
Thinking about using AI?
Here’s what you can and (probably) can’t change about its environmental impact.
By Hannah Smith and Chris Adams
Image credit: Jamillah Knowles & We and AI / Better Images of AI / People and Ivory Tower AI / Licenced by CC-BY 4.0.
Executive summary
This briefing is intended to help people with a responsibility for AI projects understand the considerations around their direct negative environmental impact arising from AI. We cover what to be mindful of, what mitigating strategies are available today, and their limitations.
As the climate crisis deepens, the direct negative consequences of AI on the world around us is a growing concern. This stems from the immense quantity of resources, such as electricity, water and raw materials, required to manufacture and run the infrastructure and hardware supporting such complex computations. Current predictions forecast a near doubling of electricity use from data centres between 2022 and 2026. Furthermore, what we do with AI-related hardware once it reaches the end of its life is an unanswered question. Globally, e-waste is recognised as the fastest growing waste stream in the world.
In this report, we deep dive into five key areas of knowledge that we believe serve as a useful foundation when considering your direct impacts. These are:
- There’s a large and growing environmental impact associated with AI adoption
- Mass adoption of AI is jeopardising existing company sustainability goals
- AI’s footprint can be
measuredestimated, but it’s an emerging discipline - Changing your choice of AI model and task impacts the footprint
- Any AI code can be run in ways that reduce the footprint
Armed with this knowledge, the next logical question is what can you do about it? We outline three practical actions you can take to make a difference to your direct environmental impact, and any associated limitations with this approach. These are:
- Question your use of AI ➡️ know when to use it
- Optimise AI use ➡️ use it responsibly
- Prioritise getting estimates of AI’s footprint ➡️ ask for your usage data from suppliers
If you are on a journey to dig deeper into these questions and actions and need support, get in touch.
Introduction
What is AI?
When we say artificial intelligence (AI) in this report, while the term goes all the way back to 1956,1 we’re referring to a specific subcategory of computing called machine learning (ML). An ML system is best considered as a predictive system relying on models, designed to perform a set of distinct tasks using statistical analysis gleaned from specific data it’s been trained on.
ML models are used in a huge range of places. In every case, the model is effectively making a prediction based on previously seen data. Photos are enhanced based on massive datasets of photos that have been classified by human experts as “good” or “bad”. Shopping recommendations are based on what people classed as “similar to you” have previously bought. Even in a conversation with an “AI” assistant, each word is down to a model making predictions about what next word is most likely to sound convincing, based on thousands of conversations previously fed into it.
Enough predictions in sequence can generate entire sentences that resemble a chat with a person. This ‘generative’ behaviour has given rise to the term Generative AI. Generative AI models are trained on vast sets of data enabling them to perform a growing range of tasks beyond just generating text to generating images, speech, videos.
The story of AI’s adoption boom
The AI approach has proven to be powerful and versatile.
Generative AI in particular has captured the popular imagination, resulting in a fast and dramatic race for adoption. As an example, ChatGPT,2 OpenAI’s flagship Generative AI service, took only two months to reach 100 million users.3 The same scale took Instagram two years and Facebook nearly five years.4
In January 2023, Microsoft invested $10 billion into OpenAI, licensing their models for use across their entire product line. In response Google, whose researchers were behind the original ‘Transformer’ architecture that ChatGPT5 was based on, announced their own PaLM 2 model. This is used in over 25 products as well as Google’s flagship Search, Docs, Gmail services.6
The same year, Meta made their own move. In addition to investing tens of billions of dollars into their own digital infrastructure, they also released their Llama series of Generative AI models under a relatively permissive licence.7 This meant the models could be run by anyone with access to hardware powerful enough to run them. This can be seen as a strategic move to build an open ecosystem to counter Microsoft’s and Google’s early lead. It was interpreted as such in the technology industry, particularly after the leaked memo within Google stating, “We have no moat, and neither does OpenAI.”8
From arms race to gold rush
As more companies entered the fray, the open ecosystem of AI models grew quickly. This drove new demand for AI-specific hardware and infrastructure. Over the last three years, large firms like Google, Amazon, Microsoft and Meta have spent a combined $130-150 billion each year on capital expenditure,9 publicly citing AI data centres as a primary driver of this spending.
Meanwhile, Nvidia, the company making most of the chips used for AI, has also seen its own valuation increase more than sevenfold since 2020 on the back of this boom. In June, Nvidia eclipsed Amazon, Google, Apple, and Microsoft to briefly become listed as the most valuable company in the US,10 before settling back into position as the third most valuable company in the US,11 with a market capitalisation of more than $2.3 trillion.
Just like Nvidia’s heady valuations are based on future earnings, the investments made by the large firms mentioned above have been made on predictions of future demand for AI services. A growing number of organisations are hoping to catch this wave of interest by speculatively designing new AI-centered products or new AI-enabled features in existing products.
In the summer of 2024, AI is still a hot topic. OpenAI is claiming 200 million weekly active users—twice as many as it had last November.12 Hundreds of billions of dollars have been invested in AI infrastructure, and this is projected to continue. Investment bank Goldman Sachs is expecting in the region of $1 trillion to be invested in AI infrastructure in the coming years.13 For context, this is a figure comparable to the level of investment in telecoms infrastructure during the dot-com bubble in the late 1990’s and early 2000’s.14 There are similar parallels to the productivity gains promised by increased network capacity deployed.
Growing concerns about the deployment of AI
AI services bring a range of risks to society. In response, there’s been a Cambrian explosion of AI risk frameworks developed to document and mitigate against the associated harms from use. The MIT AI risk repository now tracks no less than 43 different AI risk frameworks, covering more than 700 separate identified risks to mitigate.
Even when we put aside these societal risks, environmental or otherwise, valid questions remain about who is actually benefiting from the wider deployment of AI models.
It’s not difficult to find reports extolling the positive climate benefits of deploying of AI, like Boston Consulting Group’s Accelerating Climate Action with AI15 and consulting firms like Accenture talking about How Gen AI can Accelerate Sustainability.16 At the same time, some of the biggest winners from AI are management consultant firms making money selling the consulting around AI, rather than the organisations deploying it themselves.
For context, Boston Consulting Group, and McKinsey are expecting 20% and 40% of their consulting revenue respectively to come from advising clients on how to use Generative AI in 2024. Meanwhile, corporate AI projects are turning out to have a failure rate of around 80%17, based on recent research from the non-profit RAND corporation—a rate twice that of standard IT projects.
One of the reasons appears to be related to the kinds of problems people are trying to solve with AI, like automating away expensive labour. If we put aside the ethical questions around doing so, it is often the automation of increasingly expensive labour that is needed to justify continued multi-hundred billion dollar investments in AI infrastructure. In the eyes of analysts at Goldman Sachs in the report Gen AI: Too Much Spend, Too Little Benefit?, this isn’t happening. In their view, AI is not built to solve these complex problems and is unlikely to deliver the promised benefits.
Will the environmental impacts of AI resolve themselves as the shine wears off?
If delivering on the promised value of AI and (in particular generative AI) is proving to be more complicated than initially suggested, then perhaps the money will dry up. Perhaps the frenzy of activity around AI, with corresponding it’s environmental impacts will go the way of hype around the Metaverse, or Blockchains.
However, this doesn’t appear to be the case. The largest tech firms’ continued guidance to stakeholders is that they intend to keep making massive investments in new AI-focussed data centres regardless. Google and Meta and Microsoft are all still bullish in their investment plans.18 Microsoft CFO Amy Hood is advising shareholders to expect a 15 year timeframe for seeing returns—meaning they’re prepared to keep losing money on it—and to expect further increases in infrastructure build out beyond 2025.19
Understanding the direct environmental impacts of AI
Now we’ve set a high level backdrop of what’s happening in the AI space, we’ll provide some guidance for thinking about the direct environmental impacts of AI. Before we do, we need to explain why we don’t cover some of the wider outcomes of deploying AI.
Why focus on the direct environmental impact of AI?
It’s easy to find examples of AI projects that set out to deliver sustainability outcomes. These are sometimes referred to as AI for Good, AI for Climate or AI for Sustainability, or under a broader term, Tech for Good. They’re fun to read, and fun to write about.
These projects are also often used to ward off any criticism of the direct impact of deploying AI services. The argument usually goes as follows:
If there are positive impacts and negative environmental impacts of deploying AI, then the environmental costs are an acceptable price to pay for the benefits they offer.
There are two problems with this argument – the first is about data, the second is about the argument itself.
The first problem: the data
Broadly speaking, it’s quite easy to find predictions about the positive environmental impacts of digital services or statements about the benefits they could deliver. However, the sector has a relatively poor record of validating that these interventions have worked at the scale promised—such that ICT Sustainability expert Vlad Coroama has coined the term Chronic Potentialitis to describe this lack of follow-through.20 We cover this in more detail in our own Fog of Enactment report from 202221 but we can illustrate this with a simple question.
Is AI being used to accelerate oil and gas extraction more than than it’s used to decarbonise our society?
As it stands, Microsoft, arguably the leader in AI deployment, and one of the market leaders selling to the oil and gas sector won’t even share who’s buying AI services across the different fossil and non-fossil energy sectors with its own staff after making commitments do so,22 let alone with anyone else.
No technology firm we know of discloses this information either, but firms like Gartner do share analysis of how they expect spending on AI in the oil and gas sector to double to $2.7 billion by 2027.23
Elsewhere management consultancies like EY have proudly stated on their websites that “more than 92% of oil and gas companies are either currently investing in AI or plan to in the next two years,” as they chase new business.24 A recent report from Karen Hao in the Atlantic details Microsoft aggressively chasing multiple hundred-million dollar deals to accellerate fossil fuel extraction with various oil supermajors like ExxonMobil, Chevon and Shell25.
These stories are just as important for answering the question posed above, and they highlight how right now, we don’t have the information to have a data-informed conversation about the wider impacts of AI.
So if we spend all our time talking how good “AI for Good” could be, without talking about how much AI capacity actually is being used for fossil fuel extraction right now, then we are falling for the same tactics of predatory delay26 used for the last two decades to ward off substantive action on the key driver of climate change – burning fossil fuels.
The second problem: the argument itself
Secondly, even if we had access to the data, the existence of an upside in any intervention, AI or otherwise, doesn’t automatically free us from the responsibility of thinking about how to mitigate the downsides. When we build systems that store sensitive data, like financial or health records, the fact that they’re useful doesn’t free us from having to think about how to keep the systems safe. AI is no different in this respect.
As we’ll see later in the briefing, these responsibilities can carry the full weight of the law behind them, and there is already plenty to think about.
What to expect from this briefing
This briefing is intended to help people developing an internal AI policy, or people responsible for AI projects to understand the considerations around their direct environmental impact.
If we deploy AI, what does all this mean for the environment? More specifically, what does it mean for those of us working in organisations with a commitment to reduce the environmental harms resulting from our activities? What mitigating strategies are available and how do these align with other strategic concerns such as productivity and profitability?
5 things every business should know about the environmental impact of AI
1. There’s a large and growing environmental impact associated with AI adoption
2. Mass adoption of AI is jeopardising existing company sustainability goals
3. AI’s footprint can be measured estimated, but it’s an emerging discipline
4. Changing your choice of AI model and task impacts the footprint
5. Any AI code can be run in ways that reduce the footprint
1. There’s a large and growing environmental impact associated with AI adoption
For decades, we’ve been under the illusion that digital is up in a cloud somewhere, intangible and floating harmlessly. The reality couldn’t be further from the truth. Digital infrastructure and devices are manufactured from, powered by, and located in the material world. Some of us are privileged so direct experience of these negative impacts is lessened, but they are definitely felt by many.
In the list of operations that businesses consider to have the most environmental impact, digital technologies are often overlooked. Yet, recent studies by digitally-enabled service based organisations like Salesforce27 and ABN Amro28 estimate that digital accounts for 40-50% of their organisation’s greenhouse gas emissions. This is likely to be more than most businesses assume.
We’ll cover how digital technologies in general create harmful environmental impacts, and the role AI is playing in exacerbating this.
How do digital technologies create environmental impact?
All digital technologies require a range of natural resources for their manufacture and operation. This is true for the servers in data centres and the laptops and networks in our houses and offices. Here’s a brief overview of the most common environmental impacts.
Greenhouse gas emissions from generating electricity
Digital technologies rely on massive amounts of electricity for both manufacture and day-to-day usage. Most of the time, this comes from burning fossil fuels. Whilst we are in the middle of a generational transition away from fossil fuels to cleaner sources such as renewables, this hasn’t happened yet. The International Energy Agency’s Electricity 2024 report reminds us that “power generation is currently the largest source of carbon dioxide (CO2) emissions in the world.”29
Digital infrastructure consumed about 460 TWh of electricity worldwide in 2022—almost 2% of total global electricity demand. This equates to about one and half times the UK’s entire electricity usage. This is a growing figure too. In the same report, the IEA expects a near doubling of electricity use from data centres between 2022 and 2026. Such is the rate of AI data centre growth, that it warranted special attention in the IEA’s report this year. AI demand is broken out for the first time in their analysis.

