

Abstract
This paper describes the data release of the Sloan Digital Sky Survey-II (SDSS-II) Supernova Survey conducted between 2005 and 2007. Light curves, spectra, classifications, and ancillary data are presented for 10,258 variable and transient sources discovered through repeat ugriz imaging of SDSS Stripe 82, a 300 deg2 area along the celestial equator. This data release is comprised of all transient sources brighter than r ≃ 22.5 mag with no history of variability prior to 2004. Dedicated spectroscopic observations were performed on a subset of 889 transients, as well as spectra for thousands of transient host galaxies using the SDSS-III BOSS spectrographs. Photometric classifications are provided for the candidates with good multi-color light curves that were not observed spectroscopically, using host galaxy redshift information when available. From these observations, 4607 transients are either spectroscopically confirmed, or likely to be, supernovae, making this the largest sample of supernova candidates ever compiled. We present a new method for SN host-galaxy identification and derive host-galaxy properties including stellar masses, star formation rates, and the average stellar population ages from our SDSS multi-band photometry. We derive SALT2 distance moduli for a total of 1364 SN Ia with spectroscopic redshifts as well as photometric redshifts for a further 624 purely photometric SN Ia candidates. Using the spectroscopically confirmed subset of the three-year SDSS-II SN Ia sample and assuming a flat ΛCDM cosmology, we determine ΩM = 0.315 ± 0.093 (statistical error only) and detect a non-zero cosmological constant at 5.7σ.
Export citation and abstract BibTeX RIS
1. Introduction
In response to the astounding discovery of the late-time acceleration of the expansion rate of the universe (Riess et al. 1998; Perlmutter et al. 1999), a number of large-scale supernova (SN) surveys were launched. These experiments included programs to observe low redshift SN such as the Lick Observatory Supernova Search (Ganeshalingam et al. 2010), Nearby Supernova Factory (Aldering et al. 2002), the Carnegie Supernova Project (Hamuy et al. 2006; Contreras et al. 2010), the Center for Astrophysics SN Program (Hicken et al. 2009, 2012), and the Foundation Supernova Survey (Foley et al. 2018). At higher redshift, new surveys included ESSENCE (Miknaitis et al. 2007), the Supernova Legacy Survey (SNLS; Astier et al. 2006), Pan-STARRS (Rest et al. 2014; Scolnic et al. 2014), and dedicated HST observations by Riess et al. (2007, 2018). At intermediate redshifts, the Sloan Digital Sky Survey (SDSS; York et al. 2000) bridged the gap between the local and distant SN searches by providing repeat observations of a 300 deg2 stripe of sky at the equator (known as Stripe 82) and discovered thousands of Type Ia SN (SN Ia) over the redshift range 0.05 < z < 0.4 (Frieman et al. 2008).
This paper presents all data collected over the last decade as part of the SDSS SN Survey. This search was a dedicated multi-band, magnitude-limited survey, which provided accurate multi-color photometry for tens of thousands of transient objects, all with a well-determined detection efficiency. The data have lead to precise measurements of the SN rate as a function of redshift, environment, and SN type (Dilday et al. 2008, 2010a, 2010b; Smith et al. 2012; Taylor et al. 2014), and have lead to important new constraints on cosmology with detailed studies of systematic uncertainties (Kessler et al. 2009a; Sollerman et al. 2009; Lampeitl et al. 2010a; Betoule et al. 2014; Scolnic et al. 2017). The large survey volume and high cadence have enabled early discoveries of rare events (Phillips et al. 2007; McClelland et al. 2010; McCully et al. 2014), as well as detailed statistical studies of normal events (Hayden et al. 2010a, 2010b).
The extensive, well-calibrated SDSS galaxy catalog has also helped revolutionize the study of SN Ia and the dependence on their host-galaxy properties. For example, Lampeitl et al. (2010b) and Johansson et al. (2013) showed a clear correlation between SN Hubble residuals and the stellar mass of the host. The origin of this correlation remains unclear, but Gupta et al. (2011) found evidence for the correlation being due to the age of the stellar population (cf. Johansson et al. 2013), while D'Andrea et al. (2011) found the correlation was likely related to the gas-phase metallicity using a sub-sample of star-forming SDSS host galaxies. Hayden et al. (2013) have used the fundamental metallicity relation (Mannucci et al. 2010) to further reduce the Hubble residuals, suggesting again that metallicity is the underlying physical parameter responsible for the correlation. Galbany et al. (2012), however, did not detect an obvious correlation between Hubble residuals and distance to the SN from the center of the host galaxy, as might be expected due to metallicity gradients, but they are not as sensitive as the more direct metallicity measurements presented in D'Andrea et al. (2011). Galbany et al. (2012) also found that extinction and SN Ia color decrease with increasing distance from the center of the host, and that the average SN light curve shape differs significantly in elliptical and spiral galaxies as seen in many previous studies (Hamuy et al. 1996; Gallagher et al. 2005; Sullivan et al. 2006). Xavier et al. (2013) found that SN Ia properties in rich galaxy clusters are, on average, different from those in passive field galaxies, possibly due to differences in age of the stellar populations. Finally, Smith et al. (2014) studied the effects of weak gravitational lensing on the SDSS-II SN Ia distance measurements.
The SN spectra presented in this data release are a collection of data from 11 different telescopes and includes some spectra taken to determine galaxy properties long after the SN had faded. We did not attempt a detailed spectroscopic analysis of the full sample beyond transient classification and redshift measurement, but subsets of the data were previously published (Zheng et al. 2008; Konishi et al. 2011b; Östman et al. 2011) and analyzed to quantitatively measure spectral features (Konishi et al. 2011a; Nordin et al. 2011a, 2011b; Foley et al. 2012).
Since spectra were not obtained for all discovered transients (as is true for all SN surveys), Sako et al. (2011) analyzed the light curves of the full sample of variable objects and identified ∼1100 purely photometric SN Ia candidates with quantitative estimates for the classification efficiency and sample purity. In the absence of a SN spectrum, the identification and placement of SN Ia on a Hubble diagram is greatly aided by a knowledge of the host-galaxy redshift. Many host galaxy spectroscopic redshifts were measured by the SDSS-I and SDSS-II surveys, but the SDSS-III (Eisenstein et al. 2011) Baryon Oscillation Spectroscopic Survey (BOSS; Dawson et al. 2013) ancillary program (Olmstead et al. 2014) provided redshifts for most of the observable SN host galaxies. Hlozek et al. (2012), Campbell et al. (2013), and Jones et al. (2017a, 2017b) presented Hubble diagrams using photometric SN classification and host redshifts, and demonstrated that statistically competitive cosmological constraints can be obtained with limited spectroscopic follow up of active SN candidates. The SDSS work on photometric identification represents an important example analysis for ongoing and future large surveys, such as DES (Bernstein et al. 2012) and LSST (Tyson 2002), where full spectroscopic follow up of all active SN candidates will be impractical.
This paper presents a catalog of 10,258 SDSS sources that were identified as part of the SDSS SN search. The images and object catalogs provided herein were produced by the standard SDSS survey pipeline as presented in SDSS Data Release 7 (Abazajian et al. 2009). Our transient catalog is presented as a machine readable table in the on-line version of this paper, and the format of the catalog is described in Table 1. Detailed descriptions of general properties (Section 3), source classification (Section 4), SN Ia light curve fits (Section 7) for selected sources, and host galaxy identifications (Section 8) are given along with truncated tables of catalog data. The photometric data is described in Section 5. Many sources have associated optical spectra, which are described and cataloged in Section 6.
