
I statistikk er data innsamlet informasjon i form av for eksempel tall eller svar på et avkrysningsskjema. Slik informasjon kalles kvantitativ informasjon eller kvantitative data. En samling av ulike typer kvantitativ informasjon kalles gjerne et datasett.
data (statistikk)
Ulike typer data
I faget statistikk skilles det mellom data som er registrert som tall og data som er registrert som kategorier.
Tall-data
Høydemålinger, rundetider, befolkningstall og stilkarakterer på hopp er alle eksempler på tall-data. Tall-data kalles også numeriske data.
Tall-data kan være målinger langs en sammenhengende (kontinuerlig) skala, som for eksempel målinger av høyde, vekt, volum, tid, eller penger. Da kalles de for kontinuerlige data og angis med desimaltall. Rundetider, avstander, vekt og volum er andre eksempler på kontinuerlige data, selv om de av og til registreres som heltall.
Tall-data kan også være antall og angis med heltall. I både statistikk og matematikk brukes ordet diskret (adskilt) om denne typen data. Antall barn i en familie, antall biler en person har eid, og antall beinbrudd en person har hatt, er eksempler på diskrete data. Også stilkarakterer i hopp, som kan gis som hele eller halve poeng på en skala fra 0 til 20, kan regnes som diskrete data, fordi det ikke er mulig å oppnå noe annet enn hele og halve poeng.
Kategoriske data
Informasjon kan også observeres og samles inn i form av kategorier, og dette kalles kategoriske data. Dette er spesielt vanlig i spørreundersøkelser. Kategoriene er alltid definert på forhånd, før datainnsamlingen starter.
Eksempler på spørsmål og svarkategorier som gir kategoriske data:
| Spørsmål | Svarkategorier |
|---|---|
| Bruker du noen faste medisiner? | Ο Nei Ο Ja |
| Hvilken nasjonalitet har du? | Ο Norsk Ο Annet |
| Hvilket kjønn identifiserer du deg mest med? | Ο Mann Ο Kvinne Ο Annet |
| Hvilken fugl har du observert? | Ο Pipp-pipp Ο Gakk-gakk Ο Ørn |
| Hvilket parti vil du stemme på ved neste valg? | (Liste med alle de registrerte politiske partene i Norge) |
| Hvor enig er du i følgende påstand: Alle ulver i Norge bør skytes | Ο Helt uenig Ο Litt uenig Ο Verken enig eller uenig Ο Litt enig Ο Helt enig |
Kategoriske data med to kategorier kalles også binære data eller dikotome data. «Ja-eller-nei»-spørsmål som «Ønsker du et regjeringsskifte ved neste valg?», gir binære kategoriseringer og er mye brukt i mediedebatter og meningsmålinger. Et annet vanlig eksempel er informasjon om sykdom, kategorisert som «Frisk» eller «Syk». Tradisjonelt har kjønn, med de to valgalternativene «Mann» og «Kvinne», også vært et vanlig eksempel på binære data.
Kategoriske data med flere enn to kategorier kalles enten nominale data eller ordinale data. Nominale data har flere kategorier, men det er ikke en opplagt rangering mellom kategoriene. Et eksempel på nominale data er blodtype: A, B, AB eller 0. Tilhørighet til et politisk parti er også nominale data, selv om de politiske partiene i Norge ofte sorteres etter en grov venstre-høyre-akse. Biltype, med kategoriene «Bensinbil», «Dieselbil», «Elbil» og «Hybrid» er et annet eksempel. Dersom valgalternativene for kjønn defineres som «Mann», «Kvinne» og «Annet», vil også informasjon om kjønn være nominale data.
Ordinale data er også kategoriske data med flere enn to kategorier. Men i motsetning til de usorterte kategoriene hos nominale data, har de ordinale dataene en naturlig rangering av kategoriene. Et eksempel er svaret på spørsmålet «Hvor enig er du i følgende på stand: Alle ulver i Norge bør skytes.», med svaralternativene «Helt uenig», «Litt uenig», «Verken enig eller uenig», «Litt enig» og «Helt enig». Karakterer på ungdomsskolen er et annet eksempel på ordnede kategorier, selv om kategoriene blir gitt tallverdier.
Behandling av ulike data
Statistikk handler i stor grad om å presentere og analysere eksisterende data. Ulike typer data må både oppsummeres og analyseres ulikt.
Oppsummering av kontinuerlige data
Kontinuerlige data blir ofte presentert i et histogram eller et boksplott. De kan også presenteres ved hjelp av de beskrivende tallene gjennomsnitt og standardavvik (hvis fordelingen av verdier er relativt symmetrisk), eller median og kvartiler (hvis verdiene er skjevfordelte).
Eksempel på symmetrisk fordeling
Høyden til norske ungdommer ved ulike aldre er et eksempel på data som er rimelig symmetrisk fordelt.
