Functions of Distributed Database System
Last Updated :
11 Jul, 2025
Distributed database systems play an important role in modern data management by distributing data across multiple nodes. This article explores their functions, including data distribution, replication, query processing, and security, highlighting how these systems optimize performance, ensure availability, and handle complexities in distributed computing environments.
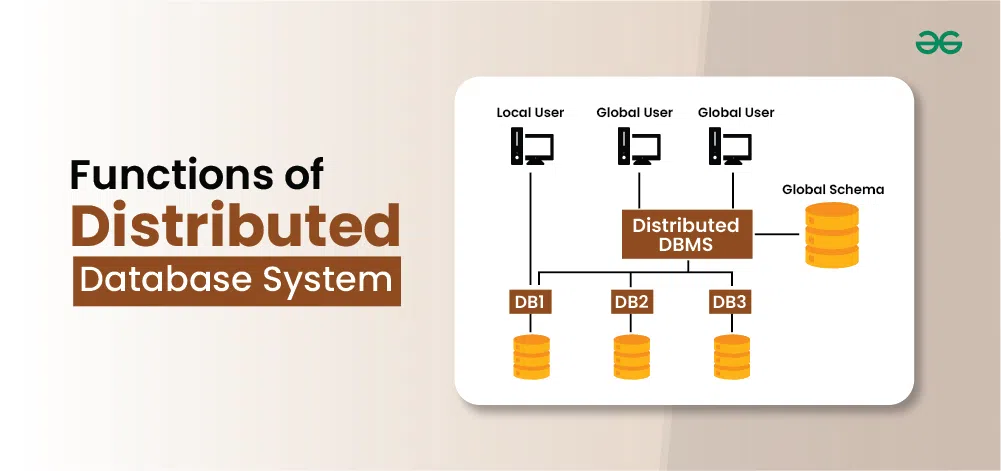 Functions of Distributed Database System
Functions of Distributed Database SystemImportant Topics for Functions of Distributed Database System
What is a Distributed Database System?
A distributed database system refers to a collection of multiple, interconnected databases that are physically dispersed across different locations but function as a single unified database. This system allows for data to be stored, accessed, and managed across multiple sites, providing several advantages over centralized or single-site databases.
Importance of Distributed Database Systems
Distributed database systems are important for several reasons, especially in the context of modern computing environments and data-intensive applications. Here are the key reasons why distributed database systems are significant:
- Scalability:
- Distributed database systems provide the ability to scale horizontally by adding more nodes or servers to the system.
- This allows organizations to handle increasing volumes of data and transaction loads without compromising performance.
- Scalability is crucial for applications that experience rapid growth or fluctuating demands.
- High Availability:
- By distributing data across multiple nodes and locations, distributed databases enhance availability.
- Even if one node or data center experiences a failure or outage, the rest of the system can continue to operate, ensuring that applications remain accessible and responsive.
- This is critical for mission-critical applications and services that require uninterrupted operation.
- Fault Tolerance:
- Distributed databases employ redundancy and replication techniques to ensure fault tolerance.
- Data is replicated across multiple nodes, so if one node fails, there are backups available on other nodes.
- This redundancy minimizes the risk of data loss and downtime, thereby enhancing system reliability.
Data Distribution in Distributed Database System
Data distribution refers to the process of distributing data across multiple nodes or locations in a distributed database system. This distribution can be based on various criteria such as:
- Horizontal Distribution:
- Also known as horizontal partitioning, this involves dividing a table into multiple partitions (or fragments) based on rows.
- Each partition contains a subset of the rows from the original table.
- For example, a customer database might be horizontally partitioned based on geographic regions, with each partition containing customers from a specific region.
- Vertical Distribution:
- Also known as vertical partitioning, this involves dividing a table into multiple partitions based on columns.
- Each partition contains a subset of columns from the original table.
- Vertical partitioning is useful when different columns are frequently accessed together, allowing those columns to be stored together on the same nodes.
- Hybrid Distribution:
- In some cases, a combination of horizontal and vertical partitioning may be used to optimize data storage and access patterns.
- This hybrid approach allows for flexibility in managing large datasets by combining the benefits of both horizontal and vertical partitioning strategies.