Table 1. SDSS SN Catalog
| Item | Format | Symbol | Description (units) |
|---|---|---|---|
| 1 | I5 | CID | SDSS candidate identification number |
| 2 | F12.6 | R.A. | SN right ascension (J2000, degrees) |
| 3 | F11.6 | Decl. | SN declination (J2000, degrees) |
| 4 | I5 | Nsearchepoch | Number of search detection epochs |
| 5 | A13 | IAUName | Name assigned by the International Astronomical Union |
| 6 | A11 | Classification | Candidate PSNID type (see Table 3) |
| 7 | F6.1 | Peakrmag | Measured peak asinh magnitude (r-band) |
| 8 | F10.1 | MJDatPeakrmag | Modified Julian Date (MJD) of observed peak brightness (r-band) |
| 9 | I5 | NepochSNR5 | Number of epochs with S/N > 5 |
| 10 | I5 | nSNspec | Number of SN spectra |
| 11 | I5 | nGALspec | Number of host galaxy spectra |
| 12 | F10.6 | zspecHelio | Heliocentric redshift |
| 13 | F10.6 | zspecerrHelio | Heliocentric redshift uncertainty |
| 14 | F10.6 | zCMB | CMB-frame redshift |
| 15 | F10.6 | zerrCMB | CMB-frame redshift uncertainty |
| SALT2 4-parameter Fits | |||
| 16 | E10.2 | x0SALT2zspec | SALT2 x0 (normalization) parameter |
| 17 | E10.2 | x0errSALT2zspec | SALT2 x0 (normalization) parameter uncertainty |
| 18 | F6.2 | x1SALT2zspec | SALT2 x1 (shape) parameter |
| 19 | F6.2 | x1errSALT2zspec | SALT2 x1 (shape) parameter uncertainty |
| 20 | F6.2 | cSALT2zspec | SALT2 c (color) parameter |
| 21 | F6.2 | cerrSALT2zspec | SALT2 c (color) uncertainty |
| 22 | F10.2 | PeakMJDSALT2zspec | SALT2 MJD at peak in B-band |
| 23 | F7.2 | PeakMJDderrSALT2zspec | SALT2 MJD at peak in B-band uncertainty |
| 24 | F7.2 | muSALT2zspec | SALT2mu distance modulus |
| 25 | F6.2 | muerrSALT2zspec | SALT2mu distance modulus uncertainty |
| 26 | F8.3 | fitprobSALT2zspec | SALT2 fit chi-squared probability |
| 27 | F8.2 | chi2SALT2zspec | SALT2 fit chi-squared |
| 28 | I5 | ndofSALT2zspec | SALT2 number of light curve points used |
| MLCS2k2 4-parameter Fits | |||
| 29 | F6.2 | deltaMLCS2k2zspec | MLCS2k2 shape parameter (Δ) |
| 30 | F6.2 | deltaerrMLCS2k2zspec | MLCS2k2 shape parameter (Δ) uncertainty |
| 31 | F6.2 | avMLCS2k2zspec | MLCS2k2 V-band extinction (AV) |
| 32 | F6.2 | averrMLCS2k2zspec | MLCS2k2 V-band extinction (AV) uncertainty |
| 33 | F10.2 | PeakMJDMLCS2k2zspec | MLCS2k2 MJD of peak brightness in B-band |
| 34 | F7.2 | PeakMJDerrMLCS2k2zspec | MLCS2k2 MJD of peak brightness in B-band uncertainty |
| 35 | F7.2 | muMLCS2k2zspec | MLCS2k2 distance modulus |
| 36 | F6.2 | muerrMLCS2k2zspec | MLCS2k2 distance modulus uncertainty |
| 37 | F8.3 | fitprobMLCS2k2zspec | MLCS2k2 chi-squared fit probability |
| 38 | F8.2 | chi2MLCS2k2zspec | MLCS2k2 chi-squared |
| 39 | I5 | ndofMLCS2k2zspec | MLCS2k2 number of light curve points used |
| PSNID Parameters using Spectroscopically Observed Redshift | |||
| 40 | F7.3 | PIaPSNIDzspec | SN Ia Bayesian probability (zspec prior) |
| 41 | E10.2 | logprobIaPSNIDzspec | SN Ia log(Pfit) (zspec prior) |
| 42 | I5 | lcqualityIaPSNIDzspec | SN Ia light curve quality (zspec prior) |
| 43 | F7.3 | PIbcPSNIDzspec | SN Ib/c Bayesian probability (zspec prior) |
| 44 | E10.2 | logprobIbcPSNIDzspec | SN Ib/c log(Pfit) (zspec prior) |
| 45 | I5 | lcqualityIbcPSNIDzspec | SN Ib/c light curve quality (zspec prior) |
| 46 | F7.3 | PIIPSNIDzspec | SN II Bayesian probability (zspec prior) |
| 47 | E10.2 | logprobIIPSNIDzspec | SN II log(Pfit) (zspec prior) |
| 48 | I5 | lcqualityIIPSNIDzspec | SN II light curve quality (zspec prior) |
| 49 | I5 | NnnPSNIDzspec | Number of nearest neighbors (zspec prior) |
| 50 | F7.3 | PnnIaPSNIDzspec | SN Ia nearest-neighbor probability (zspec prior) |
| 51 | F7.3 | PnnIbcPSNIDzspec | SN Ib/c nearest-neighbor probability (zspec prior) |
| 52 | F7.3 | PnnIIPSNIDzspec | SN II nearest-neighbor probability (zspec prior) |
| 53 | F8.4 | zPSNIDzspec | PSNID redshift (zspec prior) |
| 54 | F8.4 | zerrPSNIDzspec | PSNID redshift uncertainty (zspec prior) |
| 55 | F6.2 | dm15PSNIDzspec | PSNID Δm15(B) (zspec prior) |
| 56 | F6.2 | dm15errPSNIDzspec | PSNID Δm15(B) uncertainty (zspec prior) |
| 57 | F6.2 | avPSNIDzspec | PSNID AV (zspec prior) |
| 58 | F6.2 | averrPSNIDzspec | PSNID AV uncertainty (zspec prior) |
| 59 | F10.2 | PeakMJDPSNIDzspec | PSNID Tmax (zspec prior) |
| 60 | F7.2 | PeakMJDerrPSNIDzspec | PSNID Tmax uncertainty (zspec prior) |
| 61 | I5 | SNIbctypePSNIDzspec | Best-fit SN Ib/c template (zspec prior) |
| 62 | I5 | SNIItypePSNIDzspec | Best-fit SN II template (zspec prior) |
| SALT2 5-parameter Fits (ignoring spectroscopic redshift information) | |||
| 63 | E10.2 | x0SALT2flat | SALT2 x0 (normalization) parameter (flat-z prior) |
| 64 | E10.2 | x0errSALT2flat | SALT2 x0 (normalization) parameter uncertainty (flat-z prior) |
| 65 | F6.2 | x1SALT2flat | SALT2 x1 (shape) parameter (flat-z prior) |
| 66 | F6.2 | x1errSALT2flat | SALT2 x1 (shape) parameter uncertainty (flat-z prior) |
| 67 | F6.2 | cSALT2flat | SALT2 c (color) parameter(flat-z prior) |
| 68 | F6.2 | cerrSALT2flat | SALT2 c (color) parameter uncertainty (flat-z prior) |
| 69 | F10.2 | PeakMJDSALT2flat | SALT2 Tmax (flat-z prior) |
| 70 | F7.2 | PeakMJDerrSALT2flat | SALT2 Tmax uncertainty (flat-z prior) |
| 71 | F7.2 | zphotSALT2flat | SALT2 fitted redshift (heliocentric frame) |
| 72 | F6.2 | zphoterrSALT2flat | SALT2 fitted redshift uncertainty (heliocentric frame) |
| 73 | F8.3 | fitprobSALT2flat | SALT2 fit chi-squared probability |
| 74 | F8.2 | chi2SALT2flat | SALT2 fit chi-squared |
| 75 | I5 | ndofSALT2flat | SALT2 number of light curve points used |
| PSNID Parameters Ignoring Spectroscopic Redshift Information | |||
| 76 | F8.3 | PIaPSNIDflat | SN Ia Bayesian probability (flat-z prior) |
| 77 | F8.2 | logprobIaPSNIDflat | SN Ia log(Pfit) (flat-z prior) |
| 78 | I5 | lcqualityIaPSNIDflat | SN Ia light curve quality (flat-z prior) |
| 79 | F7.3 | PIbcPSNIDflat | SN Ib/c Bayesian probability (flat-z prior) |
| 80 | E10.2 | logprobIbcPSNIDflat | SN Ib/c log(Pfit) (flat-z prior) |
| 81 | I5 | lcqualityIbcPSNIDflat | SN Ib/c light curve quality (flat-z prior) |
| 82 | F7.3 | PIIPSNIDflat | SN II Bayesian probability (flat-z prior) |
| 83 | E10.2 | logprobIIPSNIDflat | SN II log(Pfit) (flat-z prior) |
| 84 | I5 | lcqualityIIPSNIDflat | SN II light curve quality (flat-z prior) |
| 85 | I5 | NnnPSNIDflat | Number of nearest neighbors (flat-z prior) |
| 86 | F7.3 | PnnIaPSNIDflat | SN Ia nearest-neighbor probability (flat-z prior) |
| 87 | F7.3 | PnnIbcPSNIDflat | SN Ib/c nearest-neighbor probability (flat-z prior) |
| 88 | F7.3 | PnnIIPSNIDflat | SN II nearest-neighbor probability (flat-z prior) |
| 89 | F8.4 | zPSNIDflat | PSNID redshift (flat-z prior) |
| 90 | F8.4 | zerrPSNIDflat | PSNID redshift uncertainty (flat-z prior) |
| 91 | F6.2 | dm15PSNIDflat | PSNID Δm15(B) (flat-z prior) |
| 92 | F6.2 | dm15errPSNIDflat | PSNID Δm15(B) uncertainty (flat-z prior) |
| 93 | F6.2 | avPSNIDflat | PSNID AV (flat-z prior) |
| 94 | F6.2 | averrPSNIDflat | PSNID AV uncertainty (flat-z prior) |
| 95 | F10.2 | PeakMJDPSNIDflat | PSNID Tmax (flat-z prior) |
| 96 | F7.2 | PeakMJDerrPSNIDflat | PSNID Tmax uncertainty (flat-z prior) |
| 97 | I5 | SNIbctypePSNIDflat | Best-fit SN Ib/c template (flat-z prior) |
| 98 | I5 | SNIItypePSNIDflat | Best-fit SN II template (flat-z prior) |
| Host Galaxy Information | |||
| 99 | I21 | objIDHost | Host galaxy object ID in SDSS DR8 Database |
| 100 | F13.6 | RAhost | Right ascension of galaxy host (degrees) |
| 101 | F11.6 | DEChost | Declination of galaxy host (degrees) |
| 102 | F6.2 | separationhost | Distance from SN to host (arcsec) |
| 103 | F6.2 | DLRhost | Normalized distance from SN to host (dDLR) |
| 104 | F7.2 | zphothost | Host photometric redshift (KF algorithm) |
| 105 | F6.2 | zphoterrhost | zphothost uncertainty |
| 106 | F7.2 | zphotRFhost | Host photometric redshift (RF algorithm) |
| 107 | F6.2 | zphotRFerrhost | zphotRFhost uncertainty |
| 108 | F8.3 | dereduhost | Host galaxy u-band magnitude (dereddened) |
| 109 | F7.3 | erruhost | Host galaxy u-band magnitude uncertainty |
| 110 | F8.3 | deredghost | Host galaxy g-band magnitude (dereddened) |
| 111 | F7.3 | errghost | Host galaxy g-band magnitude uncertainty |
| 112 | F8.3 | deredrhost | Host galaxy r-band magnitude (dereddened) |
| 113 | F7.3 | errrhost | Host galaxy r-band magnitude uncertainty |
| 114 | F8.3 | deredihost | Host galaxy i-band magnitude (dereddened) |
| 115 | F7.3 | errihost | Host galaxy i-band magnitude uncertainty |
| 116 | F8.3 | deredzhost | Host galaxy z-band magnitude (dereddened) |
| 117 | F7.3 | errzhots | Host galaxy z-band magnitude (dereddened) |
| Galaxy Parameters Calculated with FPPS | |||
| 118 | F7.2 | logMassFSPS | FSPS log(M), M = Galaxy Mass (M in units of M⊙) |
| 119 | F7.2 | logMassloFSPS | FSPS Lower limit of uncertainty in 
|
| 120 | F7.2 | logMasshiFSPS | FSPS Upper limit of uncertainty in log(M) |
