
Guía para entrenar tus dibujos en IA generativa - español
A downloadable asset pack
Guía para entrenar tus dibujos en IA generativa y generar tus assets locochones.
1. Introducción
Buenas, hoy quiero compartir con ustedes una guía completa sobre cómo usar IA generativa para crear assets. Mi enfoque es para y hacia otros artistas, sea para acelerar el flujo, sea para explorar alternativas interesantes, sea por limitaciones técnicas (tuve que vender mi tableta), sea por la razón que sea. Esto me ha permitido tomar el control de la consistencia y estilo de mis creaciones, y quiero compartir este conocimiento con otras personas.
Pasos a Seguir:
- Juntaremos un dataset de imágenes.
- Obtendremos sus descripciones de manera automática con un cuaderno de colab.
- Entrenaremos un algoritmo con las imágenes y descripciones para obtener un archivo safetensor que podamos montar en donde se nos plante.
Que plataforma elijas para generar con tu LoRa es manzana de otro árbol, verán muchos árboles. En esta Guía me estoy centrando en que puedas conseguir un archivo safetensor.
1.1 Pre-entrenamiento:
Preparación del Dataset:
Para empezar, necesitarás recopilar tus propios dibujos. Yo comencé con 35, pero incluso un pequeño dataset puede ser útil para generar un modelo básico que se puede iterar y mejorar con el tiempo. Al seleccionar los dibujos para tu dataset, es importante mantener la consistencia de lo que quieras hacer destacar. Por ejemplo, mis dibujos de árboles son pomposos y circulares, una característica que quise resaltar.
Recopilación de Dibujos






Las imágenes pueden tener diferentes tamaños, pero no demasiadas variaciones. Recomiendo usar resoluciones estándar como 1024x1024, 780x1024, y 1024x780. Preparar el dataset puede llevar algunas horas pero si tienes pocas imágenes será necesario que trabajes en su calidad y resolución.
Ejemplos y Aclaraciones:
Antes de comenzar, voy a mostrar algunas generaciones de este estilo y hacer unas cuantas aclaraciones:
--------------------------------------------------------------------------------------------------
--------------------------------------------------------------------------------------------------
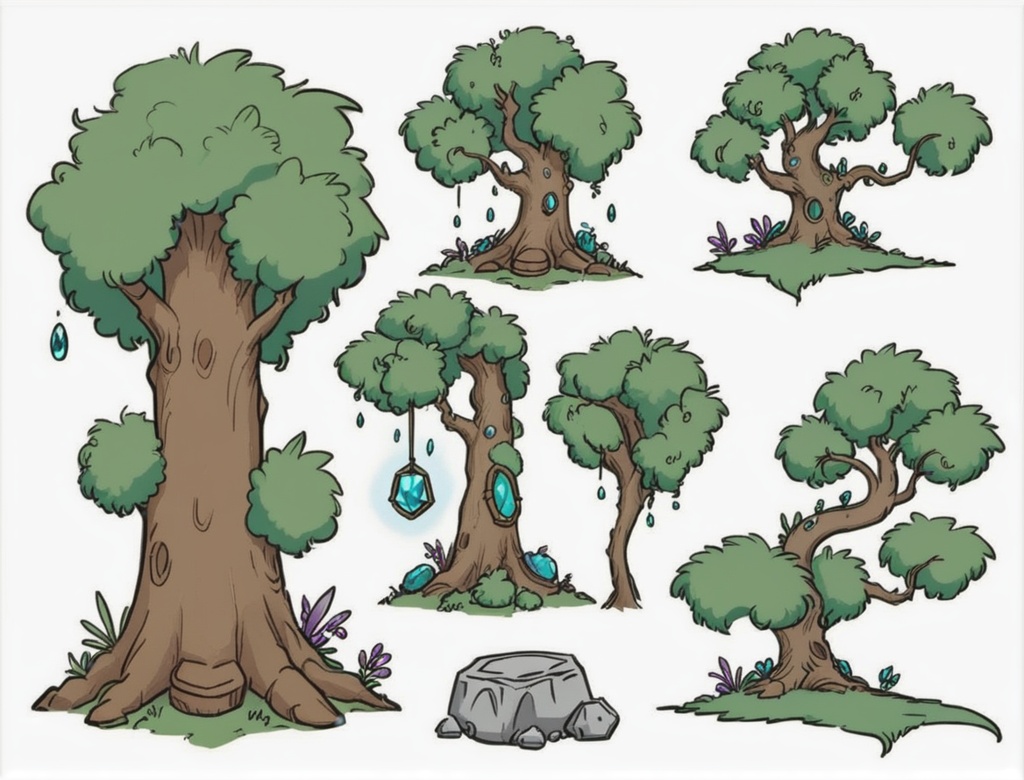
--------------------------------------------------------------------------------------------------
prompt: houtline, best quality, line-up, line_art, 2d_outline, fornitures, props, village_fornitures, wooden, walls, wooden_structures, gemstones, sprite_sheet, white_background, simple_background, halloween_(theme)
--------------------------------------------------------------------------------------------------