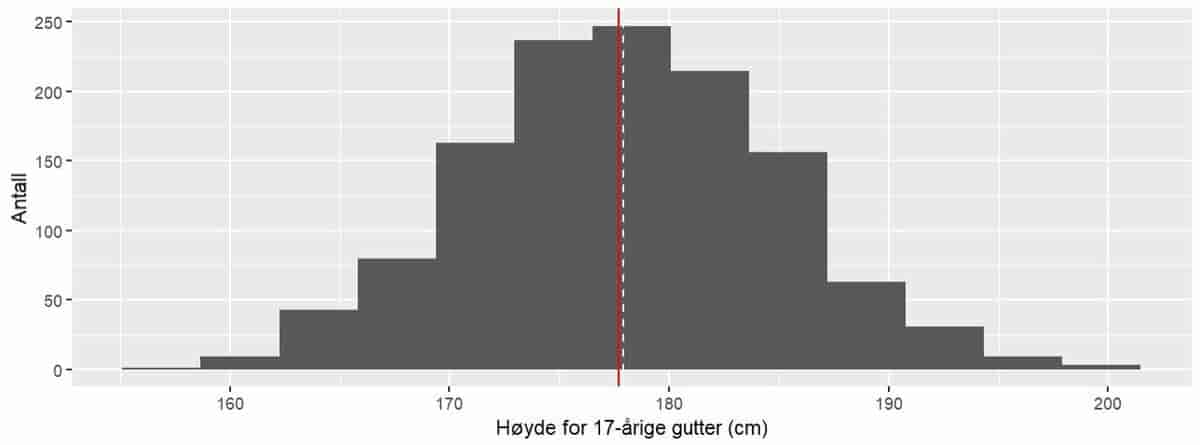
Høydefordelingen for 1257 norske, 17-årige gutter (simulerte data, basert på percentilskjema for vekst). Gjennomsnittshøyden er 177,9 cm, og den finner du der den hvite, stiplede linjen treffer x-aksen. Medianhøyden er 177,7 cm, og den finner du der den røde, heltrukne linjen treffer x-aksen. Figuren viser et eksempel på at gjennomsnittsverdien og medianverdien kan være ganske like i symmetriske fordelinger.
Eksempel på skjev fordeling
Responstiden til ambulanser i ulike kommuner er et eksempel på skjevfordelte data. Responstiden er tiden det tar fra en telefon mottas på en nødsentral, til ambulansen er fremme hos den som trenger hjelp.
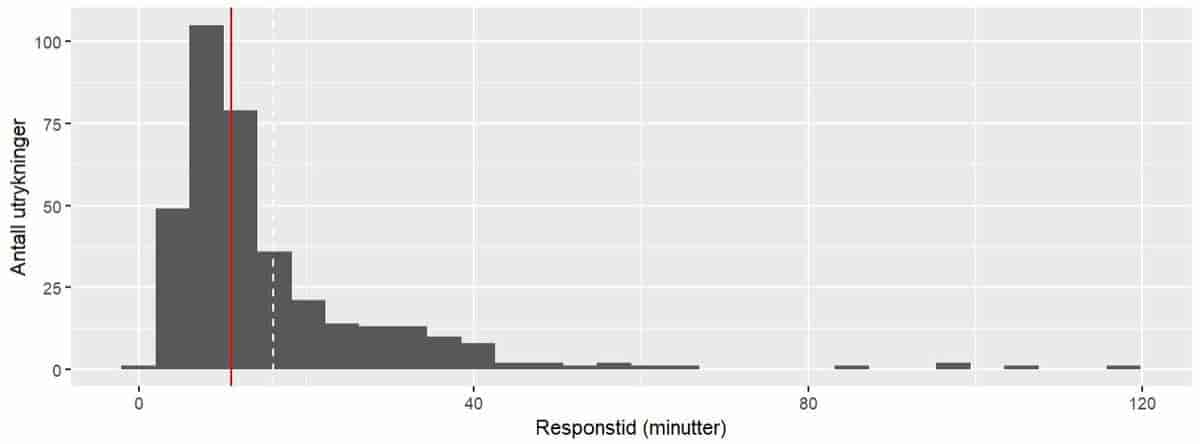
Responstiden for ambulanser i Oppdal kommune i 2019. Responstiden er tiden det tar fra en telefon mottas på en nødsentral, til ambulansen er fremme hos den som trenger hjelp. Fordelingen er skjev, med en topp til venstre og en hale til høyre. Gjennomsnittlig responstid er 16 minutter og 3 sekunder, og den finner du der den hvite, stiplede linjen treffer x-aksen. Median responstid er 11 minutter og 2 sekunder, og den finner du der den røde, heltrukne linjen treffer x-aksen. Figuren viser et eksempel på at gjennomsnittsverdien og medianverdien vanligvis er ganske forskjellige i skjeve fordelinger.
Oppsummering av kategoriske data
Kategoriske data blir ofte presentert i frekvenstabeller. Frekvenstabeller viser de ulike kategoriene sammen med antallet observasjoner (frekvensen) i hver kategori. Ofte vil en frekvenstabell også vise relativ frekvens, som er andelen eller prosentandelen av observasjoner i de ulike kategoriene.
Videre statistisk analyse
Også i videre analyse av data, som sammenligning av grupper, utvikling over tid, eller beregning av effekter, må vi ta hensyn til hvilken type data vi har, og analysemetodene må velges deretter.

Kommentarer
Kommentarer til artikkelen blir synlig for alle. Ikke skriv inn sensitive opplysninger, for eksempel helseopplysninger. Fagansvarlig eller redaktør svarer når de kan. Det kan ta tid før du får svar.
Du må være logget inn for å kommentere.