| 121 | F8.2 | logSSFRFSPS | FSPS log(sSFR) sSFR = Galaxy Specific Star-forming Rate (SFR in M⊙ yr−1) |
| 122 | F8.2 | logSSFRloFSPS | FSPS Lower limit of uncertainty in 
|
| 123 | F8.2 | logSSFRhiFSPS | FSPS Upper limit of uncertainty in 
|
| 124 | F7.2 | ageFSPS | FSPS galaxy age (Gyr) |
| 125 | F7.2 | ageloFSPS | FSPS Lower limit of uncertainty in age |
| 126 | F7.2 | agehiFSPS | FSPS Upper limit of uncertainty in age |
| 127 | F8.2 | minredchi2FSPS | Reduced chi-squared of best FSPS template fit |
| Galaxy Parameters Calculated with PÉGASE.2 | |||
| 128 | F8.2 | logMassPEGASE | PÉGASE.2 log(M), M = Galaxy Mass (M in units of M⊙) |
| 129 | F8.2 | logMassloPEGASE | PÉGASE.2 Lower limit of uncertainty in 
|
| 130 | F8.2 | logMasshiPEGASE | PÉGASE.2 Upper limit of uncertainty in 
|
| 131 | F9.2 | logSFRPEGASE | PÉGASE.2 log(SFR) SFR = Galaxy star-forming rate (M⊙ yr−1) |
| 132 | F9.2 | logSFRloPEGASE | PÉGASE.2 Lower limit of uncertainty in 
|
| 133 | F9.2 | logSFRhiPEGASE | PÉGASE.2 Upper limit of uncertainty in 
|
| 134 | F8.2 | agePEGASE | PÉGASE.2 galaxy age (Gyr) |
| 135 | F8.2 | ageloPEGASE | PÉGASE.2 Lower limit of uncertainty in age |
| 136 | F8.2 | agehiPEGASE | PÉGASE.2 Upper limit of uncertainty in age |
| 137 | F8.2 | minchi2PEGASE | Reduced chi-squared of best PÉGASE.2 fit |
| 138 | I3 | notes | See list of notes in Table 4 |
The primary goal of this paper is to present the previously unpublished SDSS SN photometric data for all detected transients (including detections which are clearly not SN) and the previously unpublished SN and host galaxy spectra. We present illustrative analyses of our data, including photometric classification, host-galaxy matching. light curve fit parameters, Hubble diagrams, constraining power on cosmological parameters, and simulations. Users should beware that these analyses are not intended for any particular science result, and therefore careful consideration should be given to future analyses based on the results presented here. While using our results may be appropriate in certain cases, we anticipate and encourage further improvements in the methods shown here. We present a detailed table of SN candidate properties that provides supplementary information for the publications mentioned above and also serves as a reference analysis for future work. Some of our analysis methods have evolved, and we include descriptions of the newer methods of photometric identification and of identifying host galaxies.
2. SDSS-II Supernova Survey
The SDSS-II SN data were obtained during three-month campaigns in the Fall of 2005, 2006, and 2007 as part of the extension of the original SDSS. A small amount of engineering data were collected in 2004 (Sako et al. 2005), but are not included in this paper, since the cadence and survey duration were not adequate for detailed light curve studies. The SDSS telescope (Gunn et al. 2006) and imaging camera (Gunn et al. 1998) produce photometric measurements in each of the ugriz SDSS filters (Fukugita et al. 1996) spanning the wavelength range of 350–1000 nm. The most useful filters for observing SDSS SN, however, are g, r, and i because the SN are difficult to detect in u and z except at low redshifts (z ≲ 0.1 for SN Ia) due to the relatively poor throughput of those filters.
The SDSS SN survey is a "rolling search," where a portion of the sky is repeatedly scanned to discover new SN and to measure the light curves of the ones previously discovered. The survey observed Stripe 82, which is 2 5 wide in decl. between R.A. of 20h and 04h. The camera is operated in drift scan mode with all filters being observed nearly simultaneously with a fixed exposure time of 55 s each. Full coverage of Stripe82 was obtained in two nights (with offset camera positions), but the average cadence was approximately four nights because of inclement weather and interference from moonlight. The coverage and cadence of the survey is shown in Figure 1. The repeated scans were used by Annis et al. (2014) to produce and analyze deep coadded images. The survey is sensitive to SN Ia beyond a redshift of 0.4, but beyond a redshift of 0.2 the completeness, and the ability to obtain high-quality photometry, deteriorates.
5 wide in decl. between R.A. of 20h and 04h. The camera is operated in drift scan mode with all filters being observed nearly simultaneously with a fixed exposure time of 55 s each. Full coverage of Stripe82 was obtained in two nights (with offset camera positions), but the average cadence was approximately four nights because of inclement weather and interference from moonlight. The coverage and cadence of the survey is shown in Figure 1. The repeated scans were used by Annis et al. (2014) to produce and analyze deep coadded images. The survey is sensitive to SN Ia beyond a redshift of 0.4, but beyond a redshift of 0.2 the completeness, and the ability to obtain high-quality photometry, deteriorates.

Figure 1. Number of scans vs. right ascension (shown in degrees) of the SDSS SN equatorial stripe (Stripe 82) is shown along with the mean cadence for each year (2005–2007) of the survey. The coverage in right ascension increased slightly as the template image coverage increased while the mean cadence was approximately four days for all three observing seasons.
Download figure:
Standard image High-resolution imageThe SDSS camera images were processed by the SDSS imaging software (Stoughton et al. 2002) and SN were identified via a frame subtraction technique (Alard & Lupton 1998). Objects detected after frame subtraction in two or more filters were placed in a database of detections. These detected objects were scanned visually and were designated candidates if they were not obvious artifacts. Spectroscopic measurements were made for promising candidates depending on the availability and capabilities of telescopes. The candidate selection and spectroscopic identification have been described by Sako et al. (2008). In three observing seasons, the SDSS-II SN Survey discovered 10,258 new variable objects and spectroscopically identified 499 SN Ia and 86 core-collapse SN (CC SN).
3. SN Candidate Catalog
Table 1 describes the format of the SDSS-II SN catalog, which includes information on the 10,258 sources detected on two or more nights. The full catalog is made available online; a small portion is reproduced as an example in Table 2.
Table 2. SDSS-II SN Candidatesa
| CID | RA | DEC | neb | IAUName | Classification | Peakrmag | MJDatPeakrmag | n5b | nsb | ngb | zspecHelio | zspecerrHelio | objIDHost |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 679 | 327.434978 | 0.657569 | 3 | 2005eh | Unknown | 21.8 | 53699.2 | 1 | 0 | 0 | 0.124957 | 0.000017 | 1237656238472888902 |
| 680 | 327.555405 | 0.842584 | 21 | ⋯ | Variable | 21.6 | 53685.1 | 1 | 0 | 0 | ⋯ | ⋯ | 1237678617403654778 |
| 682 | 331.239470 | 0.845158 | 2 | ⋯ | Unknown | 21.8 | 53656.2 | 0 | 0 | 0 | 0.048551 | 0.000022 | 1237678617405227407 |
| 685 | 337.823273 | −0.882037 | 14 | ⋯ | pSNII | 21.7 | 53656.2 | 10 | 0 | 0 | ⋯ | ⋯ | 1237656906345349717 |
| 688 | 343.171604 | −0.962902 | 4 | ⋯ | Unknown | 21.4 | 53616.3 | 5 | 0 | 0 | 0.067866 | 0.000010 | 1237656906347708594 |
| 689 | 345.314592 | −0.866253 | 15 | ⋯ | Variable | 21.3 | 53680.2 | 15 | 0 | 0 | ⋯ | ⋯ | 1237656906348626518 |
| 691 | 329.729408 | −0.498538 | 9 | ⋯ | Unknown | 20.3 | 53616.2 | 9 | 0 | 0 | 0.130903 | 0.000021 | 1237663542608986381 |
| 692 | 351.071097 | −0.945665 | 18 | ⋯ | Variable | 21.2 | 53663.2 | 15 | 0 | 0 | 0.197275 | 0.000030 | 1237656906351182046 |
| 694 | 330.154633 | −0.623472 | 22 | ⋯ | Unknown | 19.7 | 53627.2 | 28 | 0 | 0 | 0.127493 | 0.000018 | 1237663542609183155 |
| 695 | 352.963374 | −0.963772 | 3 | ⋯ | Variable | 22.7 | 53637.3 | 0 | 0 | 0 | 0.058267 | 0.000009 | 1237656906351968456 |
| 696 | 354.180048 | −1.020436 | 6 | ⋯ | psNIa | 21.3 | 53623.3 | 5 | 0 | 0 | ⋯ | ⋯ | ⋯ |
| 697 | 335.002430 | −0.626145 | 8 | ⋯ | Unknown | 21.6 | 53627.2 | 5 | 0 | 0 | 0.156675 | 0.000032 | 1237663542611280181 |
| 698 | 335.302586 | −0.554336 | 17 | ⋯ | Variable | 21.6 | 53663.2 | 14 | 0 | 0 | ⋯ | ⋯ | 1237663542611411980 |
| 699 | 332.585653 | 0.625899 | 21 | ⋯ | Variable | 21.7 | 53656.2 | 15 | 0 | 0 | ⋯ | ⋯ | 1237663479795352223 |
| 700 | 335.579430 | −0.518987 | 16 | ⋯ | AGN | 21.5 | 53616.2 | 14 | 0 | 0 | 0.595712 | 0.000242 | 1237663542611542434 |
| ⋯ | |||||||||||||
Notes.
aSelected columns relating to general properties of the entries are shown here for guidance regarding the form and content of these columns. bIn the electronic edition ne, n5, ns, ng are called Nsearchepoch, NepochSNR5, nSNspec and nGALspec, respectively.Only a portion of this table is shown here to demonstrate its form and content. A machine-readable version of the full table is available.