------------------------------------------------------------------------------------------------
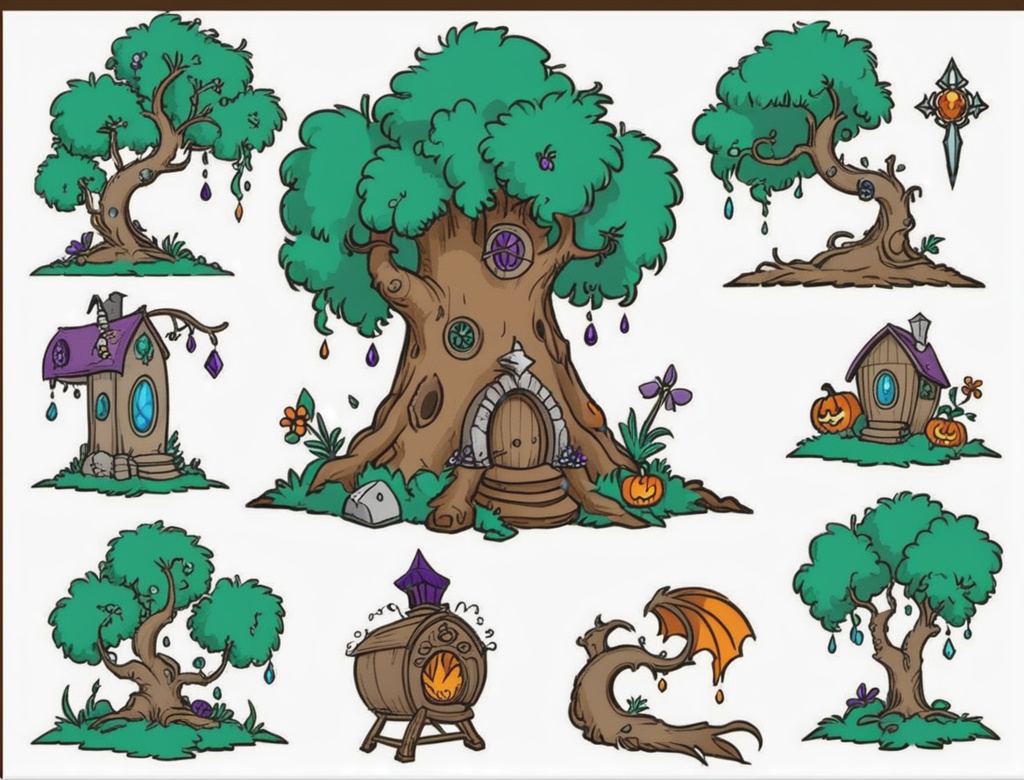
Prompt: houtline, best quality, line-up, line_art, 2d_outline, fornitures, props, church, Tombs, ghost, tinny_ghost, church_fornitures, wooden, walls, wooden_structures, gemstones, sprite_sheet, white_background, simple_background, halloween_(theme)
------------------------------------------------------------------------------------------------
Aquí mostraré otros modelos de dibujo. Lo anterior es Cheyenne pero también puedes mover el LoRa a otros modelos.
_CHINOOK_ by aurety

