proposal: runtime: permit setting goroutine name to appear in stack dumps #35178
Comments
|
Rob will say to pass this in a context and panic/recover print the context, or print the context during debugging - no matter that the context contains lots of state. You’re not going to win here and it’s a shame. TLS has been around a long time - it could of been replaced by context param long ago - no one felt it necessary but RP. |
I believe that my approach is different.
E.g.: Outputs:
|
|
To further expand on point 3, here's an example of a work that migrates between goroutines: With my proposal you get a nice error that would allow one to trace it exactly to the request that caused it (even though the request has completed by the time the error is triggered): |
What is wrong with that? Deferred function can access input I think that if we accepted this proposal, the next ask would be: "why don't we add also a |
|
Regardless of this, TLS plays a far bigger role in optimizing code paths without creating lots of external code changes and cruft.
Very common in server side applications where different code paths call the same pattern based functions with different values.
You can try doing this with context.Context but to do it right, every function no matter how small needs it - that essentially makes it a crippled TLS so why not start with a good one?
… On Oct 27, 2019, at 5:43 AM, Giulio Micheloni ***@***.***> wrote:
Most importantly, panics triggered by asynchronous events (e.g. a nil pointer dereference or out-of-bounds access) are also often impossible to correlate with the context that triggered them unless the recovery code happens to have the context. There is absolutely no workaround for that.
What is wrong with that? Deferred function can access input context.Context and easily enrich panic's message with context info.
I think that if we accept this proposal, the next ask would be: "why don't we add also a GetGoroutineName() string API? Thanks to that user can read goroutine's name after setting it". And I would like that not to happen, as it enables wrong code pattern and design, IMHO.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or unsubscribe.
|
There's nothing wrong with that per se, until you start using third-party libraries that can launch goroutines behind your back. Additionally, the main way to pass the context these days is context.Context. But there's no Context.Detach() method to detach the context from its cancellation lifetime, so third-party libraries often have to create a new context and they can't generically extract information that is needed for logging from the context that was passed to them. The example that has caused me problems was in AWS X-Ray SDK that launches a goroutine that asynchronously closes an active segment and in a TCP multiplexing library that did the same for non-blocking reads.
I agree, any attempts to add TLS should be directed to the FAQ about them. TLS is just ugly. If this is accepted, I'll make sure to add a huge warning to SetGoroutineName about this very issue. |
|
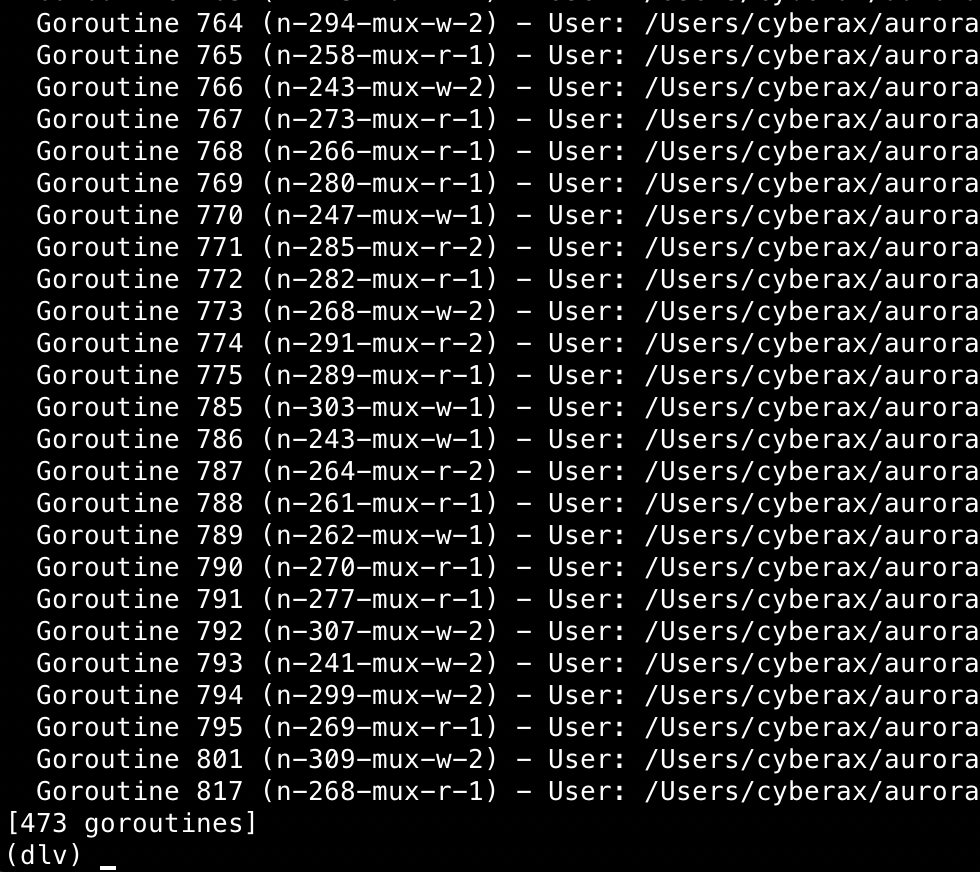
Here's an example of goroutine names in Delve. This is an output of "goroutines" command on my staging server: |
I like the general idea of goroutine naming, but I have concerns about the specific design decision above. I think there's value in giving goroutines unique names, such as making it trivial to attach a debugger to a specific goroutine without having to correlate to the line that launched it. Having names inherited defeats that benefit of uniqueness. Name inheritance seems to be just another form of dynamic context passing: "everything from here on down the call stack, pass this name along". If that form of dynamic context passing makes sense, why limit it to a single string value? Why special case its handling in the call stack? Some languages allow assigning names to otherwise anonymous closures. This proposal seems comparable to that: giving a name to an otherwise anonymous construct of the runtime. I think it should be explored further but that limitation on the scope of it. |
|