Download table as: DataTypeset image
General photometric properties include the J2000 coordinates of the SN candidate, the number of epochs detected by the search pipeline (Nsearchepoch) and final photometry pipeline above S/N > 5 (NepochSNR5), and r-band magnitude (Peakrmag) and MJD (MJDatPeakrmag) of the brightest measurement. We show the distribution of NepochSNR5 for all candidates in Figure 2 as an indication of the general quality of the light curves.

Figure 2. Distribution of number of epochs with S/N > 5 observed per SN is shown. An epoch consists of one night of observation in all 5 SDSS filters and there are typically about 20 epochs in an observing season. A small fraction of SN lie in the overlap region and are observed with twice the cadence—up to 40 times per season.
Download figure:
Standard image High-resolution imageWe provide the heliocentric redshift (zspecHelio) and uncertainty (zspecerrHelio) when spectroscopic measurements are available. The source of the redshift is from the host galaxy spectrum or, if the host galaxy redshift is not known, from the SN spectrum. More details on the spectra are given in Section 6. The number of spectra available as part of this Data Release are given as nSNspec (the number of SN spectra) and nGALspec (the number of host galaxy spectra) in the catalog. The galaxy spectra include cases where the galaxy spectrum is obtained from the SN spectroscopic observation but with an aperture chosen to enhance the galaxy light and cases where a spectrum was taken when the SN was no longer visible for the purpose of measuring the galaxy redshift and possibly other galaxy properties. Galaxy spectra that were taken with the SDSS spectrograph (Smee et al. 2013) are not included in these totals, but objIDHost gives the SDSS DR8 object index so that the galaxy properties may be easily extracted from the SDSS database. Spectra as part of the SDSS-III BOSS program are also not included in these totals. They are discussed in Campbell et al. (2013) and Olmstead et al. (2014), but their redshifts are listed under zspecHelio. Finally, we provide the CMB-frame redshifts and uncertainties in zCMB and zerrCMB, respectively. The CMB-frame redshifts do not include any correction for bulk flow peculiar velocities.
Some sources (most of the spectroscopically identified SN) were assigned a standard name by the IAU; the name is listed for those sources that have been assigned one. The peak r-band magnitude observed is plotted versus redshift in Figure 3.

Figure 3. Peak r-band magnitude observed is shown as a function of redshift. Black points shown are for all candidates classified as SN Ia with a spectroscopically measured redshift. All the other SN candidates with a redshift listed in Table 1 are shown in blue. We have not made any effort to separate genuine SN from other objects; the purpose of this plot is to show the sensitivity of the SDSS search relative to the SN Ia.
Download figure:
Standard image High-resolution imageThe candidates are classified according to their light curves and spectra (when available), and the results of the classification are shown in Table 2. Visual scanning removed most of the artifacts, so almost all of the objects in the catalog are variable astronomical sources, some of which are only visible for a limited period of time (for example, supernovae). The multi-night requirement eliminates rapidly moving objects, which are primarily main-belt asteroids. A summary of the number of objects in each classification is shown in Table 3. The classification "Unknown" means that the light curve was too sparse and/or noisy to make a useful classification, "Variable" means that the source was observed in more than one observing season, and "AGN" means that an optical spectrum was identified as having features associated with an active galaxy, primarily broad hydrogen emission lines. The other categories separate the source light curves into three SN types: Type II, Type Ibc (either Ib or Ic), and Type Ia. A prefix "p" indicates a purely photometric type where the redshift is unknown and that the identification has been made with the photometric data only. A prefix "z" indicates that a redshift is measured from its candidate host galaxy and the classification uses that redshift as a prior. The SN classifications without a prefix are made based on a spectrum (including a few non-SDSS spectra). The Type Ib and Ic spectra identifications are shown separately. The "SN Ia?" classification is based on a spectrum that suggests a SN Ia but is inconclusive. The details and estimated accuracy of the classification scheme are given in the next section.
Table 3. Number of SN Candidates by Type Category
| Type | Number |
|---|---|
| Unknown | 2009 |
| Variable | 3225 |
| pSNII | 1628 |
| pSNIbc | 16 |
| pSNIa | 624 |
| zSNII | 357 |
| zSNIbc | 40 |
| zSNIa | 824 |
| AGN | 906 |
| SLSN | 3 |
| SNIb | 10 |
| SNIc | 12 |
| SNII | 64 |
| SNIa? | 41 |
| SNIa | 499 |
| Total | 10,258 |
Download table as: ASCIITypeset image
Some of the SN candidates in the catalog have associated notes. Notes indicate SN where the typing spectrum was obtained by other groups (and is not included in the SDSS data release) and indicate SN candidates that may have peculiar features. The bulk of the spectroscopically identified SN Ia are consistent with normal SN Ia features, but a few were identified as having some combination of peculiar spectral and light curve features. We did not search for these peculiar features in a systematic way, but we have noted the likely peculiar features that were found. Some SN Ia have poor fits to the SN Ia light curve model or unlikely parameters for normal SN Ia, but we have not noted these, preferring to just present the fit parameters. Table 4 describes the codes that may appear in the notes column (item 138) of Table 1.
Table 4. Explanation of SN Notes column (Item 136)
| Note | Explanation |
|---|---|
| 1 | SN typing based on spectra obtained by groups outside SDSS |
| The spectra used for typing are not included in the data release | |
| 2 | Peculiar type Ia SN possibly similar to sn91bg |
| 3 | Peculiar type Ia SN possibly similar to sn00cx |
| 4 | Peculiar type Ia SN possibly similar to sn02ci |
| 5 | Peculiar type Ia SN possibly similar to sn02cx |
Download table as: ASCIITypeset image
4. Photometric Classification
Our table of candidates includes 10,258 entries, which include transients from a variety of sources including different SN types. While we expect that researchers who want to analyze our data will apply their own methods to our photometric data, we provide the results of our classification method as a reference and guide to future analyses. In addition, our classification data provides supplemental information for those who may wish to consider analyses similar to the analysis of Campbell et al. (2013) and Jones et al. (2017a, 2017b), who considered a photometrically identified sample with redshifts determined from galaxy spectra.
This section describes our method for photometric classification of the SN candidates. The method is similar to previous descriptions (Sako et al. 2011; Campbell et al. 2013), but has been refined as detailed below. The first step in our classification is to reject likely non-SN events because we have detected variability over two or more seasons. The exact nature of these sources is not known, but the majority are most likely variable stars and active galactic nuclei. A total of 3225 are identified as "Variable" in Table 2.
All remaining candidates showed variability during only a single season and are therefore viable SN candidates. Their light curves were then analyzed with the Photometric SN IDentification (PSNID) software (Sako et al. 2011), first developed for spectroscopic targeting and subsequently extended to identify and analyze photometric SN Ia samples. In short, the software compares the observed photometry against a grid of SN Ia light curve models and core-collapse SN (CC SN) templates, and computes the Bayesian probabilities of whether the candidate belongs to a Type Ia, Ib/c, or II SN. The technique is similar to that developed by Poznanski et al. (2007), except that we subclassify the CC SN into Type Ib/c and II.
PSNID is capable of performing light curve fits with different priors; we provide fits using both a spectroscopic redshift and a unknown redshift. For the purposes of typing, we use the spectroscopic redshift when available. Otherwise we use a redshift prior that is flat over the sensitive range of SDSS. We show in Figure 4 the results of the PSNID fit for redshift using the flat redshift prior for a sample of lightcurves that have spectroscopic identification as type SN Ia and spectroscopically measured redshifts. The redshifts computed by PSNID are in rough agreement with the spectroscopically measured redshifts, but there are noticeable biases at some redshifts. While the estimated errors at high redshift are quite large, there are a large number of outliers at low redshifts. These outliers do not indicate a problem with the method since it is possible to have the correct typing even with a redshift that is incorrect. For this reason, we will use other methods to determine the purity and efficiency of our typing method. However, the outliers do indicate the difficulty of trying to extract SN Ia parameters from the photometric data alone; we have not attempted to quantify the biases in our fits. Fit parameter distributions of the photometrically identified sample with spectroscopically measured redshifts are more reliable, and fit parameter distributions using the SALT2 model (Guy et al. 2007, 2010) are shown in Section 7.

Figure 4. Distribution redshifts fitted by PSNID for the SN Ia hypothesis using a flat redshift prior vs. the spectroscopically measured redshift. The error bars indicate the error estimates calculated by PSNID. The SN sample consists of all 499 SN Ia that were identified spectroscopically. A reference line is shown where the PSNID redshift is equal to the spectroscopically determined redshift.
Download figure:
Standard image High-resolution imageExtensive tests and tuning were performed using the large (but still limited) sample of spectroscopic confirmations from SDSS-II and simulations as described in Sako et al. (2011). The light curve templates used in the analysis presented here are the same as those from Sako et al. (2011). PSNID and the templates are now part of the SNANA package45 (Kessler et al. 2009b).
The Bayesian probabilities are useful because they represent the relative likelihood of SN types, whereas the best-fit minimum reduced χ2 ( ), or more precisely the fit probability Pfit, provides an absolute measure of the likelihood. The combination of the Bayesian probability (PIa) and the goodness-of-fit (Pfit) provides reliable classification of SN Ia candidates. The expected level of contamination and efficiency can be estimated from either large data sets or simulations. Sako et al. (2011) used this method to identify SN Ia candidates from SDSS-II. The SN Ia classification purity and efficiency were estimated to be 91% and 94%, respectively. The one major drawback of this techinique, however, was the general unreliability of classifying CC SN.
), or more precisely the fit probability Pfit, provides an absolute measure of the likelihood. The combination of the Bayesian probability (PIa) and the goodness-of-fit (Pfit) provides reliable classification of SN Ia candidates. The expected level of contamination and efficiency can be estimated from either large data sets or simulations. Sako et al. (2011) used this method to identify SN Ia candidates from SDSS-II. The SN Ia classification purity and efficiency were estimated to be 91% and 94%, respectively. The one major drawback of this techinique, however, was the general unreliability of classifying CC SN.
To make further improvements, we developed an extension to PSNID that uses the Bayesian classification described above as an initial filter, but subsequently refines the classification using a kd-tree nearest-neighbor (NN) technique. We call this method PSNID/NN, and it is based on the fact that different SN types populate a distinct region in extinction, light-curve shape, and redshift parameter space when fit to an SN Ia model. This is illustrated in Figure 5. SN Ib/c are generally redder (large AV) and they fade more rapidly (large Δm15(B)) compared to SN Ia. SN II, on the other hand, have broad, flat light curves (small Δm15(B)). The PSNID fits have an artificial limit at AV = 3, as can by the concentration of points along the line AV = 3. These points arise from CC SN which have light curves that are much redder than a normal SN Ia. As described below, this method makes substantial improvements to both SN Ia and CC SN classification.

Figure 5. Regions occupied by SN Ia (black), SN Ibc (red) and SN II (blue) in Δm15(B) − AV space in different redshift slices for a simulated SDSS-II SN Survey. The panels are z < 0.1 (top left), 0.1 < z < 0.2 (top right), 0.2 < z < 0.3 (middle left), 0.3 < z < 0.4 (middle right), z > 0.4 (bottom left), and all z (bottom right).
Download figure:
Standard image High-resolution imageIn this method, every SN in the data sample is compared against a training set and the most likely type is determined from the statistics of its neighbors in a multi-dimensional parameter space. Ideally, the training set is a large, uniform, and unbiased sample of spectroscopically confirmed SN, but such training sets do not exist at the low-flux limit of the SDSS-II SN sample. Our current implementation, therefore, uses simulated SN from SNANA. The simulation is based on well-measured CC SN template light curves, which are used to simulate events of different magnitudes and redshifts. However, the underlying library is small (only 42 CC SN template light curves), and adequacy of this sample size has yet to be rigorously verified. We simulated 10 seasons worth of SN candidates using a mix of SN Ia, SN Ib/c, and SN II identical to that used in the SN Classification Challenge (Kessler et al. 2010a, 2010c). For each SN candidate in the data sample, we calculate Cartesian distances in three-dimensional parameter space (AV, Δm15(B), z) to each simulated SN (labeled i) using the following formula:

where cz,  , and
, and  are coefficients determined and optimized using simulations for both the data and training sets. The classification probabilities are determined by counting the numbers of SN Ia, SN Ib/c, and SN II in the training set that are within a certain distance dmax. Since this distance is degenerate with the overall normalization of the other three coefficients, we set dmax = 1.0. The optimized set of coefficients are cz = 160,
are coefficients determined and optimized using simulations for both the data and training sets. The classification probabilities are determined by counting the numbers of SN Ia, SN Ib/c, and SN II in the training set that are within a certain distance dmax. Since this distance is degenerate with the overall normalization of the other three coefficients, we set dmax = 1.0. The optimized set of coefficients are cz = 160,  , and
, and  assuming dmax = 1.
assuming dmax = 1.
For each SN candidate in the data sample we count the number of simulated SN from each type Ntype within dSN < dmax. The NN probabilities PNN,type are then determined using,

The final classification is performed using the Bayesian, NN, and fit probabilities. For a candidate to be a photometric SN Ia candidate, we require
- 1.PIa > PIbc and PIa > PII.
- 2.PNN,Ia > PNN,Ibc and PNN,Ia > PNN,II.
- 3.Pfit ≥ 0.01 for SN Ia model.
- 4.Detections at −5 ≤ Trest ≤ +5 days and +5 < Trest ≤ +15 days.
For the photometric SN Ib/c candidates, we require,
- 1.(PIbc > PIa and PIbc > PII) or (PIa > PIbc and PIa > PII).
- 2.PNN,Ibc > PNN,Ia and PNN,Ibc > PNN,II.
Finally, for the photometric SN II candidates, we require
- 1.(PII > PIa and PII > PIbc) or (PIa > PIbc and PIa > PII).
- 2.PNN,II > PNN,Ia and PNN,II > PNN,Ibc.
Here, Trest is the rest-frame phase in days relative to B-band maximum brightness. We impose no requirement on detections at any particular Trest for the CC SN selection. The classification is performed using a spectroscopic redshift prior if a spectrum of either the SN candidate or its host galaxy is available. In these cases, the candidates are classified as zSN Ia, zSN Ibc, or zSN II in Table 2. Otherwise, we use a flat redshift prior and the candidates are denoted pSN Ia, pSN Ibc, or pSN II.
All candidates that do not meet any of the criteria above are declared "unknown." The statistics of the SN candidate classification are shown in Table 3. Simulation results are shown in Figure 6 where we compare classification performance between the Bayesian-only method and with the NN probabilities. For the Bayesian-only method, the SN Ia classification figure-of-merit (defined as the product of the efficiency and purity) has a very broad maximum when we require PIa > 0.5, where the efficiency and purity are 98% and 90%, respectively. For the Bayesian with the NN probabilities, the figure-of-merit also peaks for PIa > 0.5, where the efficiency and purity are both 96%. Note the substantial improvement in the purity at the expense of some reduction in efficiency. This level of purity is not attainable even with the most stringent cut (e.g., PIa > 0.99) with the Bayesian-only method. The full summary of efficiencies and purities of classification of all SN types with flat-z and spec-z priors is listed in Table 5.

Figure 6. SN Ia photometric classification efficiency (black), purity (red), and figure of merit (product of the efficiency and purity; blue) as a function of the PIa probability cut for simulated SDSS-II SN data. The top panels show results from Bayesian-only (left) and with the nearest-neighbor extension (PSNID/NN) for a flat redshift prior. The bottom panels show the same for a spectroscopic redshift prior. We required log(Pfit) > −4.0. Note that the purity using the Bayesian-only method is never above ∼93%.
Download figure:
Standard image High-resolution imageTable 5. PSNID/NN Typing Efficiency and Purity
| SN Type | z-prior | Efficiency | Purity |
|---|---|---|---|
| Ia | flat | 97.5% | 94.8% |
| ⋯ | zspec | 96.5% | 95.8% |
| Ibc | flat | 34.3% | 85.5% |
| ⋯ | zspec | 38.0% | 82.4% |
| II | flat | 68.4% | 96.6% |
| ⋯ | zspec | 54.9% | 95.8% |
Download table as: ASCIITypeset image
Although our classification method represents the state-of-the-art for photometric identification of SN Ia (Kessler et al. 2010a), whether it is sufficiently high efficiency and purity for a particular analysis will have to be determined on a case-by-case basis. In particular, our spectroscopic and photometric samples have biases that may be important (and are described in more detail below). In general, it will be necessary to make corrections using simulated data, and to evaluate the systematic errors associated with the corrections.
5. Photometry
Light curves are constructed using the Scene Modeling Photometry software (SMP; Holtzman et al. 2008). SMP assumes that the pixel data can be described by the sum of a point source that is fixed in space but varying in magnitude with time, a galaxy background that is constant in time but has an arbitrary spatial distribution, and a sky background that is constant over a wider area but varies in brightness at each observation. The galaxy background is parameterized as an arbitrary amplitude on a 15 × 15 grid of pixels of size 0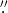 6. The fitting process accounts for the variations in point-spread function (PSF) to model the distribution of light for each night of observation. In order to separate the SN light from the galaxy background, it is necessary to have some images where the SN flux is known. The most convenient source of known flux images are the pre-explosion images and images long after the light has faded where the flux is known to be zero. The accuracy of determining the galaxy background depends strongly on the number of these zero-flux images. The number of zero-flux images varies. The median values are 8, 12, 12, 13, and 8 for u, g, r, i, and z bands, respectively. The SN magnitudes and SDSS reference stars on the same image are measured simultaneously using the same PSF so the SN magnitudes are measured relative to a calibrated SDSS star catalog.
6. The fitting process accounts for the variations in point-spread function (PSF) to model the distribution of light for each night of observation. In order to separate the SN light from the galaxy background, it is necessary to have some images where the SN flux is known. The most convenient source of known flux images are the pre-explosion images and images long after the light has faded where the flux is known to be zero. The accuracy of determining the galaxy background depends strongly on the number of these zero-flux images. The number of zero-flux images varies. The median values are 8, 12, 12, 13, and 8 for u, g, r, i, and z bands, respectively. The SN magnitudes and SDSS reference stars on the same image are measured simultaneously using the same PSF so the SN magnitudes are measured relative to a calibrated SDSS star catalog.