Fragementation in Distributed Database System
Data fragmentation involves breaking down a database into smaller pieces or fragments that can be distributed across different nodes in a distributed database system. Fragmentation can be classified into different types:
- Horizontal Fragmentation: Dividing a table into disjoint subsets of rows, where each subset is stored on a different node. Horizontal fragmentation is useful for distributing data based on criteria such as location, customer segment, or time period. It enhances parallelism and can improve query performance by reducing the amount of data accessed for each query.
- Vertical Fragmentation: Dividing a table into disjoint subsets of columns, where each subset is stored on a different node. Vertical fragmentation is beneficial when different subsets of columns are frequently accessed together in queries. It reduces data redundancy and improves storage efficiency by storing only the necessary columns on each node.
Replication and Data Consistency in Distributed Database System
Replication and Data Consistency are critical concepts in distributed database systems, addressing how data is replicated across multiple nodes and ensuring that all replicas maintain consistent and accurate data. Here’s an explanation of each:
1. Replication
Replication in distributed database systems involves creating and maintaining copies (replicas) of data on multiple nodes (servers or locations) within a network. The primary goals of replication are to enhance data availability, fault tolerance, and performance. Replication can be categorized into different types:
- Full Replication: Every data item is replicated on every node in the distributed system. This ensures high availability and fault tolerance because any node can serve data even if others fail. However, it increases storage and update overhead.
- Partial Replication: Only certain data items or subsets of data are replicated across nodes. This approach can be more efficient in terms of storage and update propagation but requires careful planning to ensure critical data availability.
Data Consistency refers to ensuring that all replicas of a data item or database reflect the same value at any given time. In distributed database systems, maintaining consistency across replicas is challenging due to factors like network latency, node failures, and concurrent updates. Consistency models define how updates are propagated and how consistent data appears to users:
- Strong Consistency: Requires that all replicas reflect the most recent update before any read operation. This ensures that all read operations return the latest committed data but can introduce higher latency and coordination overhead.
- Eventual Consistency: Allows replicas to diverge temporarily but guarantees that they will converge to the same state eventually, without requiring immediate synchronization. Eventual consistency improves availability and performance but may lead to temporary inconsistencies in read operations.
Query Processing in Distributed Database System
Query processing refers to the process of translating a user query (written in a high-level language like SQL) into a series of operations that can be executed by the distributed database system to retrieve the requested data. In a distributed environment, query processing typically involves the following steps:
- Query Parsing and Analysis:
- The query is parsed to check syntax and semantics, ensuring it conforms to the database schema and rules.
- Query analysis determines how the query should be executed, considering factors like data distribution, availability of indexes, and potential optimizations.
- Query Decomposition and Distribution:
- The query is decomposed into sub-queries that can be executed on different nodes or fragments of data.
- Distribution decisions are made based on data locality, availability of indexes, and network latency to minimize data movement and optimize query execution.
- Parallel Execution:
- Sub-queries are executed in parallel across distributed nodes to leverage the computational power of multiple nodes simultaneously.
- Coordination mechanisms, such as synchronization points or distributed locks, may be used to ensure consistent query results across nodes.
- Data Integration and Result Consolidation:
- Results from individual nodes are integrated or consolidated to form the final result set of the query.
- Techniques like merging, sorting, and filtering are applied to combine results while maintaining data consistency and correctness.
Query Optimization in Distributed Database System
Query optimization aims to improve the efficiency and performance of query processing by minimizing resource consumption (such as CPU, memory, and network bandwidth) and reducing query response time. In distributed database systems, query optimization strategies include:
- Parallelization:
- Exploits parallel processing capabilities of distributed nodes to execute query operations concurrently.
- Partitioning strategies divide data and query operations into smaller tasks that can be executed in parallel, leveraging distributed computing resources effectively.
- Indexing and Data Distribution:
- Uses indexes (such as B-trees, hash tables) to facilitate efficient data access and retrieval.
- Optimizes data distribution and placement across nodes to minimize data movement and reduce query response time.
- Join Strategies:
- Optimizes join operations (like nested loops join, hash join, or merge join) to minimize the number of data transfers and improve join performance in distributed environments.
- Considers data distribution and join selectivity to determine the most efficient join strategy for distributed data sets.