I feel that name inheritance is a necessary feature because it's fairly common for third-party libraries to launch utility goroutines in regular-looking methods and then screw them up somehow. I've seen more than one such example. I debated with myself about adding a unique suffix for inherited goroutines but ultimately decided against it. This feature is designed for human users, and typically once you have a request ID in the goroutine name it's not that hard to find the context. I played a bit with Delve today and the combination of goroutine name and last digits of the goroutine ID works for me perfectly. Oh, and names are not guaranteed to be unique. I'm going to rename the whole patch to use "Trace ID" instead of "Name". As for generalizing it, I don't want this at all. The Go language authors stated their opposition to TLS and any generalized "context inheritance" would necessitate it. My proposal is meant to solve one very specific use-case, without introducing new sweeping changes. |
|
If we added this, it would be complexity that everyone who has a go statement will eventually be forced to know about. It would infect all code. People will send PRs to add debug.SetGoroutineName in every go statement. And of course then you can't "Name inheritance" does not solve the problem. For example there are plenty of cases where a library might lazily create a background goroutine the first time it is entered. It is wrong to inherit the name in that case. People will still send PRs to add debug.SetGoroutineName in every go statement. There is also plenty that debuggers can do to identify goroutines without having to shift the burden onto users. The stack traces already record and display the location where the goroutine was created in the code, which identifies the specific go statement that created it. That should be enough for a debugger like Delve to group goroutines meaningfully. In the past I have also used the exact receiver pointers to group related goroutines. Delve or another tool could use those for clustering too. (Show me all goroutines with this specific receiver in the top-most function call, for example.) Let's work on making the debugger better instead of on forcing users to add what amount to print statements to their code. |
|
@rsc I understand those concerns, and they are valid, but I think the point being overlooked is that often all of the Go routines have the exact same creation point - this is especially common for request handlers (http, grpc) - so if you break-point in the debugger, or perform traces/analysis - you can't just use the creation site to distinguish. I guess the debugger could be changed to look to a context var in the call stack, and then be configured to use a property of the context to display as the "name", but this is asking a lot and every context would need to be handled differently. I don't fully understand the push-back here - this sort of "thread of execution context/name" has been around a long time, and was added because it is nearly required in performing concurrent application analysis - it is SO much more difficult debugging large concurrent programs in Go than any other environment I've worked with - and this is a shame, because the tracing facility / pprof is top notch (and a big component). |
|
also @rsc I am not sure your concerns about modifying a lot of code is true, I think it would be very few changes - at the framework level for most applications and at the point of major state transitions (determined the request type, source IP, etc.) |
|
We already have labels in cpu profiles (see https://godoc.org/runtime/pprof#Do) |
|
There does appear to be significant overlap between that API and the proposed one.
The changes needed to a “framework" would be the same/very similar.
… On Nov 6, 2019, at 5:03 PM, Konstantin Kulikov ***@***.***> wrote:
We already have labels in cpu profiles (see https://godoc.org/runtime/pprof#Do <https://godoc.org/runtime/pprof#Do>)
Can debuggers access and print those?
Can they be printed in stack traces?
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub <#35178?email_source=notifications&email_token=ABF2U4PJYSUP4PQOAHCCX63QSNEKLA5CNFSM4JFLYWP2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEDIJHRA#issuecomment-550540228>, or unsubscribe <https://github.com/notifications/unsubscribe-auth/ABF2U4MAOEO4VK5M7SQ33JLQSNEKLANCNFSM4JFLYWPQ>.
|
|
In fact, this method SetGoroutineLabels <https://golang.org/src/runtime/pprof/runtime.go#L21> implies that there is already a “labels” stored in the Go routine (independent of any Context) - it seems the debugger should be able to access/use/display those.