A complete set of light curve photometric data for all 10,258 SN candidates is given on the SDSS Data Release web page (SDSS 2013). The format of the data is described on the web page and is the same as the previously released first-year data sample (Holtzman et al. 2008). The magnitudes quoted in these data files, and elsewhere in this paper, are the SDSS standard inverse hyperbolic sine magnitudes defined by Lupton et al. (1999). Magnitudes are given in the SDSS native system and differ from the AB system by an additive constant given in Section 5.2. The fluxes in those files, however, have been AB-corrected and are expressed in μJ. The magnitudes and fluxes are reported in a way that is consistent with the first-year data sample except that the calibration of SDSS native magnitudes to μJ has changed as described below in Section 5.2. Quality flags defined by Holtzman et al. (2008) are provied for each photometric measurement. Special attention should be given to the non-zero flags as they are indicators of subtle problems in SMP fitting procedure.
5.1. Photometric Uncertainties
A substantial effort has been made to ensure accurate estimates of the uncertainties in the SDSS light curve flux measurements. An important feature of SMP is that it works on the original images (i.e., without resampling pixels). Resampling introduces pixel-to-pixel correlations which are cumbersome to treat correctly; in the original images the dominant errors—at least for low fluxes—are well understood fluctuations from photon statistics and read-noise, which are uncorrelated between pixels. The SMP model propagates the image pixel errors to combined fit to the SN flux and the galaxy model. The galaxy model is in most cases well constrained by the many zero-flux images, but in any event the uncertainty in the galaxy model is included in the uncertainty in the SN flux. In addition to the pixel statistical uncertainty, SMP computes a "frame error" that accounts in an approximate way for uncertainties that are important at high flux such as zeropoint errors and flat-fielding errors.
The error model was tested by Holtzman et al. (2008) using pre-explosion epochs (known zero flux), artificial supernovae (computer generated), and real stars. The conclusion was that the error model provides a good description of the observed photometric errors.
After running the SMP code, we re-examined the photometric errors by examining the light curve residuals relative to the SALT2 (Guy et al. 2010) model. We also investigated the distribution of residuals using pre-explosion epochs, where the residuals do not depend on the SN Ia model. For these data the largest errors arise from statistical uncertainties and possible errors in modeling the galaxy background light. We also examined the distribution of residuals relative to the SALT2 light curve model when there was a significant signal (more than 2σ above the sky background). In this latter case, uncertainties in the light curve model and zeropoints contribute to the width of the distribution of residuals. For these tests we used spectroscopically confirmed SN Ia excluding peculiar types and further limited the sample to those SN whose SALT2 fit parameters indicated normal stretch  and low extinction c < 0.2. The g-band distributions of the normalized residuals (residual divided by the uncertainty) are shown in left-hand panels of Figure 7. A normal Gaussian distribution (not a fit) is shown for comparison. While both distributions are (as expected for the SMP technique) quite close to the expected normal Gaussian, the pre-explosion epoch distribution (upper left) is slightly wider than the curve and the distribution with significant signal (σ > 2) is narrower. The normalized residual distribution for the pre-explosion epochs could be larger if the photometry underestimates the error in modeling the galaxy background. When there is significant signal, the distribution of normalized residuals could be smaller because of an overestimate of the zero-pointing error or the light curve model uncertainty, which is included in the estimated errors. Since the zero-point errors are at least partially correlated between epochs, the fit parameters (especially the SN color parameter) can absorb part of the zero-point error, and therefore decrease the width of the distribution of residuals. While the measurement errors are considerably larger in u and z bands, the distribution of the normalized residuals are similar for the other SDSS filters, indicating that the error estimates are approximately correct.
and low extinction c < 0.2. The g-band distributions of the normalized residuals (residual divided by the uncertainty) are shown in left-hand panels of Figure 7. A normal Gaussian distribution (not a fit) is shown for comparison. While both distributions are (as expected for the SMP technique) quite close to the expected normal Gaussian, the pre-explosion epoch distribution (upper left) is slightly wider than the curve and the distribution with significant signal (σ > 2) is narrower. The normalized residual distribution for the pre-explosion epochs could be larger if the photometry underestimates the error in modeling the galaxy background. When there is significant signal, the distribution of normalized residuals could be smaller because of an overestimate of the zero-pointing error or the light curve model uncertainty, which is included in the estimated errors. Since the zero-point errors are at least partially correlated between epochs, the fit parameters (especially the SN color parameter) can absorb part of the zero-point error, and therefore decrease the width of the distribution of residuals. While the measurement errors are considerably larger in u and z bands, the distribution of the normalized residuals are similar for the other SDSS filters, indicating that the error estimates are approximately correct.

Figure 7. The normalized residuals for SN Ia light curve fits to the g-band data before (left-hand panels) and after (right-hand panels) the adjustment described in the text. The top panels use data prior to the SN explosion ("Early points"), which is therefore independent of the light curve model. The bottom panels show the residuals for points where the detected flux is two or more standard deviations above background ("Significant points").
Download figure:
Standard image High-resolution imageBased on these distributions, we adjusted the errors according to the prescription

The constant cf was adjusted to result in an rms of unity for the pre-explosion epoch distributions. These small adjustments are within the errors quoted by Holtzman et al. (2008). The values used for the error adjustments for all five filters are shown in Table 6. The resulting g-band distributions of normalized residuals are shown on the right-hand side of Figure 7. Our choice of the form in Equation (3) also slightly reduces the width of the distribution of residuals with σ > 2. We did not attempt additional modifications to the errors to bring the σ > 2 distribution closer to a normal Gaussian because of the additional uncertainties in interpretation. As a consequence, our error adjustment has the effect of deweighting low flux measurements relative to measurements with significant flux. The adjustment has the most effect on u-band, where it is common to have many points measured with large errors. The overall SALT2 lightcurve fit mean confidence level (derived from the χ2/dof) is increased from 0.28 to 0.57 as a result of this change.
Table 6. Normalized Residuals
| Band | Nominal | Adjustment | Corrected | Corrected s < 1 | Corrected s > 2 |
|---|---|---|---|---|---|
| u | 1.182 | 630 | 1.003 | 1.057 | 0.932 |
| g | 1.159 | 85 | 1.003 | 0.994 | 0.842 |
| r | 1.196 | 200 | 1.000 | 0.947 | 0.892 |
| i | 1.222 | 550 | 1.003 | 0.891 | 0.876 |
| z | 1.181 | 2600 | 1.002 | 0.956 | 0.721 |
Download table as: ASCIITypeset image
We also observe a small, but statistically significant offset in the mean residual of the pre-explosion epochs. The largest offset was found for r-band where the offset was 0.12σ, where σ is the width of the normalized distribution. We did not correct this offset because we were uncertain whether subtracting a constant flux from all epochs would be an appropriate correction. The flux offsets are approximately 1% of the peak flux of a SN Ia at redshift z = 0.35. If they were applied to our data, the centroid of fit for the cosmological parameters (see Section 7.4 and Figure 19) would shift by 0.05 in ΩΛ and 0.16 in ΩM.
5.2. Star Catalog Calibration
The star catalog calibration is discussed in detail by Betoule et al. (2013), where the SDSS stellar photometry calibration is described in detail and the SDSS photometry is compared with the SNLS photometry. The starting point for the SDSS SN calibration is a preliminary version of the Ivezić et al. (2007) star catalog that was used for SMP photometry in Holtzman et al. (2008). This catalog uses the stellar locus to calibrate the stellar colors but relies on photometry from the SDSS Photometric Telescope (PT) to establish the relative zeropoint for r-band. As explained in detail by Betoule et al. (2013), there is a significant flat-fielding error in the PT photometry, leading to a photometry that was biased as a function of declination. We determined corrections to the Ivezić et al. (2007) star catalog using SDSS Data Release 8 (Aihara et al. 2011), whose calibration is based on the method of Padmanabhan et al. (2008). This method, the so-called "Ubercal" method, re-determines the nightly zeropoints based only on the internal consistency of the 2.5 m telescope observations. Our adjustments to the stellar photometry were typically within a range of 2%, but corrections of up to 5% were made in the u-band. The corrections improved the agreement with the SNLS photometry. Instead of recomputing the SN magnitudes relative to the new star catalog, we simply applied the corrections to the SN magnitudes found using the Ivezić et al. (2007) catalog.
Neither the star catalog of Ivezić et al. (2007) (based on the stellar locus) nor SDSS Data Release 8 attempts to improve the absolute calibration of SDSS photometry. The photometry is tied to an absolute scale by BD+17°4708 using the magnitudes determined by Fukugita et al. (1996). We have followed Holtzman et al. (2008) and re-determined the absolute scale using the SDSS filter response curves (Doi et al. 2010) and the HST standard spectra (Bohlin 2007) given in the HST CALSPEC database (HST CALSPEC 2006). When the synthetic photometry of these standards is compared to the SDSS PT photometry, we obtain an absolute calibration, which is expressed as "AB Offsets" from the nominal SDSS calibration (see Oke & Gunn 1983 for a description of the AB magnitude system). The differences between our current results and those of Holtzman et al. (2008) are that we have: (1) used the recently published SDSS filter response curves, (2) used more recent HST spectra, and (3) re-derived the PT to 2.5 m telescope photometric transformation, including corrections for the recently discovered non-uniformity of the PT flat field. Details of AB system calibration may be found in Betoule et al. (2013). Table 7 lists the AB offsets to be applied to the SDSS SN data. We use the average of three solar analogs (P041C, P177D, and P330E) because these stars are similar in color to the stars used to determine the (assumed) linear color transformation between the PT and 2.5 m telescope. The uncertainty is calculated from the dispersion of the results for the solar analogs. The value determined for BD+17°4708 is given as a consistency check. The most significant numerical difference between the AB offsets presented here and Table 1 of Holtzman et al. (2008) is the u-band offset with ΔAB ∼ 0.03, which differs primarily because of the different filter response curve for u-band, as discussed in detail by Doi et al. (2010).