DynaVisionXL

Cheyenne By Aurety

Una vez mostrado esto, vamos a proseguir con el entrenamiento, no sin antes explicar:
¿Qué es un LoRa?
Un LoRa es un tipo específico de modelo de IA generativa, diseñado con ingredientes específicos para producir resultados coherentes y consistentes en ciertas tareas. Para entender mejor la diferencia entre un LoRa y otros tipos de modelos, veamos las siguientes categorías:
Modelos Fundacionales
| Modelo | Descripción |
|---|---|
| Stable Diffusion | Modelo general con una amplia cantidad de información, es Open source y te lo puedes bajar y montar en tu propia máquina. |
| DALL-E | Otro modelo general con una vasta cantidad de datos, es el que usas en chatgpt y copilot. |
| MidJourney | Un modelo general de suscripción |
Checkpoints
| Modelos | Descripción |
|---|---|
| PonyDiffusionXl, DinavisionXL, Juggernaut XL, AnimagineXL, AutismixXL | Modelos más pequeños que los fundacionales, requieren igualmente una cantidad considerable de cómputo. |
LoRa
Los LoRas son modelos preparados con ingredientes específicos para tareas específicas. Se utilizan en conjunto con los modelos fundacionales o checkpoints como una guía para producir resultados coherentes y consistentes en una tarea determinada. Son como una baranda que limita la creatividad del modelo para producir resultados más predecibles y útiles en ciertos contextos.
Se recomienda familiarizarse con la generación de imágenes en Stable Diffusion para comprender mejor cómo utilizar un entrenamiento LoRa.
