


Abstract
The concept of photonic modes is the cornerstone in optics and photonics, which can describe the propagation of the light. The Maxwell’s equations play the role in calculating the mode field based on the structure information, while this process needs a great deal of computations, especially in the handle with a three-dimensional model. To overcome this obstacle, we introduce the multi-modal diffusion model to predict the photonic modes in one certain structure. The Contrastive Language–Image Pre-training (CLIP) model is used to build the connections between photonic structures and the corresponding modes. Then we exemplify Stable Diffusion (SD) model to realize the function of optical fields generation from structure information. Our work introduces multi-modal deep learning to construct complex mapping between structural information and optical field as high-dimensional vectors, and generates optical field images based on this mapping.

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
The photonic mode is one of the most common concepts in optics such as nano photonics, quantum optics and geometric optics, which is fundamental and sometimes confusing with different definitions. It can be defined as a normalized solution of Maxwell equations in vacuum [1] or the eigenfunction of an eigenproblem describing a physical system [2, 3]. Photonic modes refer to the distinct patterns of electromagnetic fields (optical waves) that can propagate or resonate within a photonic structure, such as waveguides, optical fibers, lasers, and photonic crystals. Each mode is characterized by a specific distribution of the electric and magnetic field components and has unique propagation characteristics. These distinct characteristics allow photonic modes to be regarded as solutions for the propagation of light or the transport of energy/information. They play a vital role in various applications, such as long-distance communication in few-mode fibers [4], space division multiplexing in multi-mode fibers [5], integrated photonics [6, 7], and ultra-short pulse generation in mode-locked lasers [8]. In a specific structure, such as the cavity or waveguide, the mode is the spatial distribution of photons [9]. In fact, photonic modes can be seen as the mapping relationship between optical structure and optical field distribution.
Deep learning as a powerful tool for data analysis has been introduced into physics, ranging from black hole detection [10], gravitational lenses [11], photonic structures design [12], quantum many-body physics, quantum computing, and chemical and material physics [13]. In optical field, the deep learning was mainly used in the design of photonic structures, such as plasmonic nanoparticles [14–16], metamaterials [17–24], photonic crystals [25–29], and integrated photonic devices [30–34]. In addition, the deep learning method can deal with the prediction of topological invariants in Hermitian and non-Hermitian systems [35–41].
Recently, Multi-Modal Machine Learning (MMML) has emerged as a novel tool in Natural Language Processing and Computer Vision to deal with the combination of different channels of information, which is also called ‘multi-modal’ [42, 43]. Most people associate the word modality with the sensory modalities which represent our primary channels of communication and sensation, such as vision or touch. MMML aims to build models that can process and relate information from multiple modalities. These algorithms and modeling tools show extremely good results especially for large models such as chat Generative Pre-trained Transformer [44], and visual generation models (e.g. Stable Diffusion (SD) [45]). Actually, the photonic system also behaves in the so called ‘multi-modal’. For example, the photonic structures and the corresponding modes are two different types of modalities. Thus, we can build the connection of different modalities in photonic system via MMML, based on a database calculated by the Maxwell’s equations. As we know, it requires extensive computation to get optical modes information by Maxwell’s equations, and even minute parameter changes necessitate recalculations, consuming a significant amount of time and resulting in inefficiencies. However, the integration of deep learning enables models to summarize previous optical field variations, applying this knowledge to subsequent computations. This concept is akin to ‘transfer learning’ [46] significantly reducing computational loads and enhancing efficiency by leveraging insights gained from prior calculations for future iterations.
2. Method
2.1. Contrastive language–image pre-training (CLIP) model
In this work, we use MMML to generate optical fields based on the structure information. Through a dataset containing simulation optical field results and model description text, we firstly build the connections between optical structures and the corresponding optical fields by the CLIP model [47] with fine-tuned process, which shows a great deal of improvement compared with the zero-shot network. Then we choose the SD, one of the most widely used open-source ‘text to image’ models [45], to generate high-fidelity optical fields based on specific optical structures.
To build the connections between the optical structures and their corresponding modes, we first introduce the CLIP method [47], which stands out as one of the notable landmarks in the progress of MMML. The CLIP algorithm combines an image encoder and a text encoder to predict the correct pairings of a batch of (image, and text) training examples as shown in figure 1. The image encoder handles the image data and learns its feature representation, while the text encoder processes the text data and learns the semantic representation of the text. Here we can regard the optical structure information as the text data and the optical field information as the image data.

Figure 1. Schematic diagram of the CLIP algorithm. Optical structure information (including parameters like radius, epsilon, band, and type) is encoded into text descriptions. These descriptions correspond to optical field distribution maps. The text and images are processed through text and image encoders, respectively, generating optical structure and distribution vectors. The optimizer maximizes cosine similarity between these vectors, enabling accurate matching and prediction of photonic modes based on encoded optical structure and field distribution information.
Download figure:
Standard image High-resolution imageThe usage of our CLIP model consists of two main stages: pre-training and fine-tuning. During the pre-training stage, it trains the model using large-scale image and text datasets to establish the association between images and corresponding text. The dataset contains 400 million (image, text) pairs from publicly available sources on the Internet collected by openAI. This stage enables the model to learn the underlying relationships between different modalities. In the fine-tuning stage, we further train the model using specific task-related datasets (e.g. classification, retrieval) to enhance its performance on those specific tasks. After training, the CLIP algorithm can effectively map input images and texts, comprehend the relationship between them, and be applied to various tasks such as comparison, classification, and retrieval.
The cosine similarity is the central aspect of the CLIP algorithm. It serves as a metric for evaluating the semantic resemblance between images and text. We determine the similarity by computing the cosine similarity between the phase diagram of the optical field and its corresponding parameters. The precise formula for calculating cosine similarity is presented below:

where  represents the image vector extracted by the image encoder,
represents the image vector extracted by the image encoder,  represents the text vector extracted by the text encoder,
represents the text vector extracted by the text encoder,  represents the dot product of vectors
represents the dot product of vectors  and
and  , while
, while  and
and  represents the modulo lengths the vector
represents the modulo lengths the vector  and
and  . Specifically, the image and text are converted into feature vectors
. Specifically, the image and text are converted into feature vectors  and
and  in the image encoder and text encoder, respectively, and then the cosine similarity between these vectors is calculated. Firstly, we extract the optical structure parameters
in the image encoder and text encoder, respectively, and then the cosine similarity between these vectors is calculated. Firstly, we extract the optical structure parameters  , which include structural details such as the radius (r), the dielectric constant (
, which include structural details such as the radius (r), the dielectric constant ( ), and the band number (b). These parameters are represented as a vector
), and the band number (b). These parameters are represented as a vector ![$\boldsymbol{P = }\left[ {r,\varepsilon ,b} \right]$](https://content.cld.iop.org/journals/2632-2153/5/3/035069/revision3/mlstad743fieqn14.gif) and are encoded into text descriptions. These descriptions are then processed by the text encoder to produce a feature vector
and are encoded into text descriptions. These descriptions are then processed by the text encoder to produce a feature vector  . Our text encoder uses a Transformer architecture. It comprises 12 layers with 512 dimensions and 8 attention heads. Text sequences are enclosed with start of sequence and end of sequence (EOS) tokens, and the final layer normalization activation on the EOS token is used as the text feature representation. For each position
. Our text encoder uses a Transformer architecture. It comprises 12 layers with 512 dimensions and 8 attention heads. Text sequences are enclosed with start of sequence and end of sequence (EOS) tokens, and the final layer normalization activation on the EOS token is used as the text feature representation. For each position  , a query vector
, a query vector  , a key vector
, a key vector  , and a value vector
, and a value vector  are calculated as follows:
are calculated as follows:

where  ,
,  ,
,  are learned parameters, and
are learned parameters, and  is our input optical structure parameters at position
is our input optical structure parameters at position  . The self-attention mechanism in the text encoder is then defined by [48]:
. The self-attention mechanism in the text encoder is then defined by [48]:

where  is the dimension of the key vectors, and softmax is the softmax function applied to the scaled dot products of the query and key vectors. The positional encoding is added to the input embeddings to retain the positional information [48]:
is the dimension of the key vectors, and softmax is the softmax function applied to the scaled dot products of the query and key vectors. The positional encoding is added to the input embeddings to retain the positional information [48]:

where PE stands for Positional Encoding, pos is the position index in the sequence, 2i and 2i+ 1 are the even and odd indices of the embedding dimension, d is the dimensionality of the embeddings, and 10 000 is a scaling factor to distribute positions across different frequencies. The sine and cosine functions are used for even and odd dimensions, respectively, ensuring that each position has a unique encoding.
Concurrently, the optical field distribution image  is processed. This information is processed by the image encoder to produce a feature vector
is processed. This information is processed by the image encoder to produce a feature vector  . The image encoder uses the ResNet50 architecture, which includes modifications such as ResNetD improvements and anti-aliasing blur pooling. The self-attention mechanism in the image encoder follows the same principles as the text encoder. For each image i, the query
. The image encoder uses the ResNet50 architecture, which includes modifications such as ResNetD improvements and anti-aliasing blur pooling. The self-attention mechanism in the image encoder follows the same principles as the text encoder. For each image i, the query  , key
, key  , and value
, and value  vectors are computed as follows:
vectors are computed as follows:

where Xi represents our input optical field distribution image, while  ,
,  , and
, and  are the learned weight matrices for the query, key, and value transformations, respectively. The attention mechanism is the same as equation (3).
are the learned weight matrices for the query, key, and value transformations, respectively. The attention mechanism is the same as equation (3).
To facilitate the cosine similarity calculation, both feature vectors are normalized to unit length. This normalization is achieved by dividing each vector by its L2 norm, resulting in  and
and  .The cosine similarity between the optical field distribution
.The cosine similarity between the optical field distribution  and its structure parameter texts
and its structure parameter texts  is then calculated following equation (1). If
is then calculated following equation (1). If  is close to 1, it means that they are very close in the semantic space and have similar semantic meanings. When
is close to 1, it means that they are very close in the semantic space and have similar semantic meanings. When  is close to −1, it means that they are far apart in the semantic space and have opposite semantic meanings. When
is close to −1, it means that they are far apart in the semantic space and have opposite semantic meanings. When  equals to 0, it means that the two are orthogonal in the semantic space, i.e. unrelated. For instance, if we consider a photonic crystal with the radius r = 0.2, the dielectric constant
equals to 0, it means that the two are orthogonal in the semantic space, i.e. unrelated. For instance, if we consider a photonic crystal with the radius r = 0.2, the dielectric constant  , and the band number b = 7, the text description might be ‘A photonic crystal with radius 0.2, dielectric constant 9.5, and band number 7.’ This text is encoded to a vector
, and the band number b = 7, the text description might be ‘A photonic crystal with radius 0.2, dielectric constant 9.5, and band number 7.’ This text is encoded to a vector  , while the corresponding optical field image is encoded to a vector
, while the corresponding optical field image is encoded to a vector  . The cosine similarity between these vectors provides a measure of how well the optical field image matches the described optical structure.
. The cosine similarity between these vectors provides a measure of how well the optical field image matches the described optical structure.
After constructing the CLIP modal, we need a comprehensive dataset comprising numerous images accompanied by corresponding text labels or descriptions in the fine-tune process. For simplicity and concreteness, we choose photonic crystals which are periodic dielectric structures exhibiting a band gap in their optical modes [49, 50], as a model to predict its optical modes. The band structure of a two-dimensional square lattice of dielectric rods in air are calculated by MIT Photonic Bands (MPB) [51] to construct a dataset, which includes adjustable parameters such as cylinder radius, dielectric constant, and band numbers, with Bloch wavevectors k= (0.5, 0). MPB is a free and open-source software package for computing the band structures, or dispersion relations, and electromagnetic modes of periodic dielectric structures, on both serial and parallel computers. MPB is an acronym for MPBs. We choose the lattice constant ‘a’ of the structure, and write all distances in terms of that. In principle, any unit can be used in conjunction with MPB, provided that each parameter is expressed in a consistent unit. Therefore, we have not specified any unit in figure 2. As these parameters vary, the corresponding field distribution of the photonic crystal undergoes significant changes. To see more clearly, the size of our unit cell is set to 3 × 3. Based on the traversal parameters of the optical model, we create a dataset containing 8, 000 different simulation optical field results and model description text. Subsequently, we train the CLIP model through fine-tuning with this dataset, aiming to improve its adaptability to our optical model.

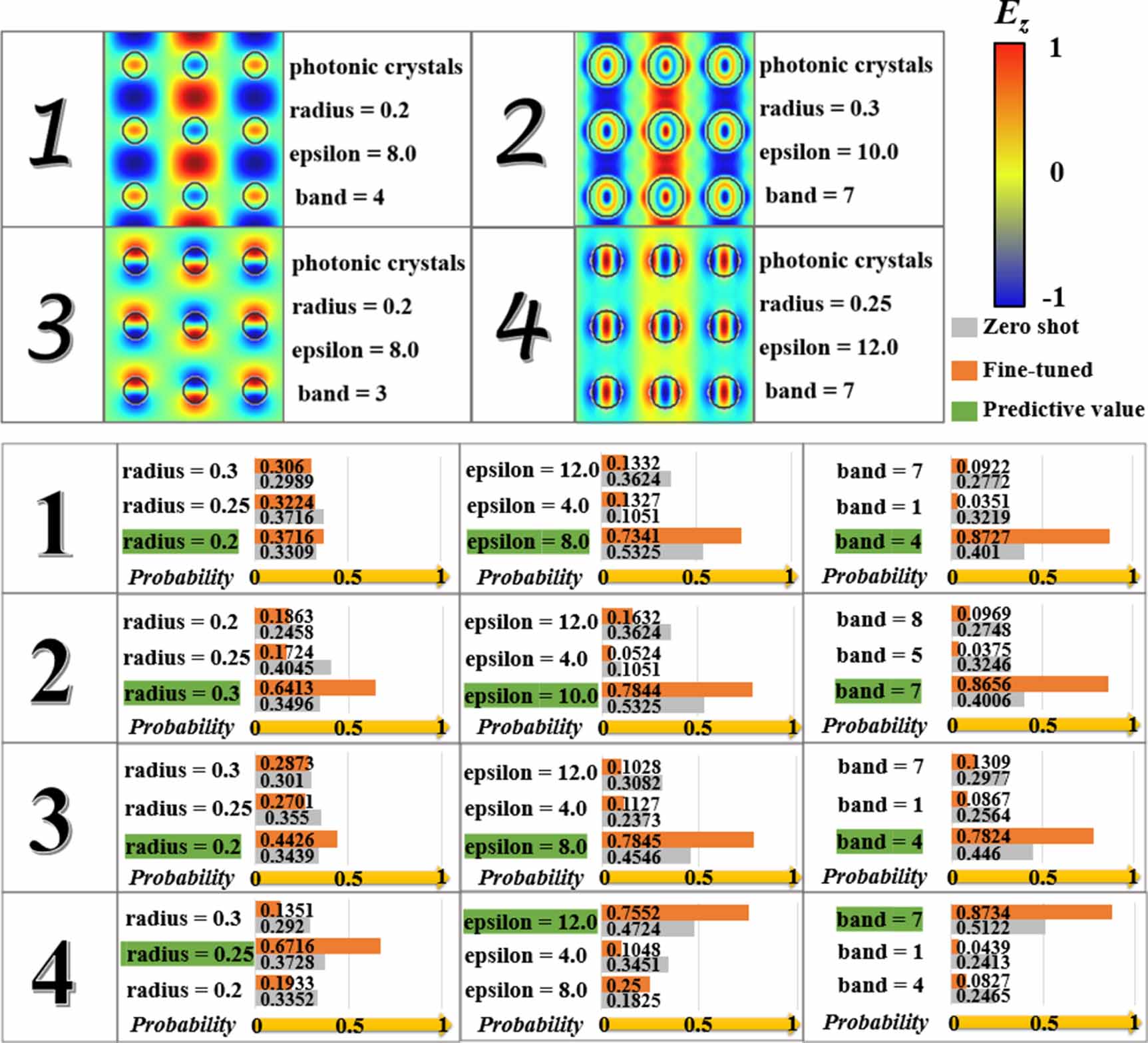
Figure 2. Paired results of 3 × 3 photonic crystal TM (Ez) mode field and mode pair based on CLIP algorithm. The Ez component refers to the electric field component in the direction of propagation, typically denoted as the z-axis, in an electromagnetic wave. The four images of optical field distribution in the figure are numbered 1 ∼ 4, and the right side of each image is part of the standard description text. For each image, we use the original CLIP network and the adjusted CLIP network to test the pairing of three different statements for three different parameters, and highlighted the pairing results given by the adjusted network in green.
Download figure:
Standard image High-resolution imagePhotonic modes, such as the Transverse Magnetic (TM) mode, are important for understanding optical behavior in photonic structures. A TM wave is a type of electromagnetic wave characterized by having no magnetic field component in the direction of wave propagation. Instead, the magnetic field is entirely transverse (perpendicular) to the direction of propagation, while the electric field has a component in the direction of propagation. We load the optical dataset into the CLIP model and train it for 10 000 epochs, resulting in an adjusted CLIP model. To assess the effectiveness and accuracy of this trained model, we conduct tests to evaluate the correspondence between optical field distribution images and optical parameter text. To this end, we randomly select four different optical field distributions with different parameters. Subsequently, we employ the trained CLIP model to examine the alignment between the images and texts, as depicted in figure 2. We conduct triple-text matching tests on four distinct parameterized optical field distribution images. These tests involve the radius, dielectric constant, and band number using both zero-shot and fine-tuned networks. The outcomes of these evaluations are depicted in figure 2, which clearly illustrates that the fine-tuned network consistently delivers more precise matching results (highlighted in green) compared to the zero-shot network.
2.2. SD model
Following the idea of CLIP comparative learning, we predict the parameters with the greatest cosine similarity as the result of model prediction shown in the highlighted green color in figure 2. After validations with the theoretical values, the success rate of pairing is calculated to be 98.6%, which basically meets our requirements for the CLIP model. Then, we introduce the SD model [45] and combine it with CLIP model [47] to train the phase diagram of optical field distribution. The core idea of SD is that each image has a certain regular distribution. To leverage this, the SD model maps textual descriptions to corresponding image distributions, using this information to guide the denoising process. Thus, the distribution information contained in the text can be used to generate an image matching the text information. In order to make the input text information become the machine information that SD model can understand, we need to give SD model a ‘bridge’ between text information and machine data information namely CLIP text encoder model, as shown in figure 3.

Figure 3. Schematic diagram of SD algorithm. Enter text prompt to generate predicted image through Text Encoder and Diffusion process. Optical structure information, specified by parameters such as radius, epsilon, band, and cylinder, is encoded into a optical structure vector via a text encoder. The vector is processed through multiple Unet steps (Step1, Step2, Step5, Step10, and Step30), together with a noisy image created by Gaussian noise. Each Unet step predicts noise samples, which are progressively refined through a denoising process to yield the final predicted image. This method integrates optical structure information (Text) and optical field distribution (Image) to enhance image generation.
Download figure:
Standard image High-resolution imageFor the SD algorithm, it is an image denoising method based on partial differential equation. First, we add Gaussian noise to the image:  , where
, where  represents the pixel coordinates in the original image,
represents the pixel coordinates in the original image,  is average
is average  and variance
and variance  Gaussian random variable,
Gaussian random variable,  is the image after adding noise. We obtain a noisy image through Gaussian noise sampling and use the reparameterization trick to make it differentiable. Typically, the randomness is introduced via an independent random variable
is the image after adding noise. We obtain a noisy image through Gaussian noise sampling and use the reparameterization trick to make it differentiable. Typically, the randomness is introduced via an independent random variable  . We sample a z from a Gaussian distribution, which can be written as:
. We sample a z from a Gaussian distribution, which can be written as:  , where z follows a Gaussian distribution with mean μ0 and variance
, where z follows a Gaussian distribution with mean μ0 and variance  , and
, and  is an independent standard normal random variable. Here,
is an independent standard normal random variable. Here,  and
and  are inferred by the neural network at each iteration. Then, we perform SD denoising on the noisy image by solving the nonlinear diffusion equation [45]:
are inferred by the neural network at each iteration. Then, we perform SD denoising on the noisy image by solving the nonlinear diffusion equation [45]:

where  represents the image position coordinates
represents the image position coordinates  and the brightness value t,
and the brightness value t,  is the gradient operator, and
is the gradient operator, and  is the diffusion coefficient, which is a function of gradient intensity. By iteratively solving the above partial differential equation, the noise in the image can be gradually reduced and the edge information of the image can be retained. In order to balance the trade-off between denoising and edge preserving, it is necessary to select an appropriate diffusion coefficient
is the diffusion coefficient, which is a function of gradient intensity. By iteratively solving the above partial differential equation, the noise in the image can be gradually reduced and the edge information of the image can be retained. In order to balance the trade-off between denoising and edge preserving, it is necessary to select an appropriate diffusion coefficient  . Here we choose a common diffusion coefficient based on Perona–Malik model [45]:
. Here we choose a common diffusion coefficient based on Perona–Malik model [45]:

where K is the parameter that controls the de-noising degree,  represents square of Euclidean distance. In our work, we add Gaussian noise to the original image and use the SD method by solving equation (2) to remove the noise, so as to obtain the denoised image. We have also provided an explanation of its working principle in appendix A.
represents square of Euclidean distance. In our work, we add Gaussian noise to the original image and use the SD method by solving equation (2) to remove the noise, so as to obtain the denoised image. We have also provided an explanation of its working principle in appendix A.
3. Results
In order to measure the effect of network generated images accurately, we introduced three measurement indicators, which are the Average Hashing (aHash) score [52], Fréchet Inception Distance (FID) score [53] and CLIP score [47], as depicted in figure 4(a).

Figure 4. (a) Histogram of three indicators at different epoch stages. (b) Comparison chart of a group of theoretical prediction images at different epoch stages. (c)–(d) Theoretical and predicted diagram of a 3D spherical lattice optical field distribution.
Download figure:
Standard image High-resolution image3.1. Measurement indicators
3.1.1. aHash score
Firstly, the aHash algorithm is an image similarity comparison method based on Perceptual Hashing technology. We take the aHash similarity to measure the similarity between the optical field distribution map generated by SD model and the theoretical optical field distribution map. The calculation process involves converting the two input images into gray-scale images and calculating their average values, which can be calculated as

where I(i,j) refers to graying out the pixel values in row i and column j of the image, W is the width of the image, and  is the height of the image. Next, each pixel in the image is traversed, and the binary value is used to represent the pixel. The specific expression is as follows:
is the height of the image. Next, each pixel in the image is traversed, and the binary value is used to represent the pixel. The specific expression is as follows:

where I(i,j) represents the gray value of the image in row i and column j, G(I) represents the average gray value of the image, and B(I,G(I)) is the binary feature vector of the image. Finally, the binary vectors of the two images are compared, and the number of the same elements is compared with the vector length to obtain the similarity between the original image and the generated image. Therefore, aHash score is a relatively simple and intuitive judgment index.
3.1.2. FID score
Secondly, FID score is a metric used to evaluate the quality of generated images. It is specifically used to evaluate the performance of images generated by the model. Its calculation formula is as follows:

where  represents the distribution of theoretical image,
represents the distribution of theoretical image,  represents the distribution of the generated image,
represents the distribution of the generated image,  and
and  represents the eigenvectors of images P and Q respectively,
represents the eigenvectors of images P and Q respectively,  and
and  represents the covariance matrix of the eigenvectors of two distributions respectively,
represents the covariance matrix of the eigenvectors of two distributions respectively,  denotes the trace operation of the matrix, and
denotes the trace operation of the matrix, and  denotes the square of the Euclide. FID score can evaluate the difference between the generated model and the real data distribution. The lower the value, the closer the generated image is to the real image. Due to the significantly larger values of the FID Score compared to the aHash Score and CLIP Score, we normalize the FID score to adjust the numerical scale, as depicted in figure 4(a).
denotes the square of the Euclide. FID score can evaluate the difference between the generated model and the real data distribution. The lower the value, the closer the generated image is to the real image. Due to the significantly larger values of the FID Score compared to the aHash Score and CLIP Score, we normalize the FID score to adjust the numerical scale, as depicted in figure 4(a).
3.1.3. CLIP score
Finally, CLIP score is a measure of the relevance between text and image. It measures the similarity between input text and image by converting them into feature vectors through CLIP model, and then calculating the cosine similarity between them. The calculation formula is as follows:

where c represents the input text data, v represents the input predictive image data, and w is the coefficient parameter. Here we set w = 1. The higher the CLIP score, the higher the correlation between image text pairs. Therefore, when the CLIP score of this model is closer to 1, the image text correlation is higher and higher.
3.2. Evaluation results
Here we list a group of fields predicted during different epochs, and take use of the above three indicators to evaluate the effect of networks with different training epochs, as shown in figure 4(a). The parameters of this model are set as radius = 0.2, epsilon = 9.5, Bloch wavevectors k = (0.5, 0), and band = 7 with the same type photonic crystals in figure 2. We write all distances in terms of the lattice constant a. The closer the aHash similarity is to 1, the more the generated image resembles the theoretical optical field distribution map. Similarly, a smaller FID score indicates that the generated image is closer to the theoretical optical field distribution map. A CLIP score closer to 1 indicates that the generated optical field distribution map better matches the textual description.
Based on the three measurement indicators, it is evident that the aHash value, FID score, and CLIP score of the network display signs of stabilization, as the model undergoes training until the 6th epoch. It indicates that more training of the network yields minimal improvement, suggesting that the model tends to reach a stable state. Additionally, it demonstrates a significant enhancement in the quality of generated images from epochs 2–6 in figure 4(b). However, beyond the 6th epoch, no noticeable differences can be observed in the images generated by our model. In this case, we offer an example of the training process, and we have included some other optical field prediction images in appendix B and the prediction process is provided in appendix C.
3.3. Computational complexity analysis
To demonstrate the reduction in computational complexity achieved by our method compared to traditional approaches, we provide a detailed analysis of the time required to generate predicted images using both Maxwell’s equations and the SD model. The results are summarized in table 1.
Table 1. Computational complexity analysis.
| Method | Number of Predicted Images /(groups) | |||
|---|---|---|---|---|
| 1 | 10 | 50 | 100 | |
| Time to Generate Predicted Images /(s) | ||||
| Maxwell Equations | 2.4167 | 16.149 | 128.19 | 337.328 |
| Stable Diffusion (SD) | 1.68 | 12.86 | 67.48 | 142.34 |
One group of data refers to the optical field distribution obtained through a set of structural parameters. The following hardware specifications are used for this analysis: 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30 GHz CPU, 16 cores, 32 GB RAM, 300 GB system disk, 10 Mbps bandwidth, and RTX4090 GPU.
As shown in the table, using traditional equations (Maxwell’s equations) to calculate optical field distributions is time-consuming due to extensive computational requirements. Conversely, the SD model leverages pre-learned patterns, significantly reducing computation time. For large datasets, the time required for SD predictions increases linearly rather than exponentially, demonstrating superior computational efficiency. Additionally, we also calculate the three-dimensional optical field distribution of the lattice by MPB shown in figures 4(c) and (d). Our model not only has the ability to predict two-dimensional field distributions but also has the ability of handling three-dimensional optical field prediction tasks with specific training. For this investigation, we employ the following parameter values: radius = 0.4, epsilon = 9.2, and band = 5 with Bloch wavevectors k = (0, 0.625, 0.375), and subsequently predict the three-dimensional optical field. By comparing our prediction results with the theoretical optical field distribution, we observe that the fundamental features are still present in the predicted image, of which the aHash score, the FID score and the FID score are 0.8224, 13.7415, and 0.7728, respectively. As our dataset obtained by MPB is accurate and complete, a larger dataset can improve the accuracy of prediction. Furthermore, we provide a way to improve the details of photonic modes shown in appendix D.
4. Conclusion
To summarize, we have introduced the MMML to photonic modes prediction. We show that the photonic crystal mode can be well matched and predicted by the CLIP and the SD algorithm based on a dataset consisted by paired optical structure and field information. Our method can significantly reduce the computational complexity of optical structures, especially in the mission of optical field optimization. We have successfully generated optical fields based on the structure information utilizing the ‘text to image’ algorithm. Actually, as the optical structure can be set as the input image data, the ‘image to image’ generative models [54] can also be applied to find the relation between optical structure and the corresponding modes. Moreover, the ‘any to any’ generative models [55] can help to generate target modal from input combinations of any set of input conditions, as the design of photonic structures needs more than one the so-called modality or requirement, such as basic optical structures, target optical fields, and optical spectrum.
In addition to ML and MMML methods, there are several other approaches for photonic mode prediction and classification. Compared to such traditional machine learning models such as Gaussian mixture model based on clustering [56], fully connected neural networks (FCNNs) [14], deep neural networks (DNNs) [57], and generative adversarial networks (GANs) [58], our MMML network stands out due to its ability to handle diverse input types with less reliance on large labeled datasets and computational resources. The Gaussian mixture model often struggles with handling high-dimensional data and complex structures, while FCNNs require significant computational resources for extensive datasets. DNNs have demonstrated efficiency in predicting both far-field and near-field optical properties but still require substantial computational power for training. However, our MMML model integrates multi-modal information for more accurate and robust predictions, significantly reducing computational complexity and offering a highly efficient solution for optical structure analysis. Additionally, our approach leverages pre-trained models fine-tuned with specific datasets, making it more data-efficient and straightforward to train and deploy. This simplicity avoids the complexities associated with balancing components in GANs and enhances practicality for a wide range of applications. We believe that the MMML also can be extended to other physical platforms, such as mechanism, acoustics, electrical circuit and so on, duo to the generalization of the ‘multi-modal’ concept.
Acknowledgments
The authors thank for the support by National Natural Science Foundation of China under (Grant 62001289), NUPTSF (Grant Nos. NY220119, NY221055). We thank Professor Xiaofei Li for useful discussions.
Data availability statement
All data that support the findings of this study are included within the article (and any supplementary files).

{kind=link}
{kind=link}
{kind=link}
{kind=link}