… On Nov 6, 2019, at 5:39 PM, robert engels ***@***.***> wrote:
There does appear to be significant overlap between that API and the proposed one.
The changes needed to a “framework" would be the same/very similar.
> On Nov 6, 2019, at 5:03 PM, Konstantin Kulikov ***@***.*** ***@***.***>> wrote:
>
> We already have labels in cpu profiles (see https://godoc.org/runtime/pprof#Do <https://godoc.org/runtime/pprof#Do>)
> Can debuggers access and print those?
> Can they be printed in stack traces?
>
> —
> You are receiving this because you commented.
> Reply to this email directly, view it on GitHub <#35178?email_source=notifications&email_token=ABF2U4PJYSUP4PQOAHCCX63QSNEKLA5CNFSM4JFLYWP2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEDIJHRA#issuecomment-550540228>, or unsubscribe <https://github.com/notifications/unsubscribe-auth/ABF2U4MAOEO4VK5M7SQ33JLQSNEKLANCNFSM4JFLYWPQ>.
>
|
I don't like the word "infect" when the result is code that results in a nicer-to-understand picture during debugging. It's also up to developers to NOT use it, the worst case here is just status quo with unnamed goroutines.
I'm actually using this in production right now with lots of libraries and so far I haven't had a case where name inheritance resulted in a misleading name. Typically libraries start helper goroutines from "constructor" functions that are either executed from the global context and thus inherit the 'global_init' name or they are request-scoped and inherit the request ID. I don't argue that such cases are impossible, but they are going to be rare and can be dealt with careful targeted SetGoroutineName() patches. Yes, this will result in some churn but surprisingly little of it. I can do a review of all of the Golang's standard library and identify all such cases as a part of the proposal. Should I?
What exactly can debuggers do? I'm seriously looking for suggestions here, as it's a pain point for us. I'm using Go not only for regular web serving which doesn't typically has a lot of structural complexity but also for simulation of complex systems. We're seriously thinking about going back to Java just because of this issue. Right now using a debugger to navigate between goroutines is straightforward impossible, all you get are opaque goroutine IDs. That you can not correlate with logging because it's not possible to get goroutine IDs from Go. |
|
If the problem we are trying to address is better support for understanding large numbers of goroutines in stack dumps and when debugging, then let's discuss that problem. Let's not jump to the idea of goroutine names, which have many drawbacks in a language like Go where goroutines are started casually. Maybe goroutine names are the best idea we can come up with, but that conclusion seems premature given that we haven't even started talking about the actual problem. For example, one thing that might help is giving the stack dump, and debuggers, access to the goroutine tree, so that you can see clearly that goroutine N was started by goroutine M. You can see this a bit today by using In general debuggers do not do well when there are many separate threads of executions, because most languages do not make it trivial to start many separate threads of executions. We need to do better in this area. |
If it's that dire, have you considered simply patching the runtime locally to provide this feature? Source for the runtime and stdlib is compiled and linked into every build. |
|
Austin has done some work to be able to run Go code in the inferior from a debugger. We could, for instance, run a user-defined function on every We could even use this user-defined function to do filtering of which goroutines we traceback. |
|
I think if you keep going down this road you end up with TLS. The “name” is only a simplified/limited and standardized form of this. For some reason the Go designers are against this. I’ve read what I can on their reasons why and it rings hollow to me. It may of held true when a Go program had limited purpose, but in the context of a larger complex system it is required infrastructure.
The fact that “concurrency is so easy” is what makes it even more important. People are writing very complex concurrent systems with no real option to debug. You can claim that quality code and designs should never need debugging but for me in the real world that is pure fantasy. It is VERY hard to write test cases (integration) in a concurrent environment. Often a panic / stack trace in production is all you have to go on. The names allow you to tie the stack trace back to event logs to manually reconstruct the state of the world.
… On Nov 7, 2019, at 5:07 PM, Keith Randall ***@***.***> wrote:
Austin has done some work to be able to run Go code in the inferior from a debugger. We could, for instance, run a user-defined function on every context.Context that appears in any stack trace, and print the results as additional info in the tracebacks. That user defined function could extract a request ID or other identifying info. This would naturally print additional info only for goroutines that were acting on behalf of a request that has a context (assuming contexts are plumbed ~correctly).
We could even use this user-defined function to do filtering of which goroutines we traceback.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or unsubscribe.
|
Erm. That's exactly what we did - see the link to the code in the starting post. But this is not a sustainable solution, we don't want to carry these patches forever. |
Sure. I don't mind alternative solutions at all, it's just that I was not able to come up with anything.