1.2 Tagear el dataset para luego entrenar:
Yo uso Colab, no tengo un computador capaz de realizar un entrenamiento de este tipo pero el computo gratuito que tenemos es más que suficiente para la tarea que vamos a realizar.
Vamos por pasos:
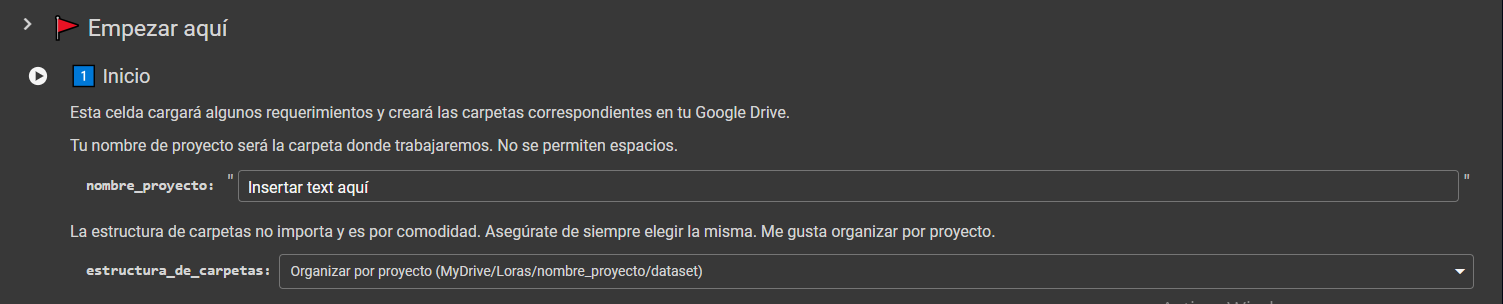
Ejecutamos y conectamos nuestro cuaderno a Drive y nombramos el proyecto. Esto creará tres carpetas: Loras/nombre_del_proyecto/dataset
Luego iremos a nuestro Drive y cargaremos nuestras fotos en la carpeta dataset. Ahora pasamos directamente al paso número 4 del cuaderno.
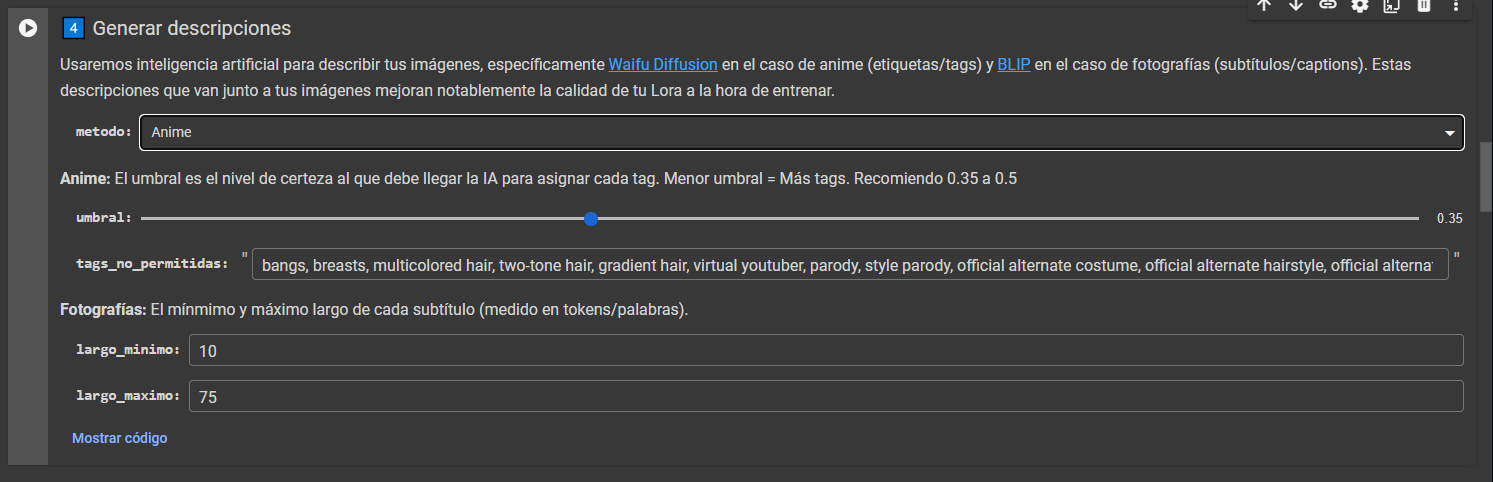
Aclaraciones con respecto a esto: existen dos modelos de visión en este cuaderno, uno es anime y es mejor para extraer los tags de personajes, mientras que fotografía es mejor con las fotos generales. El resultado será más o menos así:
Anime: 1cat, fur, animal, blue eyes, sitting, chair, depth_of_field, indoor
Fotografía: A cat sitting in a chair in a bedroom.
Puedes elegir uno de los dos. Para entrenar mi estilo he usado fotografía (BLIP) y para mi enfermera he usado anime (waifudiffusion).
El umbral determina el nivel de sensibilidad. Para este paso recomiendo dejar los parámetros tal cual recomienda el cuaderno mismo. Este proceso tarda unos 4 minutos aproximadamente.
Por último, añadimos una palabra de activación:
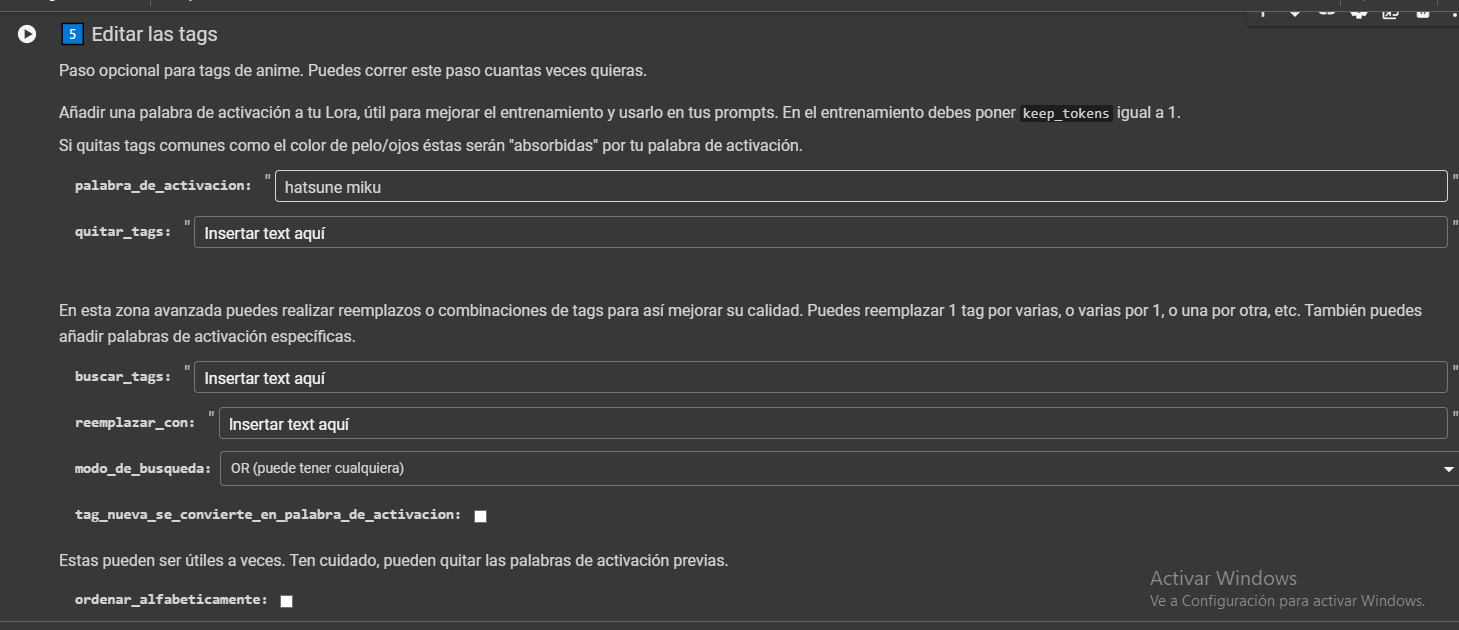
Donde dice "hatsune miku" hacemos un cambio y usamos alguna palabra de activación. Para mi propio estilo he usado "Houtline", esto activará todas las características dictadas en el entrenamiento y la escribiremos en el prompt cuando generemos. Procura no usar palabras que puedan ser confundidas con otros tags, como "cat", "dog", "girl" o alguna palabra muy general.
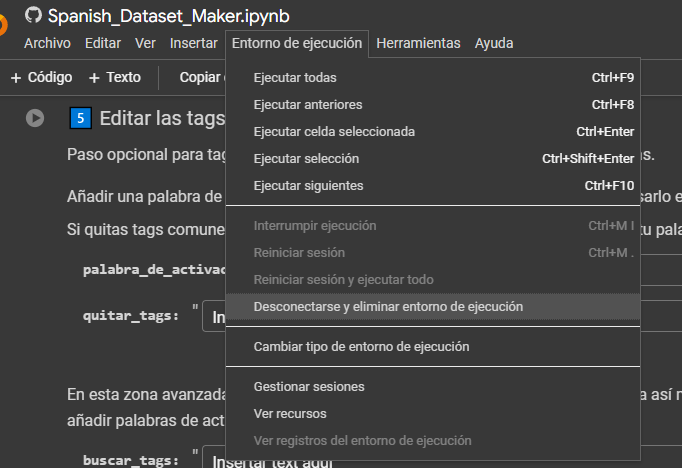
Antes de continuar recuerden desconectar y eliminar la ejecución actual.
2. Configuración del cuaderno de entrenamiento
Ahora tenemos listo el dataset y tageado para ir realizar el entrenamiento. Yo uso un cuaderno del mismo autor, el link a continuación:
Preparador de Lora de Hollowstrawberry
El primer paso:
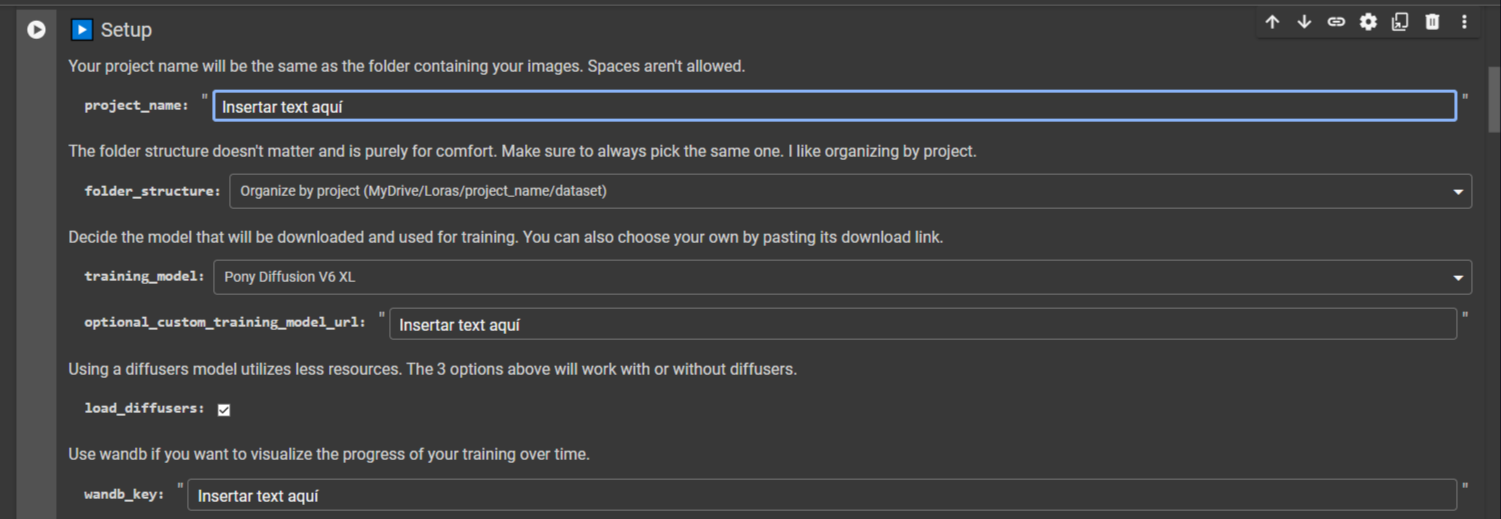
| Modelo | Descripción | Uso Recomendado |
|---|---|---|
| Stable Diffusion SDXL base 1.0 | Modelo adecuado para imágenes realistas. | Diverso pero yo lo uso para generar assets |
| Pony Diffusion SDXL | Optimizado para el anime y el contenido NSFW. | Generación de contenido relacionado con anime y bueno en NSFW. |
| Animagine XL | Especializado en el anime, menos efectivo con contenido NSFW. | Muy flexible, también quedan bien los assets que Animagine. |
Un LoRa entrenado en uno de estos modelos tiene más o menos influencia si es usado en otros base models, por ejemplo, de entrenar mis imágenes en Stable Diffusion SDXL base 1.0 me costaría generar con éxito en Pony Diffusion XL, tengan esto en cuenta. Para hacer assets yo uso SDXL base 1.0 ya que Cheyenne es el mejor modelo que he usado para generar estos y su base es SDXL.
Continuemos.
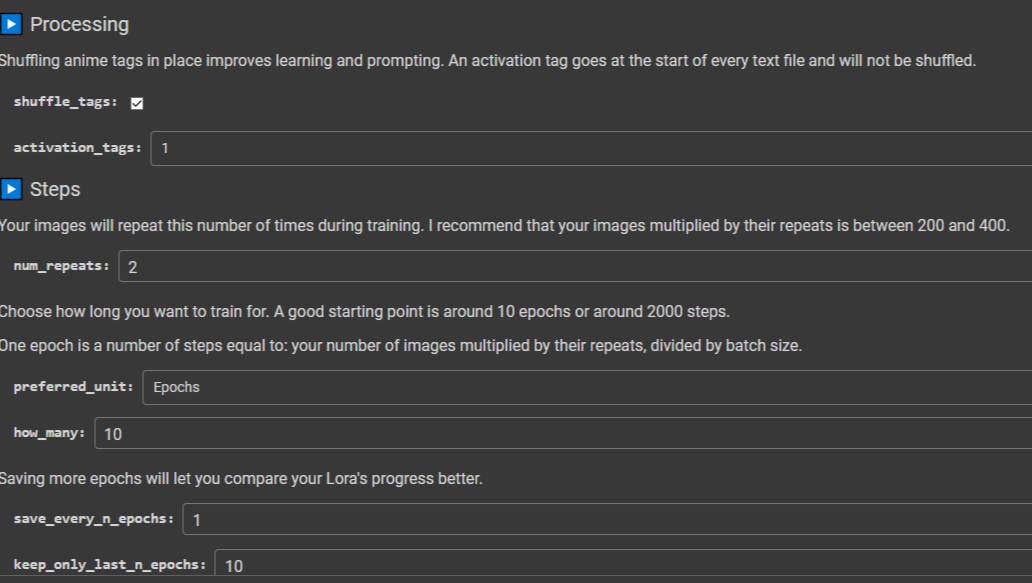
Activation tags: Si hemos usado una palabra trigger en el cuaderno anterior, dejamos esto en 1 y continuamos.
2.1- Configuración del Entrenamiento
A continuación, se presenta una explicación de los parámetros clave para configurar el entrenamiento:
| Parámetro | Descripción |
|---|---|
| num_repeats | Cantidad de veces que iterará el entrenamiento con cada imagen. |
| Epochs | El modelo entrenará sobre un conjunto de imágenes durante este número de épocas. Cada época consiste en procesar todas las imágenes del conjunto de datos una vez. |
| batch_size | Cantidad de imágenes que el modelo comparará en cada época. Un batch_size más alto puede acelerar el entrenamiento pero también puede requerir más memoria. |
La configuración de estos parámetros afectará el rendimiento y la eficacia del entrenamiento del modelo generativo.
Vamos con las matemáticas de esto:
Yo intento siempre caer dentro del umbral de los 300 a 500 pasos totales.
Numero de imágenes multiplicado por el num_repeats y dividido por el batch_size, y luego multiplicado por el numero de epochs, quedaría así:
| Número de Imágenes | num_repeats | batch_size | epochs | Pasos Totales |
|---|---|---|---|---|
| 10 | 20 | 6 | 10 | 10 x 20 / 6 x 10 = 400 |
| 50 | 4 | 6 | 10 | 50 x 4 / 6 x 10 = 400 |
| 100 | 2 | 6 | 10 | 100 x 2 / 6 x 10 = 400 |

Vamos hasta train_batch_size y configuramos, yo suelo configurar en 6.
2.2.- Optimizador
Lo siguiente es el optimizador, solo he usado dos, adamW8bits (para datasets de muchas imágenes) y prodigy (para dataset de pocas imágenes, es mi favorito para entrenar personajes).

Tengan en cuenta que el autor del cuaderno recomienda un argumento para cada optimizador, cuando cambien de optimizador, cambien el argumento.
Una vez hecho esto, ejecutamos el cuaderno y comenzará a entrenar. Este proceso tarda entre 1 hora y media y 3 horas. No se debe exceder ese tiempo ya que Google nos da diariamente una cantidad de cómputo limitada. Luego de 3 horas de entrenamiento, el cuaderno se desconecta y queda hasta donde ha podido llegar.
Los archivos finales estarán en la carpeta output de Google Drive.
3. Generación de Imágenes
Acá ustedes podrán elegir lo que ustedes quieran, hay muchas plataformas para subir tu LoRa, yo usaré Civitai porque quiero mostrar una alternativa gratuita, de seguro hay muchas más opciones.

Suban su modelo y sigan el formulario. No es nada del otro mundo, pero tienen que esperar algunas verificaciones, es un poco agotador hacerlo otra vez (revisen la privacidad, hay modo de mantener el modelo oculto para ti, una vez subido recomiendo dejarlo público y esperar un poco para llevarlo a modo borrador). Ya llevo unas buenas horas escribiendo esta guía, así que dejaré el enlace a mi modelo y haré las pruebas con él.

Vayan a su perfil y elijan su LoRa.

Elijan un modelo base, escriban un prompt y generen.

He pedido árboles de invierno, los resultados son:

Unas casas también.

Les dejaré el enlace a mi modelo acá, y postearé las imágenes por si quieren copiar el prompt o algo así, a su vez subiré una carpeta con muchas generaciones usando mi modelo, ustedes verán si solo quieren mirarla o limpiar los assets y usarlos.
Este es el final de la Guía. No soy un experto en esto pero he hecho varias pruebas y estaría bien poder transmitirlo para quienes se encuentre relacionados con la generación de imágenes. Cabe decir que ningún resultado generado es un buen output final, siempre deberás reparar, seleccionary limpiar y trabajar sobre todo lo que generes, pero es un buen punto de partida y puede funcionar para hacer mock-ups y place-holders que luego reemplazarás. Como sea, espero te sea de utilidad.
Download
Click download now to get access to the following files:











Leave a comment
Log in with itch.io to leave a comment.