Table 7. SDSS AB Offsets
| Band | AB Offset |
|---|---|
| u | −0.0679 |
| g | +0.0203 |
| r | +0.0049 |
| i | +0.0178 |
| z | +0.0102 |
Note. All magnitudes in this paper are SDSS asinh magnitudes (Lupton et al. 1999) in the native system used by SDSS. The AB offsets should be added to the native magnitudes to obtain magnitudes calibrated to the AB system. Fluxes are expressed in μJ and have the AB offsets already applied. The derivation of the AB offsets is described in the text and in more detail in Betoule et al. (2013).
Download table as: ASCIITypeset image
It is important to note that the SN light curve photometry is given in the SDSS natural system—the same system that is used for all the SDSS data releases. The AB offsets must be added to the SN light curve magnitudes in order to place them on a calibrated AB system.
5.3. u-band Uncertainties
There has been some concern in the literature about the accuracy of the u-band photometry. The observations reported by Jha et al. (2006), for example, used a diverse set of telescopes and cameras and were not supported by a large, uniform survey like SDSS. For these reasons, one might question whether there are substantial errors in the u-band calibration. For example, in the SNLS3 cosmology analysis (Conley et al. 2011) measurements in the u band are de-weighted. The quality of the SDSS u-band data benefits greatly from an extensive, accurate star catalog of SDSS Stripe 82. For example, Figure 8 shows the variations in stellar magnitudes in the Ivezić et al. (2007) catalog, showing a repeatability of 0.03 mag over most of the magnitude range. The point at magnitude 13.7 is based on a single star, which shows an anomalously high rms difference. These secondary stars, which are the SMP photometric references, are measured several times during photometric conditions so that the calibration error is typically 0.01–0.02 mag per star. The SMP normally uses at least three calibration stars in u-band so that the typical zero point error (which is included in the SMP frame error) is comparable to the overall u-band scale error of 0.0089 (Betoule et al. 2013).

Figure 8. The rms photometric scatter of repeated measurements of SDSS Stripe 82 stars in u-band.
Download figure:
Standard image High-resolution imageA check of SDSS SN photometry is described in Mosher et al. (2012), who compared SDSS and Carnegie Supernova Project (Contreras et al. 2010) measurements on a subset of SN Ia observed by both surveys. For the 32 u-band observations, they find agreement of 0.001 ± 0.014 mag, and comparable agreement in the other bands.
6. Spectra
SDSS SN spectra were obtained with the Hobbey-Eberly Telescope (HET), the Apache Point Observatory 3.5 m Telescope (APO), the Subaru Telescope, the 2.4 m Hiltner Telescope at the Michigan-Dartmouth-MIT Observatory (MDM), the European Southern Observatory (ESO) New Technology Telescope (NTT), the Nordic Optical Telescope (NOT), the Southern African Large Telescope (SALT), the William Herschel Telescope (WHT), the Telescopio Nazionale Galileo (TNG), the Keck I Telescope, and the Magellan Telescope. Table 8 provides details of the instrumental configurations used at each telescope. These observations resulted in confirmation of 499 SN Ia, 22 SN Ib/c, and 64 SN II. A total of 1360 unique spectra are part of this data release. In many cases, we provide extractions of the SN and host galaxy spectra separately. The majority of the SN spectra suffer contamination from the host galaxy, and we did not attempt to remove that contamination. Contamination of the galaxy spectrum by SN light may also be an issue in some of the galaxy spectra.
Table 8. Instrument Configurations
| Telescope | Instrument | Wavelength Range | Resolution | Reference or Link |
|---|---|---|---|---|
| Å | Å | |||
| HET | LRS | 4070–10,700 | 20 | Hill et al. (1998) |
| ARC | DIS | 3100–9800 | 8–9 | Linka |
| Subaru | FOCAS | 3650–6000 | 8 | Kashikawa et al. (2000) |
| 4900–9000 | 12 | |||
| WHT | ISIS | 3900–8900 | 4.3 and 7.5 | Linkb |
| MDM | CCDS | 3800–7300 | 15 | Linkc |
| Keck | LRIS | 3200–9400 | 4.5 and 8.9 | Oke et al. (1995) |
| TNG | DOLORES | 3800–7300 | 10 | Linkd |
| NTT | EMMI | 3800–9200 | 17 | Dekker et al. (1986) |
| NOT | ALFOSC-FASU | 3200–9100 | 21 | Linke |
| Magellan | LDSS3 | 3800–9200 | 9.5 | Linkf |
| SALT | RSS | 3800–8000 | 5.7 | Burgh et al. (2003) |
Notes.
a http://www.apo.nmsu.edu/arc35m/Instruments/DIS/#B b http://www.ing.iac.es/PR/wht_info/whtisis.html c http://www.astronomy.ohio-state.edu/MDM/CCDS/ d http://www.tng.iac.es/instruments/lrs/ e http://www.not.iac.es/instruments/alfosc/ f http://www.lco.cl/telescopes-information/magellan/instruments/ldss-3Download table as: ASCIITypeset image
Most SN spectra were taken when the SN candidates were near peak brightness. The distribution of observation times relative to peak brightness is shown in Figure 9. Of the 889 SN candidates with measured spectra, 177 have two or more spectra, and 16 have five or more spectra.

Figure 9. Distribution in time when SN Ia spectra were observed relative to peak brightness in B-band.
Download figure:
Standard image High-resolution imageThe spectra were all observed using long slit spectrographs, but they were observed under a variety of conditions with the procedures determined by the individual observers. Some spectra were observed at the parallactic angle while other spectra were observed with the slit aligned to pass through both the SN and the host, or nearest, galaxy. The different slit sizes and observing conditions result in slit losses that are not well characterized for most of the spectra. The spectra were processed by the observers, or their collaborators, using procedures developed for each particular telescope.
The spectra are calibrated to standard star observations, but with the exception of the Keck spectra, the quality of the calibration is not verified. Telluric lines are generally removed, but residual absorption features or sky lines may be present. We provide uncertainties for all the spectra, but the uncertainties are generally limited to statistical errors. Because of the non-uniformities in the sample, and uncontrolled systematic errors, we cannot make a general statement about the accuracy of all the spectra. Some subsamples of spectra have been subjected to detailed analyzes (Konishi et al. 2011a, 2011b; Östman et al. 2011; Foley et al. 2012) and more detailed information on corrections and systematic errors can be found in these references.
The SN spectral classification and redshift determination methods are described in Zheng et al. (2008). Briefly, the spectra were compared to template spectra and the best matching template spectrum was determined. Each spectrum was classified as "None" (no preferred match, usually because the spectrum was too noisy), "Galaxy" (spectrum of a normal galaxy with no evidence for a SN), "AGN" (spectrum of an active galaxy) or a SN type: "Ia" (Type Ia), "Ia?" (possible Type Ia), "Ia-pec" (peculiar Type Ia), "Ib" (Type Ib), "Ic" (Type Ic), or "II" (Type II). The redshifts are generally determined by cross-correlation with template spectra, but for some of the galaxy redshifts observed in 2008 were determined by measuring line centroids. All redshifts are presented in the heliocentric frame.
The list of spectra is displayed in Table 9. Each observation is uniquely specified by the SN candidate ID and spectrum ID. The observing telescope is listed and the classification of the spectrum described above is listed in the column labeled "Evaluation." Separate redshifts are given for the galaxy and SN spectra, when available. The mean value of the SN Ia redshifts are offset from the host galaxy by 0.0022 ± 0.0004 (galaxy redshift minus SN Ia redshift). The offset probably arises from variations in the SN template spectra that were used to determine the SN redshifts. A similar offset (0.003) was reported for the first-year sample; see Zheng et al. (2008) for the result and a discussion of the offset.
Table 9. Spectroscopic Data
| SDSS IDa | Spec IDb | Telescope | Type(s) | Observation Date | Evaluation | SN Redshift | Galaxy Redshift |
|---|---|---|---|---|---|---|---|
| 701 | 2795 | APO | Gal | 2008 Sep 02 | Gal | ⋯ | 0.2060 |
| 703 | 1963 | NTT | Gal | 2007 Sep 21 | Gal | ⋯ | 0.2987 |
| 722 | 58 | APO | SN,Gal | 2005 Sep 09 | Ia | 0.087 | 0.0859 |
| 739 | 59 | APO | SN,Gal | 2005 Sep 09 | Ia | 0.105 | 0.1071 |
| 744 | 60 | APO | SN,Gal | 2005 Sep 08 | Ia | 0.123 | 0.1278 |
| 762 | 61 | APO | SN,Gal | 2005 Sep 09 | Ia | 0.189 | 0.1908 |
| 774 | 62 | APO | SN,Gal | 2005 Sep 09 | Ia | 0.090 | 0.0937 |
| 774 | 577 | MDM | SN | 2005 Sep 17 | Gal | ⋯ | 0.0933 |
| 779 | 592 | HET | Gal | 2005 Dec 29 | Gal | ⋯ | 0.2377 |
| 841 | 2757 | HET | Gal | 2008 Jan 06 | Gal | ⋯ | 0.2991 |
| 911 | 1894 | APO | SN | 2007 Nov 14 | Gal | ⋯ | 0.2080 |
| 1000 | 2827 | APO | Gal | 2008 Sep 27 | Gal | ⋯ | 0.1296 |
| 1008 | 436 | APO | SN,Gal | 2005 Nov 26 | Gal | ⋯ | ⋯ |
| 1008 | 2752 | APO | Gal | 2008 Sep 27 | Gal | ⋯ | 0.2260 |
| 1032 | 149 | APO | SN,Gal | 2005 Sep 25 | Ia | 0.133 | 0.1296 |
| 1112 | 87 | HET | SN,Gal | 2005 Sep 26 | Ia | 0.258 | 0.2577 |
| 1114 | 270 | APO | SN,Gal | 2005 Nov 04 | II | 0.031 | 0.0245 |
| 1119 | 189 | Subaru | SN,Gal | 2005 Sep 27 | Ia | 0.298 | 0.2974 |
| ⋯ | |||||||
Notes.
aInternal SN candidate designation. bInternal spectrum identification number.Only a portion of this table is shown here to demonstrate its form and content. A machine-readable version of the full table is available.