Within AI circles we see similar predictions. Semi Analysis, a publication known for in-depth analysis of trends in AI, is even more bullish about AI growth. In their own modelling, they expect AI to overtake all traditional data centre power demands by 2028.30

Attempting to put the enormous increase in emissions into perspective at an individual user level is tricky, as we get into in part three “AI’s footprint can be measured estimated, but it’s an emerging discipline.” A good example comes from looking towards the impact of incorporating AI into search engines such as Google. A single generative AI query could use 4 to 5 times more energy than a regular search engine query31. Others found that average energy consumption per search could be 6.9–8.9 Wh, compared to 0.3 Wh for a standard Google search.32 This gives us an enormous range of 4-30 times larger. Whichever end of the scale the figures land, it’s a significant increase.
You might be wondering if the recent boom in renewable electricity generation means this isn’t a problem. It still is. Globally, the regions with the most projected data centre capacity tend to be areas where a larger share of electricity generation comes from fossil fuels.33 We can’t automatically rely on the electricity used to power these facilities to come from clean, fossil-free generation. Furthermore, hardware manufacture relies on lots of embodied energy. Embodied energy is the energy required to produce goods or services, considered as if that energy were incorporated or ’embodied’ in the product itself. These figures are not routinely published by hardware vendors, but even these vendors acknowledge this as a problem.34
Greenhouse gas emissions from building data centres
The construction of a brand new data centre requires vast amounts of concrete and steel, both of which are major sources of greenhouse gas emissions. On average, a ton of cement will produce 1.25 tons of carbon emissions, largely from the roasted limestone and silica. Concrete accounts for as much as 40% of a data centre’s construction, followed by fuel at 25% and then steel—both reinforcement and structural—which can account for 10% of a project’s carbon footprint each.35
When complete, the world’s largest data centre, Switch’s Citadel campus near Reno in Nevada36 will occupy 7.3 million square feet, equivalent to roughly 80 football pitches. Whilst we haven’t been able to find public figures about the materials required to construct an enormous structure, we can safely assume it will be massive amounts.
Freshwater usage for cooling
In recent years, the water footprint associated with digital, and in particular data centre water consumption, has become a prominent issue.
A byproduct of running servers is heat. Data centres need to keep hardware cool. The most common kind of evaporative cooling systems in data centres consume significant amounts of water. In 2023 researchers from the University of Texas and Riverside37 estimated that training OpenAI’s ChatGPT3 large language model in Microsoft’s data centres used around 700,000 litres of fresh drinking water, and in addition, around 500ml of water was consumed for every 10-50 responses in a typical chat session.
Why is this kind of water usage a problem? In many cases, water is drawn from aquifers in regions that are already at risk of drought and water stress.38 There are clear ethical questions about allocating fresh water for use in data centres ahead of use as drinking water by local communities or agriculture. Agreements to keep water usage secret between local authorities and tech firms39 only make this situation murkier.
There’s one other indirect link between digital technologies and water use. Because data centres use so much electricity in general, the water consumed during the generation of electricity is significant in its own right. In the USA, around 40% of all the water drawn from lakes or rivers is used to cool nuclear and fossil fuel power plants during their operation, making it the largest single use of freshwater in the country40.
Depletion of materials and degradation of land from mining and e-waste
Finally, there’s an environmental impact from obtaining minerals from the earth’s crust to manufacture electronics. Take two minerals, copper and gold, that are often used for their conductivity and malleability. Typically more than 100 tonnes need to be dug up to produce one tonne of refined copper. For gold, the figure is between 250 tonnes and 1000 tonnes for a single kilogram.
Once ore is dug up, various chemically intensive and energy intensive processes are needed to extract the desired minerals. These often result in toxic tailing pools and other forms of waste, making land unusable for any other purpose.
We need to be aware that these are not circular supply chains. Electronics recycling rates are generally below 20% in Europe and the USA41. These are regions where support for these practices is greatest. Other regions don’t fare nearly as well. Electrical waste is named by the Baker Institute at Rice University as the fastest growing waste stream globally42 producing an average of 7.3 kilograms per person per year. All this unrecyclable e-waste ends up in rubbish dumps. The most toxic place in the world is an e-waste site in Ghana according to The Science Times.43
How AI is amplifying these harms
AI can work on conventional hardware, but increasingly relies on new specialised hardware
AI is especially compute intensive. This means the code is performing huge numbers of complex calculations and is often required to do so quickly. This requires a lot of computing resources such as CPUs, memory and storage. While AI tasks can run on conventional CPUs, they take a long time. One solution is to use lots of CPUs. Another is to use specialised CPUs. These may be more efficient per calculation run, but they’re used to perform more computations often leading to consuming larger amounts of resources.44
Additionally, manufacturing new and more specialised new hardware is much more resource intensive than reusing existing hardware.
AI hardware is associated with denser resource usage in the same space
In addition to individual accelerators being more power hungry, they are sold in denser clusters of hardware. In a conventional data centere, 5 to 15 kilowatts of power use per server rack is common with conventional hyperscalers towards the top end. In March 2024, the market leader Nvidia launched their DGX server taking up an entire rack, with a specified power draw of 120 kilowatts. Other infrastructure providers are aiming for higher figures per rack45. More power per rack means more heat to get rid of, which often means more water to keep hardware cool.
This denser use of new hardware leads to new infrastructure being used
The greater power demands of hardware place different loads on the surrounding infrastructure too.
Existing grid connections to existing data centres are frequently not able to serve the required amounts of electricity without upgrades, so to meet the localised energy demand, some organisations are deploying their own fossil fuel infrastructure to meet demand crunches.
In August 2024, it emerged that Elon Musk’s xAI had begun to deploying sets of mobile fossil gas turbines to supplement the supply from the grid, to make the 100MW shortfall in power demand from their new AI datacentre in Memphis, Tennessee46.
Elsewhere, last summer Microsoft applied for and secured planning to build a 100 MW gas turbine plant on the site of one of its larger datacentres to help meet its own demand47. In some cases like Microsoft, this is not intended to run constantly, but once deployed, there is a strong incentive to use the infrastructure more to make back the costs of the initial investment.
Finally, where we are making progress in decomissioning fossil fuel infrastructure, like old coal power plants, AI demand growth is slowing or reversing this trend. Bringing coal generation back online that would have been retired, or in some cases building entirely new gas turbines, is seen in some circles as one of the fastest way to meet the new demand coming from AI infrastructure48. The problems here are myriad. Once fossil fuel infrastructure is built, it can often “lock in” future emissions over the years they are expected to operate. The local pollution also shortens the lives of people living around the powerplant49. Even in the best scenario once its built, when this new capacity is decomissioned early, the cost of decomissioning this new fossil infrastructure, and replacing it with clean energy is often shifted onto residents through higher electricity bills.
In the energy sector, this issue of renewed or brand new fossil fuel infrastructure being used to meet new demand for AI is seen as serious enough for groups like Energy Innovation to issue dedicated policy briefs50 specifically aimed at heading this off.
2. Mass adoption of AI is jeopardising existing company sustainability goals
The sheer amount of resources needed to support the current and forecast demand from AI is colossal and unprecedented.
This is a real, immediate concern for all organisations looking to achieve net-zero targets, or other existing sustainability goals.
Let’s look at examples of how significant AI adoption has impacted the ability of some technology industry leaders to meet their own sustainability goals. These are large, well funded companies with enviable access to talent and capital. If AI is causing them to rethink their sustainability plans, it’s reasonable to think smaller firms will need to as well.
How are the AI leaders faring?
Microsoft, one of the most enthusiastic adopters of AI in the technology sector, and now the largest investor of OpenAI, has seen its own emissions surge by around 45% in the last three years. Part of this has been down to its own recent investments in AI infrastructure. Microsoft spent around $50 billion in 2023 on new facilities and data centre expansion for its Azure cloud computing services which are used to power OpenAI’s products.
These investments by Microsoft have contributed to the firm missing its own supply chain decarbonisation targets, as detailed in a recent report by Stand.Earth.51 This isn’t just because of their scale—the limited choice in suppliers creating AI hardware complicates supply chain decarbonisation, too. In the rush for AI, Microsoft has broken its own supplier code of conduct, which requires suppliers to have a minimum target of 55% absolute reduction in emissions by 2030.
As of August 2024, not a single one of the key suppliers providing AI accelerated hardware, including AMD, Intel and Nvidia, has goals that meet this standard. If you have carbon reduction goals, and OpenAI or OpenAI-powered products are in your supply chain, then you have partners in your supply chain already missing their own targets. This is likely to make meeting your own commitments more difficult.
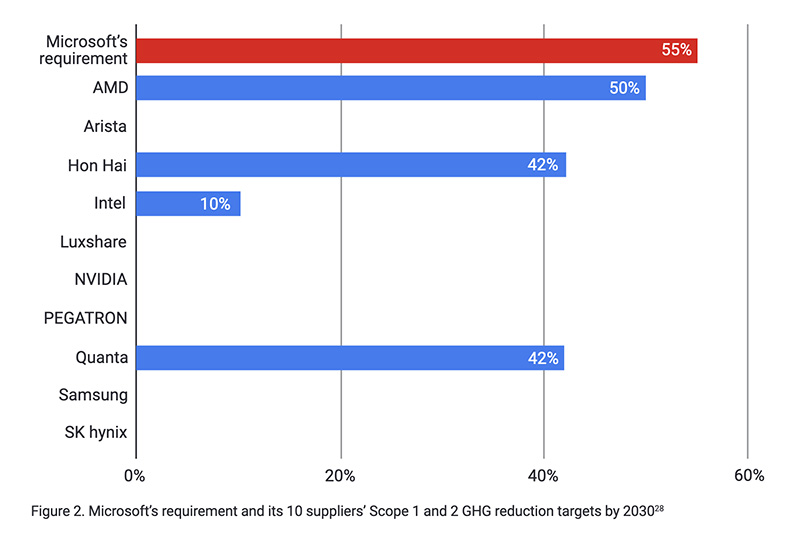
Microsoft isn’t alone in needing to revisit its own plans to meet earlier carbon reduction commitments after significant AI investments. Even after accounting for Google’s sector leading investments in renewable energy, Google’s own sustainability report in 2023 showed a jump of more than a third in carbon reported emissions from electricity usage in their data centres.52
In March 2024, Google admitted they were also revising their strategy53 after their recent investments in infrastructure to meet electricity demand introduced by AI hardware. Just looking at the struggles of these well-resourced firms highlights two significant challenges:
- How does the industry decarbonise a supply chain consisting of AI hardware suppliers?
- How can data centres responsibly source the vast amounts of energy they consume?
3. AI’s footprint can be measured estimated, but it’s an emerging discipline
Broadly speaking AI’s lifecycle breaks down into three main stages:
- Manufacture – building the hardware used for training and inference
- Training – creating an AI model
- Inference – using a trained model to answer questions
For each stage of this lifecycle, there are ecological impacts resulting from the use of earth’s resources:
| Scale | How the impact happens |
| Manufacture Building the hardware for training and inference | Manufacturing processes require amounts of electricity, heat, and very pure water. Manufacture often occurs in regions with fossil fuel heavy grids and rely on fossil fuels for high temperature heat. |
| Training Creating an AI model | Training a single model can rely on thousands of hours of computing time on specialised power hungry hardware. Energy usage scales with model size, and model sizes keep growing. Keeping this hardware cool can consume significant amounts of water. |
| Inference Using a trained model to answer questions | Inference can be run on a wide range of hardware depending on the model used. For large language models, specialised hardware is often used, consuming more power for faster responses times (i.e. GPUs and TPUs over CPUs). Like training, computation requires cooling, which requires water. |
Why is creating estimates difficult?
Finding precise numbers for a specific AI model lifecycle can be challenging, and especially so for Generative AI models. Having model-level data is an essential first step when trying to understand your own impact of using such a tool. There are two common blockers for this.
Firstly, we have some issues on getting data about the footprint of AI hardware manufacture. While some producers list figures for typical energy consumption, they don’t provide information about the energy required for building the hardware at the outset. As an aside, they also don’t provide public information about any other resource inputs such as water or rare raw materials.
Secondly, we face a similar problem when trying to understand the implications from training and inference. Most cloud providers treat two key data points for making estimations as trade secret information: i) the amount of energy consumed by the servers running the AI model and ii) the carbon emissions of that energy.
How can we get around this?
Faced with this lack of disclosure, responsible technologists are drawing upon work put into the public domain by various AI researchers54 to make their own evidence-based estimates. One of the best examples is from the startup Hugging Face, the largest hub for AI models globally. They shared their figures for BLOOM, a large language model:
“We estimate that BLOOM’s final training emitted approximately 24.7 tonnes of carbon (equivalent) if we consider only the dynamic power consumption, and 50.5 tonnes if we account for all processes ranging from equipment manufacturing to energy-based operational consumption.”
To put this into context, 50.5 tonnes is roughly the same emissions as the annual electricity use from 50 UK households each year. BLOOM’s figures are often used as a reference for making estimations of other large language models from different providers. Research like this doesn’t just help us to produce a final estimate. It also provides insight into where in the AI lifecycle impact happens. We can use this to understand where we might focus efforts for meaningful reductions.
Where to look for environmental footprint figures of models
The use of “model cards,” first popularised at Google in 2018, is now a widespread approach. Model cards document the features and performance characteristics of AI models in a consistent and standardised form. The European AI Act, the first comprehensive set of regulation on AI, requires AI system designers to provide model cards for a wide range of models. Hugging Face provides guidance on how to disclose the environmental footprint of various models.55
The most recent model from Meta, Llama 3.1, now has a model card listed on HuggingFace.56 It does not go as far as BLOOM in terms of disclosure and focuses mainly on the carbon footprint of training. However, we now have official figures in comparable form. Meta discloses a location-based carbon footprint model of 11,390 tonnes of carbon dioxide equivalent. This is nearly 500 times larger than the BLOOM model from a few years earlier. Hugging Face also provide searching tools to find and sort various machine learning models by their carbon footprint.57
However, while disclosure for the carbon footprint of training of models is becoming more commonplace, figures for inference are harder to come by. Very few services that use AI models disclose any per usage figures. Until the companies with access to the data disclose figures, we are reliant on tools that make estimates “from the outside” again.
Gen AI Impact’s open source EcoLogits project is currently the best example we have found of a tool that provides usage-based estimates for the use of inference from the largest AI services and can be included into AI projects. The team clearly document their approach,58 as well as where they have made assumptions, and where limits are to their approach. They also offer a calculator for very quick estimates.59
Ultimately, if you consume AI powered services and want to understand your likely impact from using them, you’ll probably need to request figures from vendors, as they are best placed to provide them.
There are also reasons to request these figures from a regulatory point of view. The European AI Act has mandated the publishing of information about the environmental impact of creating foundational models, with significant penalties for non compliance. This is likely a significant factor in Meta’s recent LLama 3 model being published with a model card containing environmental impact information and links to clear methodologies.
Other legislation like the Corporate Sustainability Reporting Directive (CSRD) in Europe mandates the reporting from 2025 onwards about the environmental footprint of organisations and their operations—including their supply chains. If activity by an organisation is considered large enough to count as being “material” to their reported carbon footprint, then it either needs to be included in the reporting or the organisation needs to show how they decided something was not material to their impact. Either way, deciding whether an activity is material to reporting is difficult to do without access to the underlying data, and this is data that we know exists.
4. Changing your choice of AI model and task impacts the footprint
If you know that it is possible to estimate the footprints of different AI models,60 then a logical next step might be to ask yourself if one model might be a better choice than another. The short answer is yes. It is possible to determine if one model is better than another. It’s also useful to know that some types of tasks tend to be more resource intensive than others.
Different tasks require different amounts of energy
Once again, while there are new projects to benchmark various AI activities, this is a developing field. If we want to understand the relative resource impact of different AI tasks, we can look to recently published work by AI researchers. Published in December 2023, Power Hungry Processing: Watts Driving the Cost of AI Deployment?61 provides useful, independent numbers in the public domain for the first time.
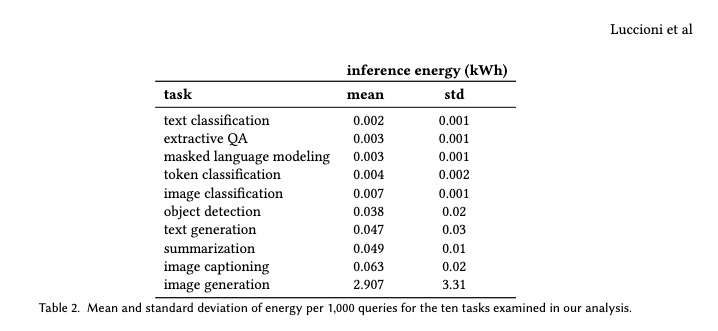
This tells us that using AI to summarise some text probably doesn’t use more energy than carrying out a search on Google or Bing. But using AI to generate an image might use as much energy as recharging your phone.62 Do bear in mind these figures help us understand the inference (usage) part of the lifecycle. But they don’t take into account the other parts of the lifecycle. Therefore these figures should be viewed as an incomplete picture of impact.
For the same task different models can use different amounts of energy
Once we’ve an idea of how impactful a specific task might be, there’s scope to reduce the impact through careful choice of models for a specific task. Research shows how much this can vary.
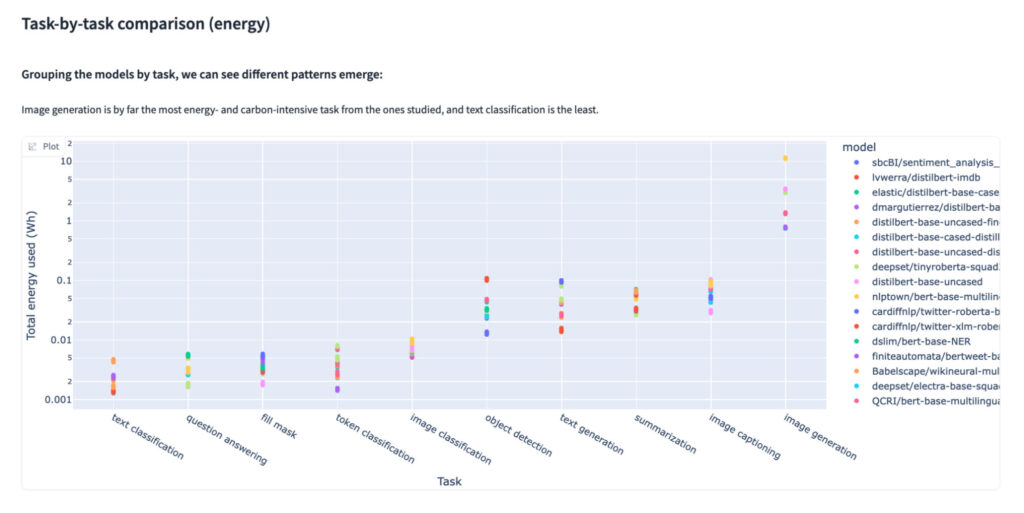
This chart can be overwhelming at first glance, so let’s focus on the figures for a single task: image generation listed on the far right. For this, we can see the energy use varies from 11 KWh per image for the Stable diffusion model to 0.7KWh for the tiny-sd model. This is a 15x difference. Both these models are doing the same task, producing an image.
Therefore supplier choice matters as not all models impact in the same way. Some organisations are paying more attention to this than others and talking openly about the work they’re doing in this field. A good example of a large firm working in the open is Salesforce.64 They publish impact figures for their own models and also write about their own efforts.65 While it is in its early stages, the Energy Star AI project66 is an interesting initiative to make the benchmarking of models accessible and actionable with early buy-in from companies like Salesforce.
The key takeaway here is that reducing the impact of AI isn’t just applicable to those creating models. As users of these models, if we can gather enough data to discern the differences between them, we can make better choices over which has less impact.
5. Any AI code can be run in ways that reduce the footprint
Finally, even if we’re not able to choose the models we use, there are still a few options to reduce the impact of AI. The emissions of an AI model are not just dependent on the quantity of electricity used, but also where the electricity comes from. Carbon intensity is a standard way of talking about this.
Cleaner electricity produced by renewable sources has a lower carbon intensity. This means that for every unit of electricity produced there are fewer emissions. On the flip side, electricity produced by burning fossil fuels is more polluting and has a higher carbon intensity.
In reality, most of any given region’s electricity comes from a variety of sources. The proportion produced by renewables, fossil fuels and nuclear changes based on many factors. This causes the carbon intensity of electricity to fluctuate, which can be used as an advantage. Let’s look at an example of this in an AI context. The BLOOM model mentioned previously is similar in size and complexity to the model used in OpenAI’s Chat-GPT, GPT-3. However, BLOOM resulted in almost 20 times lower carbon emissions. How? By using different hardware to reduce the energy consumption and running the computation in a place with lower carbon intensity power.

This diagram tells us a few useful things:
- You can reduce the impact through specifying the location of a data centre
- You can reduce the impact through choice of hosting provider
Let’s unpack each of these in turn.
You can reduce the impact through specifying the location of a data centre
In different parts of the world, the electricity powering a data centre will have varying carbon intensities. In Poland or India there is a higher proportion of fossil fuels like coal generating electricity than compared to the UK. Therefore, all things being equal, the same model will have a higher carbon footprint if run in a Polish or Indian data centre over a British equivalent.
Why is this? Using the same AI model will be performing the same task running on the same hardware but the task runs in a ‘cleaner’ region, using cleaner energy, so the carbon footprint will be lower. A growing number of data centre vendors provide this information to users now to aid decision making. The Green Software Foundation has a compiled list of the carbon intensity of power use in every single region of Microsoft, Amazon, and Google’s cloud services, as part of their the Real Time Energy and Carbon Standard for Cloud Providers project 67, lead by Adrian Cockroft and Pindy Bhullar. The Green Web Foundation is a contributing member to this project.
You can reduce the impact through choice of hosting provider
Not everyone can choose to run AI computation in the greenest grids on earth, and there are many valid reasons for not automatically choosing to move computing workloads to far flung destinations. For example, some data has to stay inside national borders for compliance reasons. Faced with this, choice of vendor matters once again as in some organisations sustainability has a higher priority than others.
On the same grid, with the same model, and the same amount of computation to carry out, vendor choice can make a difference. There may be providers who are prioritising a circular first approach and looking beyond just procuring green energy.
In the UK, Deepgreen68 is an example. They have built a business around placing micro data centres in places where the heat generated by computation is an asset rather than a liability. In addition to running on cleaner power, they site their servers in buildings where the heat goes towards heating swimming pools via heat exchangers rather than requiring fresh water to be consumed for cooling. This saves energy but also saves on water and gas needed for heating.
Recommendations: 3 actions for every business when considering using AI
The best solutions to every problem start with a grounding in the wider context and what contributes to causing issues in the first place. Above, we outlined five key topic areas we think you need to know to get you started. Armed with this knowledge, the next logical question is what can I do with it?
Here we outline three actions you can take to make a difference.
1. Question your use of AI ➡️ Know when to use it
It may seem obvious, but the best way to reduce the environmental harm resulting from the AI is to only use for purposes it’s well suited to.
The world of AI is full of the promise of endless productivity and efficiency, but it rarely lives up to the hype. Therefore, ask careful questions about whether AI automation will really solve your business problems, or if it is destined to become another failed digital transformation. Can you balance the trade-off between increasing your share of carbon emissions and the potential productivity gains?
Avoiding the use of AI
A growing number of companies, like Zulip,69 Procreate,70 and others are explicitly making a point of not using LLMs or AI as part of their products. These are not usually on environmental grounds but instead revolve around other ethical concerns. This is similar to how a number of firms made public statements about steering clear of cryptocurrencies and blockchains. Another movement in this space is Not Made by AI, aimed at those who wish to promote their content as AI-free.
Resources
Here is our curated list of resources aimed at guiding you through these questions:
- Careful Industries, based in the UK, is an ethical research consultancy offering quality services to businesses wishing to navigate AI. They provide training, tools and workshops for developing socially responsible and have experience working at a policy-making level.
- MySociety’s own AI policy is one of the best and clearest examples for a technology led non-profit. They also blog about how they’ve used it to inform decisions on climate projects like CAPE.
- RAND Corporation’s Avoiding the Anti-Patterns of AI report covers common ways AI projects go wrong, identifying mitigating strategies and areas to focus on first, before reaching for AI to solve a poorly understood problem.
- The Ada Lovelace Institute’s document AI Assurance – Assessing and Mitigating risks across the AI lifecycle offers a relatively concise explanation of the different interventions organisations might make at different states of the lifecycle of project.
- The MIT Risk Repository is a very thorough resource. It contains the AI Risk Database which captures 700+ risks extracted from 43 existing frameworks, the Causal Taxonomy of AI Risks classifies how, when, and why these risks occur and The Domain Taxonomy of AI Risks classifies these risks into seven domains (e.g., “Misinformation”) and 23 subdomains (e.g., “False or misleading information”). This is a great timesaver and much faster than trawling the web yourself to find them.
2. Optimise AI use ➡️ Use it responsibly
If you do decide AI is the right choice for your specific task, spend time choosing responsible suppliers. As we’ve detailed, not all AI is created equally. There are already ways that suppliers can make different choices to reduce this impact. Here’s a summary of how you can (or can’t) mitigate the environmental harms when choosing to use AI.
NB Organisations who are users of AI through SaaS models, e.g. use AI services others provide or choose to host AI tools using third-party services such as cloud services are likely to find this table most useful.
| Area of choice | SaaS users of AI can change? | Self-hosting users of AI can change? | Notes | What systemic changes would make this easier or possible? |
| Your choice of model for a specific task | ✅ | ✅ | It’s possible to use model cards to support decision making. Hop to “For the same task different models can use different amounts of energy” for the detail. | More funding and guidance for how to estimate and disclose reliable figures. Strong enforcement of the new laws in the AI Act that require transparency for using models (inference), not just training them. Notable organisations in this space: European AI & Society Fund; AI Now Institute; Data & Society. |
| Your choice of hosting provider | ❌ | ✅ | It’s possible to use model cards to support decision making. Hop to “For the same task different models can use different amounts of energy” for the detail. | Better incentives to create a circular economy for hardware. Policy to support community outcomes eg reducing community harms (massive water use in areas of drought) and share the good things (heat, grid capacity and resilience). Support alternatives to monopoly. Notable organisations in this space: Open Compute; Critical Infrastructure Lab; Common Wealth; |
| Your choice of data centre location | ❌ | ✅ | For using AI tools provided by others, your options are limited to asking questions of suppliers, not affecting direct change yourself. Some model cards do provide this openly. If you are self-hosting AI tools, many hosting providers operate data centres in multiple locations and you can choose between them. Hop to “Reduce the impact through specifying the location of a data centre” for the detail. | Whilst it’s possible you can get this information, it could be a lot easier and more transparent. In Europe, the Energy Efficiency Directive and related laws have compelled firms to compile information at a datacentre level about their water usage, how clean the energy they use is, and a host of other relevant datapoints. In some cases this data is in the public domain. Where it isn’t you, can request it. We we intend to surface this in the Green Web Directory as it becomes widely and consistently available. |
| Your choice of hardware supplier | ❌ | ❌ | Hardware supplier is typically a choice made by a hosting provider. That said, the market is currently dominated by Nvidia, and there’s little choice in reality. In the current structure, the power imbalance means the main providers have enough leverage to refuse to provide transparency on emissions. Nvidia has not published information beyond power usage. Other providers like AMD are entering the market – they have not published much information either. Large tech firms are building their own specialised hardware, but do not have an encouraging history of disclosure. | Address the consolidation that exists within hardware manufacturing. Support / mandate interoperability at the hardware software layer, i.e, support alternatives Nvidia’s CUDA software allowing competition on transparency. Apply lessons from other sectors where public subsidies come with concessions on societally important factors (prevailing wages, environmental disclosure, etc). A high profile example would be the progressive set of measures used in the US Inflation Reduction Act. |
Introduction of AI features to tools you already use. | ❌ | ❌ | More software is coming bundled with AI. Google Maps is one example, but there are many more. You can ask suppliers for ways to opt out, if you know it’s there in the first place. | Force an explicit opt-in, and disclosure to be required. There are some precedents with the GDPR on the right to restrict processing (though focussed on personal data)71, and the FTC’s rulings on secondary use of personal data to train algorithms72 |
3. Prioritise getting estimates of AI’s footprint ➡️ Ask for your usage data from suppliers
Landmark AI-focused legislation like the EU’s AI Act has made progress in this area. It places an emphasis on reducing the consumption of energy and ‘other resources consumption’ for high-risk AI systems and just on energy-efficient development for general-purpose AI models. Both are expected to include training and usage (inference). This is already making changes in the data that’s available, but many argue it was a missed opportunity.73
The good news is there’s further EU legislation that will provide a much needed push for organisations to report on useful data on their environmental impact, such as the Corporate Sustainability Reporting Directive (CSRD) and Energy Efficiency Directive (EED). The EED mandates that every data centre above a certain size in Europe will need to collect absolute figures for water usage, energy consumption, and renewable energy share.74
What to ask for
Firstly, insist on as much transparency as possible. Even with the best of intentions, estimating digital emissions is loaded with assumptions. Request clarity around the methodology used and data sources. note: We’re currently working on sample language to add to commercial agreements to request this – drop us a line if you’d like to collaborate with us.
Ask for location-based and market-based figures for the use of AI services. A location-based method reports what an organisation is physically putting into the air, in other words its “real” emissions. The market-based approach shows what an organisation is responsible for through its purchasing decisions, such as a renewable energy contract. The results can be very different, and there are significant issues associated with only using market-based numbers.
You might also consider writing disclosure clauses into agreements like how large providers do with their suppliers, such as the Salesforce sustainability exhibit.75
Making your own estimates
In the absence of data from suppliers, you may need to estimate these numbers in order to comply. If you need a guiding hand to get you started, we offer technical expertise as well as tailored guidance on the above recommendations.
Acknowledgements
This report is made available under a Creative Commons Attribution 4.0 International (CC BY SA 4.0) licence. For media or other inquiries please get in touch.
Special thanks to all those whose insights and feedback contributed to this report: Boris Gamazaychikov, Holly Alpine, Justin Mason, Carole Touma, Melissa Hsiung, Tamara Kneese, David Rees, and amongst others, members of climateAction.tech community who provided feedback anonymously.
Suggested citation
Smith, H & Adams, C (2024): Thinking about using AI? Here’s what you can and (probably) can’t change about its environmental impact. Green Web Foundation 2024.
Footnotes
- Dartmouth Summer Research Project on Artificial Intelligence. ↩︎
- ChatGPT website ↩︎
- ChatGPT take two months to reach 100 million users ↩︎
- ElPais: ChatGPT achieves in six months what Facebook needed a decade to do: The meteoric rise of the AI chatbot ↩︎
- Paper from Google Research, Attention Is All You Need introducing the Transformer Architecture for Machine learning.
↩︎ - Google’s website introducing its Palm2 model, as well as coverage from Ars Technica and ZDNet’s coverage of Google I/O event.. ↩︎
- Meta’s Llama Series of models are not released under an open source licence, and have some restrictions, but are freely downloadable, and many companies are using them in their own services. See more on their Llama Ecosytstem website. ↩︎
- Commentary from Semi Analysis around “We have no moat, and Neither does OpenAI” – leaked internal Google memo warning Open Source AI Will Outcompete Google and OpenAI ↩︎
- Historical and project capital expenditure charts from the linked Financial Times article ↩︎
- CNN: Nvidia surpasses Microsoft to become the largest public company in the world ↩︎
- Reuters: Nvidia loses top spot to Microsoft after 3% drop ↩︎
- Numbers collected by Django co-founder and AI researcher Simon Willison, referencing multiple news outlets. ↩︎
- Goldman Sachs Report – Gen AI: too Much spend, too little benefit? ↩︎
- Lessons from History: The Rise and Fall of the Telecom Bubble – detailing the similarities and difference in AI and network capacity build out ↩︎
- See Boston Consulting Group’s November 2023 report – How AI Can Speed Climate Action ↩︎
- See Sustainability Magazine – Accenture: How Gen AI can Accelerate Sustainability ↩︎
- Research from RAND – The Root Causes of Failure for Artificial Intelligence Projects and How They Can Succeed ↩︎
- CNN: Has the AI bubble burst? Wall Street wonders if artificial intelligence will ever make money ↩︎
- CNN: Has the AI bubble burst? Wall Street wonders if artificial intelligence will ever make money ↩︎
- The Chronic Potentialitis of Digital Enablement, and the specific references to GeSI’s reports from 2008 through 2019 as well as the forecast enablement of sustainable activity, compared to the validates enablement. ↩︎
- Towards a Fossil-Free Internet: The Fog of Enactment ↩︎
- In 2022, the Microsoft VP of Energy committed to providing a breakdown to its sustainability community of the energy division’s activity across six different sectors, from oil and gas extraction to low- or zero-carbon energy, as well as an analysis of personnel resources assigned to extractive industries versus renewable energy. As of Sept 2024, nothing has been shared. Grist: Microsoft employees spent years fighting the tech giant’s oil ties. Now, they’re speaking out. ↩︎
- Global AI software spending in the oil and gas market is forecast to increase 24.3% in 2024 to $1.5 billion and reach $2.9 billion by 2027 – Gartner – Compare AI Software Spending in the Oil and Gas Industry, 2023-2027 ↩︎
- Survey referenced on page taken down, but available on the Internet Archive. – EY: Applying AI in oil and gas ↩︎
- See Karan Hao in the Atlantic: Microsoft’s hypocrisy on AI ↩︎
- See Alex Steffen on Predatory Delay and the Rights of Future Generations ↩︎
- Environment Variables – The Week in Green Software: Net Zero Cloud ↩︎
- ABN Amro sustainability reports ↩︎
- IEA Electricity 2024 report ↩︎
- Semi Analysis: AI data centre Energy Dilemma – Race for AI data centre Space and Semi Analysis’s Accelerator Industry Model ↩︎
- Joule: Commentary – The growing energy footprint of artificial intelligence – Alex De Vries ↩︎
- ChatCO2 – Safeguards Needed For AI’s Climate Risks – Greenpeace ↩︎
- In the USA, where the most the datacenter capacity is located, it tends to be in areas with easy access to gas or coal, like North Virginia. At a national level, fossil generation from coal and gas still makes up most of the electricity generation in the USA. China likely the nation with the next highest amount of data centre capacity also has a coal-heavy grid. For more, see SemiAnalysis: AI Datacenter Energy Dilemma – Race for AI Datacenter Space, and Ember Climate’s grid intensity explorer. ↩︎
- Datacenter Dynamics: AWS, Digital Realty, Google, Meta, Microsoft, and Schneider Electric call for greater supplier transparency on Scope 3 emissions ↩︎
- Sustainable data centers require sustainable construction – Data Centre Dynamics* ↩︎
- Tahoe Reno Exascale data centre ↩︎
- Making AI Less “Thirsty”: Uncovering and Addressing the Secret Water Footprint of AI Models ↩︎
- Water wars: Court halts Google data center in Chile amid climate controversy ↩︎
- In the town of the Dalles, Oregon, it only emerged at more than a quarter of the town’s water was being used by Google after a 13 month legal fight to keep this information being published. See Oregon Live: Google’s water use is soaring in The Dalles, records show, with two more data centers to come ↩︎
- US Energy Information Administration: `U.S. thermoelectric plants are the largest source of U.S. water withdrawals, accounting for more than 40% of total U.S. water withdrawals in 2015. ↩︎
- See Materals Today: The significance of product design in the circular economy: A sustainable approach to the design of data centre equipment as demonstrated via the CEDaCI design case study ↩︎
- Closing the Loop on the World’s Fastest-growing Waste Stream: Electronics ↩︎
- Top 10 Most Poisonous Places on Earth Off Limits to Humans ↩︎
- Nvidia’s recent H100 AI accelerators hardware offers more performance per watt than predecessors, but also consumers significantly higher amounts of power. For more, see DataCentre Knowledge: Nvidia’s H100 – What It Is, What It Does, and Why It Matters ↩︎
- Stack infrastructure, a supplier to large hyperscaler providers, publicly announced they are working on designs to support up to 300kW of power draw for AI workloads. ↩︎
- See CNBC: Elon Musk’s xAI accused of worsening Memphis smog with unauthorized gas turbines at data center ↩︎
- Irish Business Post: Microsoft secures planning for €100m gas plant to power data centre ↩︎
- the Register: Surging datacenter power demand slows the demise of US coal plants ↩︎
- Scientific American: Coal Power Kills a ‘Staggering’ Number of Americans ↩︎
- Latitude Media: Transition AI – Can the Grid Handle AI’s Power Demand? ↩︎
- Stand.Earth – Ctrl-Alt-Incomplete: The Gaps in Microsoft’s Climate Leadership, ↩︎
- Google’s 2023 environment report, footnote 148 – “Our Scope 2 market-based emissions increased 37%, primarily due to increased data centre electricity consumption and a lack of full regional coverage of renewable energy procurement in the United States and Asia Pacific regions.” ↩︎
- Google hiring team lead to develop new net zero strategy after AI data centre energy boom ↩︎
- Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model ↩︎
- Guidance on how to disclose https://huggingface.co/docs/hub/model-cards-co2 ↩︎
- Taken from the model card for Llama 3 on Hugging face. ↩︎
- A search sorting by co2 emissions – huggingface.co/models?other=co2_eq_emissions&sort=trending ↩︎
- Ecologit methodology pages for LLM inference an example. ↩︎
- Gen AI Impact’s – AI EcoLogits Calculator uses the same Ecologits code , with various preset scenarios ↩︎
- ML Leaderboard from the ML Energy project, as an example open project. ↩︎
- Recent paper Power Hungry Processing: Watts Driving the Cost of AI Deployment? for a further details ↩︎
- MIT Technogy Review – Making an image with Generative AI uses as much energy as charging your phone ↩︎
- Data visualisation from Hugging Face: CO2 Inference Demo ↩︎
- Salesforce list their models on Hugging Face with model cards containing various data, including their resource impact. ↩︎
- The Ever-Growing Power of Small Models, for examples of Salesforce writing about using different models for the same task. ↩︎
- Light bulbs have energy ratings — so why can’t AI chatbots? On nature.com ↩︎
- Green Software Foundation – Real Time Cloud Project and working group. ↩︎
- Deep Green – use waste heat from datacentres to support local community activities – ↩︎
- Zulip blog:Self-hosting keeps your private data out of AI models ↩︎
- Procreate: AI is not our future ↩︎
- ICO – GDPR – Right to restrict processing ↩︎
- US FTC: FTC and DOJ Charge Amazon with Violating Children’s Privacy Law by Keeping Kids’ Alexa Voice Recordings Forever and Undermining Parents’ Deletion Requests ↩︎
- The EU AI Act and environmental protection: the case for a missed opportunity ↩︎
- European Energy Efficiency Directive published, with mandatory data center reporting ↩︎
- Salesforce Urges Suppliers to Reduce Carbon Emissions, Adds Climate to Contracts ↩︎