- Caching and Materialized Views:
- Utilizes caching mechanisms to store intermediate results or frequently accessed data, reducing the need for recomputation and improving query response time.
- Materialized views precompute and store results of frequently executed queries, accelerating query processing for common data retrieval patterns.
Distributed Database Security
Distributed database security encompasses the measures and strategies implemented to protect data integrity, confidentiality, and availability in a distributed computing environment where data is spread across multiple nodes or locations. Here's a detailed explanation of distributed database security. Key aspect of distributed database security include:
- Data Confidentiality:
- Encryption: Data encryption techniques, such as AES (Advanced Encryption Standard) or RSA (Rivest-Shamir-Adleman), are used to protect data from unauthorized access during storage and transmission across distributed nodes.
- Access Control: Implementing access control mechanisms, including role-based access control (RBAC) or attribute-based access control (ABAC), ensures that only authorized users or applications can access sensitive data.
- Data Integrity:
- Checksums and Hashing: Using checksums or cryptographic hashing algorithms (e.g., SHA-256) to verify data integrity and detect any unauthorized modifications or tampering of data.
- Digital Signatures: Applying digital signatures to data transactions to ensure authenticity and non-repudiation, confirming that data originates from a legitimate source and has not been altered.
- Authentication and Authorization:
- Authentication: Verifying the identity of users or applications accessing the distributed database through methods like passwords, biometrics, or multi-factor authentication (MFA).
- Authorization: Granting appropriate permissions and privileges to authenticated users based on their roles or specific access rights, ensuring that they can only access data relevant to their responsibilities.
- Secure Communication:
- Transport Layer Security (TLS): Implementing TLS protocols to encrypt data transmitted between distributed nodes, protecting it from interception or eavesdropping during transmission over insecure networks.
- Virtual Private Networks (VPNs): Establishing secure VPN connections to create encrypted tunnels for data communication between distributed nodes, enhancing network security and privacy.
- Auditing and Logging:
- Audit Trails: Maintaining comprehensive audit trails of data access, modifications, and transactions across distributed nodes to monitor and track user activities.
- Logging: Recording security-related events and incidents, including unauthorized access attempts or data breaches, to facilitate forensic analysis and compliance with regulatory requirements.
Similar Reads
DBMS Tutorial – Learn Database Management System Database Management System (DBMS) is a software used to manage data from a database. A database is a structured collection of data that is stored in an electronic device. The data can be text, video, image or any other format.A relational database stores data in the form of tables and a NoSQL databa
7 min read
Basic of DBMS
Entity Relationship Model
Introduction of ER ModelThe Entity-Relationship Model (ER Model) is a conceptual model for designing a databases. This model represents the logical structure of a database, including entities, their attributes and relationships between them. Entity: An objects that is stored as data such as Student, Course or Company.Attri
10 min read
Structural Constraints of Relationships in ER ModelStructural constraints, within the context of Entity-Relationship (ER) modeling, specify and determine how the entities take part in the relationships and this gives an outline of how the interactions between the entities can be designed in a database. Two primary types of constraints are cardinalit
5 min read
Generalization, Specialization and Aggregation in ER ModelUsing the ER model for bigger data creates a lot of complexity while designing a database model, So in order to minimize the complexity Generalization, Specialization and Aggregation were introduced in the ER model. These were used for data abstraction. In which an abstraction mechanism is used to h
4 min read
Introduction of Relational Model and Codd Rules in DBMSThe Relational Model is a fundamental concept in Database Management Systems (DBMS) that organizes data into tables, also known as relations. This model simplifies data storage, retrieval, and management by using rows and columns. Codd’s Rules, introduced by Dr. Edgar F. Codd, define the principles
14 min read
Keys in Relational ModelIn the context of a relational database, keys are one of the basic requirements of a relational database model. Keys are fundamental components that ensure data integrity, uniqueness and efficient access. It is widely used to identify the tuples(rows) uniquely in the table. We also use keys to set u
6 min read
Mapping from ER Model to Relational ModelConverting an Entity-Relationship (ER) diagram to a Relational Model is a crucial step in database design. The ER model represents the conceptual structure of a database, while the Relational Model is a physical representation that can be directly implemented using a Relational Database Management S
7 min read
Strategies for Schema design in DBMSThere are various strategies that are considered while designing a schema. Most of these strategies follow an incremental approach that is, they must start with some schema constructs derived from the requirements and then they incrementally modify, refine or build on them. What is Schema Design?Sch
6 min read
Relational Model
Introduction of Relational Algebra in DBMSRelational Algebra is a formal language used to query and manipulate relational databases, consisting of a set of operations like selection, projection, union, and join. It provides a mathematical framework for querying databases, ensuring efficient data retrieval and manipulation. Relational algebr
9 min read
SQL Joins (Inner, Left, Right and Full Join)SQL joins are fundamental tools for combining data from multiple tables in relational databases. For example, consider two tables where one table (say Student) has student information with id as a key and other table (say Marks) has information about marks of every student id. Now to display the mar
4 min read
Join operation Vs Nested query in DBMSThe concept of joins and nested queries emerged to facilitate the retrieval and management of data stored in multiple, often interrelated tables within a relational database. As databases are normalized to reduce redundancy, the meaningful information extracted often requires combining data from dif
3 min read
Tuple Relational Calculus (TRC) in DBMSTuple Relational Calculus (TRC) is a non-procedural query language used to retrieve data from relational databases by describing the properties of the required data (not how to fetch it). It is based on first-order predicate logic and uses tuple variables to represent rows of tables.Syntax: The basi
4 min read
Domain Relational Calculus in DBMSDomain Relational Calculus (DRC) is a formal query language for relational databases. It describes queries by specifying a set of conditions or formulas that the data must satisfy. These conditions are written using domain variables and predicates, and it returns a relation that satisfies the specif
4 min read
Relational Algebra
Introduction of Relational Algebra in DBMSRelational Algebra is a formal language used to query and manipulate relational databases, consisting of a set of operations like selection, projection, union, and join. It provides a mathematical framework for querying databases, ensuring efficient data retrieval and manipulation. Relational algebr
9 min read
SQL Joins (Inner, Left, Right and Full Join)SQL joins are fundamental tools for combining data from multiple tables in relational databases. For example, consider two tables where one table (say Student) has student information with id as a key and other table (say Marks) has information about marks of every student id. Now to display the mar
4 min read
Join operation Vs Nested query in DBMSThe concept of joins and nested queries emerged to facilitate the retrieval and management of data stored in multiple, often interrelated tables within a relational database. As databases are normalized to reduce redundancy, the meaningful information extracted often requires combining data from dif
3 min read
Tuple Relational Calculus (TRC) in DBMSTuple Relational Calculus (TRC) is a non-procedural query language used to retrieve data from relational databases by describing the properties of the required data (not how to fetch it). It is based on first-order predicate logic and uses tuple variables to represent rows of tables.Syntax: The basi
4 min read
Domain Relational Calculus in DBMSDomain Relational Calculus (DRC) is a formal query language for relational databases. It describes queries by specifying a set of conditions or formulas that the data must satisfy. These conditions are written using domain variables and predicates, and it returns a relation that satisfies the specif
4 min read
Functional Dependencies & Normalization
Attribute Closure in DBMSFunctional dependency and attribute closure are essential for maintaining data integrity and building effective, organized and normalized databases. Attribute closure of an attribute set can be defined as set of attributes which can be functionally determined from it.How to find attribute closure of
4 min read
Armstrong's Axioms in Functional Dependency in DBMSArmstrong's Axioms refer to a set of inference rules, introduced by William W. Armstrong, that are used to test the logical implication of functional dependencies. Given a set of functional dependencies F, the closure of F (denoted as F+) is the set of all functional dependencies logically implied b
4 min read
Canonical Cover of Functional Dependencies in DBMSManaging a large set of functional dependencies can result in unnecessary computational overhead. This is where the canonical cover becomes useful. A canonical cover is a set of functional dependencies that is equivalent to a given set of functional dependencies but is minimal in terms of the number
7 min read
Normal Forms in DBMSIn the world of database management, Normal Forms are important for ensuring that data is structured logically, reducing redundancy, and maintaining data integrity. When working with databases, especially relational databases, it is critical to follow normalization techniques that help to eliminate
7 min read