The problem is that I want to easily navigate between two related goroutines in the debugger. They often are siblings (started from a common parent) but quite often are not. I guess it would look something like this in a debugger: This indeed would help, but not by a lot. It's also not mutually exclusive with goroutine names. It also doesn't solve the problems with correlating panics with the request that caused them.
Honestly, I had no problems at all debugging this stuff in Java. We moved to Go because Java virtual machines simply do not scale well with the number of threads (we are up to >10k) but this has nothing to do with the debugging experience. |
|
In my experience with Java programs do not casually start threads in the way that Go programs start goroutines. Sure, Java programs have thousands of threads but those threads are more organized than Go goroutines are, because they start in fewer different places for fewer different reasons. Flipping between related goroutines sounds like a good idea. That suggests other possible debugger views of goroutines: goroutines that communicate via channels, or goroutines that acquire the same mutexes. |
|
I think the problem with that solution is that it is too low level. A good thread name provides a lot of context especially when combined with a system architecture document. Why force the developer to start low and go higher in order to conceptually understand what might be causing the issue. In my experience when “thinking concurrently” you need a really good understanding of the big picture before going low. |
I think you're exaggerating a bit, threads in Java (especially threadpooled parallel map/reduce style ops) are pretty common. And now that Java is getting lightweight threads they are going to become even more common. I also find the whole logic a bit strange, if Go makes goroutines much easier then why is it harder to debug than Java with its expensive threads? I'm also looking over the whole stdlib for places where goroutines are started (there's just several hundred of them disregarding tests) and so far only a handful of places would benefit from an actual explicit naming. Everything else should to be fine with inherited names.
This is indeed what I'm mostly using names for (but not always). But I don't think this view would be easy to navigate without names for the objects displayed. And it still won't solve the problem of stack trace dumps not having any context. This is still an issue, even if it's secondary for me personally. |
I actually looked into doing this, and it's not easy to do outside of the debugger (for regular stack traces). Even in a debugger it might be ambiguous, if your function has several contexts inside of one method (e.g. the parent context and a context with an additional field). |
Of course not, but I bet you'll spend less time maintaining your patch over the next 5y than you'll spend lobbying the Go team to adopt an idea they've considered and discarded :-) |
|
I wonder what would the result look when you use the spawning func name as the goroutine name in the debugger. Alternatively type + func. Of course, it wouldn't probably work in all places but it might be an improvement nevertheless. One approach: |
The type+func is not an issue, you can readily see it in the stack trace. It's the per-goroutine state that is problematic. You can have 10000 of ServeHTTP.SendEmail in the stack output, without having any idea which one you should look at. |
|
This issue has moved on from "permit setting goroutine name to appear in stack dumps" to a more wide-ranging discussion of debugging. That's fine, but that also means it is no longer really a concrete proposal. It seems like it might make the most sense to close this proposal as declined. |
|
I think they are related so maybe another issue for debugging. This is important for crash diagnosis the other is important during development.
… On Nov 27, 2019, at 11:26 AM, Russ Cox ***@***.***> wrote:
This issue has moved on from "permit setting goroutine name to appear in stack dumps" to a more wide-ranging discussion of debugging. That's fine, but that also means it is no longer really a concrete proposal. It seems like it might make the most sense to close this proposal as declined.
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub, or unsubscribe.
|
|
#35178 (comment) explained why we do not want to put goroutine names into the API proper and suggested that the focus here should be on improving debugger support for extracting info from variables in stack frames. That still seems to be the case. This specific proposal - add goroutine names - seems like a likely decline. Leaving open for a week for final comments. |
|
No change in consensus, so declined. |
|
for those that stumble upon this issue, there now exists a partial solution that covers some of this issue. see https://blog.jetbrains.com/go/2020/03/03/how-to-find-goroutines-during-debugging/ |
I've created this issue according to https://github.com/golang/proposal .
This is an issue to discuss a proposal to add goroutine names for debugging purposes only. The name will appear only in stack dumps. I do not propose any new mechanism that would allow creation of a thread-local storage.
In essence, I propose adding several new functions to the runtime package:
Sidenote: I don't like the name "name", as Go routines are anonymous. Perhaps I should rename it to "Trace ID" or something like it?
The goroutine name will be silently inherited by any goroutines spawned by the parent process.
Here's an example of use:
Run it:
With the server output:
I have created a proof-of-concept implementation: https://github.com/Cyberax/go/commit/ee50b1e771a3afdb760f56b6d1b1603772e3b3f0 and for the Delve debugger: https://github.com/Cyberax/delve/commit/c69a60eba91723425619654dce55236376d3929d
The text was updated successfully, but these errors were encountered: