から5でFive Whysを使用しています。
https://little-hands.hatenablog.com/entry/2019/12/13/problem-solving-5layer
こうすることで、ポストモーテム参加者のすり合わせがスムーズに行われ、妥当な恒久対策を選定しやすくなります。
(妥当な恒久対策: 費用対効果の薄い、あまり意味のない恒久対策を時間とコストを掛けて行っても誰も嬉しくありません)
良かったこと: PlaybooksとRunbookの導入
まずは言葉の定義から始めます。
PlaybookとRunbookの違いは何でしょうか?違いを明確にしていますか?
PlaybookとRunbookの言葉の定義を以前調査したところ、曖昧でいることが多いとわかりました。
会社全体で普及させる際に、その定義から始めた方が良いです。
各社それぞれ両方同じ意味で使っていることが多々あったのですが、PagerDuryの次のブログ記事で紹介されている定義がわかりやすくて個人的に気に入っています。
What is a Runbook?
ここでは、ものすごく簡単に説明するとPlaybookがイベントのガイドブックで、Runbookは料理本。料理はそのイベント全体の1つの側面に過ぎないと説明されています。(詳しいことは中の記事をご覧ください)
また、Runbookは最小限の実行可能なものにする方が良いです(1つの目的に抑える、単一責務にする)
これらの詳細説明も別の機会に出来ればと思いますが、私はPlaybookを基準としてRunbookはその中に入るコンポーネントだと捉えました。
そうすることで、各Runbookの再利用性が高まります。

これらを備えておくことは大きな付加価値があります。
安心感という意味でも非常に役立っていて、その結果オンコールに入りやすくなっています。(少なくても自分はそうです)
ほとんどのエンジニアが未知のインシデント対応にはストレスを感じるそうです。
そういった面を緩和させる効果も期待できます。運用ストレスを可能な限り減らしておくことも重要です。
また、この文化が全社的に広がれば属人化も避けられ、SRE Lounge #13 にて Embedded SREs について で紹介した "Movable Embedded SREs" のような活動もしやすくなりますし、オンコールのセカンダリーを他のチームのメンバーがサポートするといったこともしやすくなります。
さらに付け加えると、オンボーディングにも役立ちます。
復旧手順やツールがあることは、そのシステムの理解が深まることにもつながる事が多々あるからです。
以上のようにPlaybook、Runbookを用意するとさまざまな面で有益になることが期待できます。
失敗例: 重大ではないアラートに過剰反応、もしくは不必要なアラートが多すぎる問題
SLI/SLOは設置していてもそれがアラートに上手く結びついていないといったことがあり、毎回不必要に飛んでくるアラートに反応してしまったり、PagerDutyで夜中に度々電話が鳴るといったこともありがちです。
オオカミ少年状態になると重大なアラートまでを見落としたり軽視するようになってしまうので、SLOベースに持っていけるように努力した方が皆の幸せです。
かといって、単純にすべてのアラートをSLOアラートにした場合、来た時点で致命的な状況になっていることが考えられます。
それはよくないということで、SRE WorkbookではSLO Burn Rate Alertが紹介されました。
これを上手く運用することが出来れば、過剰に反応しないでも済むようになる且つ手遅れにもなりにくい運用方法だということは偉大な書籍からも判明しており、上手く適用させてアラートを減らし過剰反応もしないで済むように努力を重ねています。
失敗例: 大きなインシデントが起こるとPagerDuryへのAck祭りが始まる
PagerDutyから通知が来るとそれにはAckボタンが備わっていて、それを押して応答しないと電話が鳴る仕組みになっています。
PagarDutyへのAck祭りとはその通知が同時多発で来て、Ackを返す作業が多く続くことを指しています。(Ack祭りなんて言ってるのは私くらいかも知れませんけど)
大きなインシデントは、影響の深刻度の他に多方面、多サービス、多くのエンドポイントで問題が同時多発します。
同時多発的に発生する際にAlertを多く設定しすぎていると同時且つ断続的にアラートが来ます。
SlackのAlert専用チャンネルに通知が行くだけなら緊急対応にそれほど支障はありませんが、先に述べたとおりPagerDutyはAckを返さないと電話までかかってくるので、それが多いと影響が出ます。
このあたりも適切な数に減らしてインシデント自体への対応をより早く着手できるようにする必要があり、同じ内容のアラートが同時間帯に来ないように抑制するといった対応も必要です。
これもSLO Burn Rate Alertで、アラート設定数自体を適切な数に減らすことができれば大分減らせるとは思いますが、その他の仕組みも必要です。
PagerDutyのインテリジェントアラートグループやインシデント通知の一時的機能などを駆使しても減らせる可能性があります。
また、PagarDutyの通知トリガー元では、PrometheusのAlertmanagerのGrouping, Inhibition, Silences機能やDatadogの通知設定で本当に必要なアラートだけをPagerDutyで通知するようにするのも重要です。
最近出たDatadogのインシデント管理でも上手くやれるのかも知れませんがそちらはまだ試せていません。
インシデント管理ツール(SaaS。 ※AWSやGCPといったクラウド内のサービス以外)
SaaSのインシデント管理ツールを紹介しておきます。
もちろん私が現在把握している範囲での話なので、他にもさまざまな手段があると思います。
最後に
インシデント管理や対応のネタは多く、書ききれないので今回はこのあたりで終わりにしたいと思います。
「こういったものがある」や「オススメ」、「ここはこうした方が良い」などご意見があれば是非コメントください。
Discussion