The Problem of Redundancy in DatabaseRedundancy means having multiple copies of the same data in the database. This problem arises when a database is not normalized. Suppose a table of student details attributes is: student ID, student name, college name, college rank, and course opted. Student_ID Name Contact College Course Rank 100Hi
6 min read
Lossless Join and Dependency Preserving DecompositionDecomposition of a relation is done when a relation in a relational model is not in appropriate normal form. Relation R is decomposed into two or more relations if decomposition is lossless join as well as dependency preserving. Lossless Join DecompositionIf we decompose a relation R into relations
4 min read
Denormalization in DatabasesDenormalization is a database optimization technique in which we add redundant data to one or more tables. This can help us avoid costly joins in a relational database. Note that denormalization does not mean 'reversing normalization' or 'not to normalize'. It is an optimization technique that is ap
4 min read
Transactions & Concurrency Control
ACID Properties in DBMSIn the world of DBMS, transactions are fundamental operations that allow us to modify and retrieve data. However, to ensure the integrity of a database, it is important that these transactions are executed in a way that maintains consistency, correctness, and reliability. This is where the ACID prop
6 min read
Types of Schedules in DBMSScheduling is the process of determining the order in which transactions are executed. When multiple transactions run concurrently, scheduling ensures that operations are executed in a way that prevents conflicts or overlaps between them.There are several types of schedules, all of them are depicted
6 min read
Recoverability in DBMSRecoverability ensures that after a failure, the database can restore a consistent state by keeping committed changes and undoing uncommitted ones. It uses logs to redo or undo actions, preventing data loss and maintaining integrity.There are several levels of recoverability that can be supported by
5 min read
Implementation of Locking in DBMSLocking protocols are used in database management systems as a means of concurrency control. Multiple transactions may request a lock on a data item simultaneously. Hence, we require a mechanism to manage the locking requests made by transactions. Such a mechanism is called a Lock Manager. It relies
5 min read
Deadlock in DBMSA deadlock occurs in a multi-user database environment when two or more transactions block each other indefinitely by each holding a resource the other needs. This results in a cycle of dependencies (circular wait) where no transaction can proceed.For Example: Consider the image belowDeadlock in DBM
4 min read
Starvation in DBMSStarvation in DBMS is a problem that happens when some processes are unable to get the resources they need because other processes keep getting priority. This can happen in situations like locking or scheduling, where some processes keep getting the resources first, leaving others waiting indefinite
8 min read
Advanced DBMS
Indexing in DatabasesIndexing in DBMS is used to speed up data retrieval by minimizing disk scans. Instead of searching through all rows, the DBMS uses index structures to quickly locate data using key values.When an index is created, it stores sorted key values and pointers to actual data rows. This reduces the number
6 min read
Introduction of B TreeA B-Tree is a specialized m-way tree designed to optimize data access, especially on disk-based storage systems. In a B-Tree of order m, each node can have up to m children and m-1 keys, allowing it to efficiently manage large datasets.The value of m is decided based on disk block and key sizes.One
8 min read
Introduction of B+ TreeA B+ Tree is an advanced data structure used in database systems and file systems to maintain sorted data for fast retrieval, especially from disk. It is an extended version of the B Tree, where all actual data is stored only in the leaf nodes, while internal nodes contain only keys for navigation.C
5 min read
Bitmap Indexing in DBMSBitmap Indexing is a powerful data indexing technique used in Database Management Systems (DBMS) to speed up queries- especially those involving large datasets and columns with only a few unique values (called low-cardinality columns).In a database table, some columns only contain a few different va
3 min read
Inverted IndexAn Inverted Index is a data structure used in information retrieval systems to efficiently retrieve documents or web pages containing a specific term or set of terms. In an inverted index, the index is organized by terms (words), and each term points to a list of documents or web pages that contain
7 min read
SQL Queries on Clustered and Non-Clustered IndexesIndexes in SQL play a pivotal role in enhancing database performance by enabling efficient data retrieval without scanning the entire table. The two primary types of indexes Clustered Index and Non-Clustered Index serve distinct purposes in optimizing query performance. In this article, we will expl
7 min read
File Organization in DBMSFile organization in DBMS refers to the method of storing data records in a file so they can be accessed efficiently. It determines how data is arranged, stored, and retrieved from physical storage.The Objective of File OrganizationIt helps in the faster selection of records i.e. it makes the proces
5 min read
DBMS Practice