Download table as: DataTypeset image
The source of the redshift can generally be discerned from the size of the uncertainty. For redshifts measured from broad features of the SN spectrum, the uncertainty floor is set to δz = 0.005. For redshifts measured from narrow galaxy lines, the uncertainty floor is set to δz = 0.0005. Redshifts measured from the SDSS and BOSS spectrographs have uncertainties set by their respective pipelines as quoted in their catalogs.
7. SN Ia Sample and SALT2 Analysis
We expect that future researchers making use of our data will want to extract their own light curve parameters from our photometric data, but we provide results from two light curve fitting programs as a references for future work. Our fits may also be useful for applications that do not require the highest precision for the light curve parameters. Using the SNANA version 10.38 package (Kessler et al. 2009b) implementation of the SALT2 SN Ia light curve model (Guy et al. 2010)46 The first uses fixed spectroscopic redshifts (either from the SN spectrum or the host galaxy), and fits four parameters: time of peak brightness (t0), color (c), the shape (stretch) parameter (x1), and the luminosity scale (x0). The second fit ignores spectroscopic redshift (when known) and includes the redshift as a fifth fitted parameter as described in Kessler et al. (2010b). For comparison, we have also used the MLCS2k2 light curve fitting method (Jha et al. 2007, JRK07), where the luminosity parameter Δ and the extinction parameter AV play similar roles to the SALT2 parameters x1 and c, respectively.
To ensure reasonable fits, we applied selection criteria as summarized in Table 10. Note that SN Ia fits are made regardless of the SN type classification. The SNANA input files for these fits are available on the data release web pages (SDSS 2013). We also placed some requirements on the photometric measurements that were used in the fit. We exclude epochs where SMP was determined to be unreliable (a photometric flag47 of 1024 or larger). Flags greater than 1024 are the result of poor quality fits or other inconsistencies in the data and can be taken as an indication of "bad data." Our data sample consists of 1142,004 photometric measurements and 68,535 (6%) have their photometric flag >1024. The flags are computed by SMP, and the discarded measurements are not expected to produce any bias. We also discard epochs earlier than 15 days or later than 45 days (in the rest frame). In addition, 152 epochs in 105 different SN were designated outliers based on visual inspection of the light curve fits and were not used in the light curve fits. All the photometric data (and the associated photometric flags) and the outlier epochs are included in both the ASCII and SNANA data releases. A list of the outlier epochs is included in the SNANA release.
Table 10. Selection Criteria for SALT2 Light Curve Fits
| SNANA Variable | MLCS2k2 | SALT2 (4-par) | SALT2 (5-par) |
|---|---|---|---|
| Redshifta | (0.45) | (0.7) | (⋯) |
| Redshift_errb | (0.011) | (0.011) | (⋯) |
| SNRMAXc | (3.0) | (3.0) | (3.0) |
| Trestmind | (10.0) | (10.0) | (0.0) |
| Trestmaxe | (0.0) | (0.0) | (10.0) |
Notes.
aMaximum redshift selected. bMaximum redshift uncertainty for 4-parameter fits. cMaximum signal-to-noise ratio among epochs in one band. dThe earliest epoch measured in days in the rest frame relative to maximum light in B-band must occur before this time. eThe latest epoch measured in days in the rest frame relative to maximum light in B-band must occur after this time.Download table as: ASCIITypeset image
Some representative 4-parameter fit results are shown in Table 11 (SALT2 4-parameter fits). We show a comparison of the 4-parameter SALT2 and MLCS2k2 fits in Figure 10, where SALT2 c is compared with MLCS2k2 AV and SALT2 x1 is compared with MLCS2k2 Δ. There is generally a strong correlation between the SALT2 and MLCS2k2 parameters (indicated by the lines shown), with modest scatter and some outliers. In particular, the MLCS2k2 Δ parameter spans a large range in the vicinity of x1 = −2 (fast-declining light curves). The correlation between the reddening parameters AV and c is tighter, with just a handful of outliers. There is also a clear color zeropoint offset between the fitters, c ≈ −0.1 when AV = 0. The color zeropoint offset is an artifact of the SALT2 model which defines an arbitrary zeropoint for color; the difference between SALT2 and MLCS2k2 has no physical significance. Figure 10 also shows the functional form of the fits performed on the combined SN Ia+SN Ia?+zSN Ia sample. We note that the conversions will result in biases when applied to particular subsamples especially in ranges of stretch and color that are not well populated.

Figure 10. Comparisons of the MLCS2k2 and SALT2 light-curve fit parameters for SN Ia from the spectroscopic (SNIa, SNIa?) or photometric (with host redshift; zSNIa) samples. The top panel shows the light curve shape parameters, MLCS2k2 Δ vs. SALT2 x1, for the 1259 SN Ia where these parameters were well measured. The solid purple curve is a cubic polynomial fit to the data, with coefficients as displayed, restricted to points with −3 < x1 < 4 and −1 < Δ < 2 (1236 objects; 443 SNIa, 26 SNIa?, 767 zSNIa). The bottom panel shows the reddening parameters, MLCS2k2 AV vs. SALT2 c, for 1265 SN Ia. The solid purple line is a linear regression fit using the Bayesian Gaussian mixture model of Kelly (2007), via the IDL routine linmix_err.pro, over the restricted data range −0.3 < c < 0.5 and −1 < AV < 2 (1248 objects; 447 SNIa, 26 SNIa?, 775 zSNIa). Fits were performed on the SN Ia and zSN Ia separately, which are shown in dashed blue and red lines, respectively. There will be slight biases if the conversions are performed outside the well-populated ranges of color and stretch. For clarity in display, the uncertainties on the data points are not shown, but they have been included in deriving the fits.
Download figure:
Standard image High-resolution imageTable 11. SALT2 4-parameter Fit Resultsa
| CID | Classification | zb | x0b | δx0b | x1b | δx1b | cb | δcb | tmaxb | δtmaxb | μc | δμc | Pc | χ2c | dofc |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 703 | zSNIa | 0.298042 | 5.43e-05 | 3.47e-06 | 0.73 | 0.63 | −0.01 | 0.05 | 53626.5 | 0.7 | 40.80 | 0.25 | 0.966 | 40.80 | 59 |
| 735 | zSNIa | 0.190858 | 8.82e-05 | 1.23e-05 | −2.66 | 0.58 | 0.01 | 0.09 | 53610.7 | 1.8 | 39.59 | 0.27 | 0.955 | 20.60 | 33 |
| 739 | SNIa | 0.107638 | 4.05e-04 | 3.34e-05 | −0.88 | 0.20 | −0.00 | 0.04 | 53609.5 | 1.1 | 38.31 | 0.19 | 0.001 | 58.80 | 29 |
| 744 | SNIa | 0.128251 | 2.74e-04 | 1.57e-05 | 1.37 | 0.37 | 0.06 | 0.03 | 53612.9 | 0.9 | 38.97 | 0.20 | 0.983 | 17.40 | 32 |
| 762 | SNIa | 0.191381 | 1.29e-04 | 4.84e-06 | 1.09 | 0.29 | −0.05 | 0.03 | 53625.2 | 0.3 | 40.04 | 0.20 | 0.802 | 46.90 | 56 |
| 774 | SNIa | 0.093331 | 6.30e-04 | 2.63e-05 | 0.79 | 0.19 | −0.05 | 0.03 | 53608.5 | 0.0 | 38.27 | 0.19 | 0.806 | 25.00 | 32 |
| 779 | zSNIa | 0.238121 | 7.72e-05 | 3.68e-06 | 0.46 | 0.38 | 0.02 | 0.04 | 53626.9 | 0.4 | 40.30 | 0.21 | 0.991 | 42.80 | 67 |
| 822 | zSNIa | 0.237556 | 6.82e-05 | 3.48e-06 | −0.38 | 0.54 | −0.09 | 0.04 | 53621.3 | 0.5 | 40.60 | 0.24 | 0.454 | 53.50 | 53 |
| 841 | zSNIa | 0.299100 | 5.59e-05 | 3.88e-06 | 0.33 | 0.64 | −0.14 | 0.05 | 53624.9 | 0.6 | 41.07 | 0.26 | 0.994 | 39.30 | 64 |
| 859 | zSNIa | 0.278296 | 6.57e-05 | 3.33e-06 | 0.68 | 0.51 | 0.03 | 0.04 | 53624.2 | 0.7 | 40.49 | 0.23 | 0.710 | 69.70 | 77 |
| 893 | zSNIa | 0.110133 | 8.20e-05 | 4.06e-06 | −1.18 | 0.45 | 0.04 | 0.04 | 53620.2 | 0.5 | 39.87 | 0.21 | 0.006 | 69.90 | 43 |
| 904 | zSNIa | 0.385316 | 3.79e-05 | 3.07e-06 | 1.13 | 2.42 | −0.28 | 0.07 | 53620.6 | 4.0 | 42.06 | 0.43 | 0.992 | 40.00 | 64 |
| 911 | zSNIa | 0.207264 | 4.97e-05 | 3.59e-06 | −0.39 | 0.74 | 0.23 | 0.06 | 53621.7 | 0.8 | 40.00 | 0.26 | 0.800 | 45.10 | 54 |
| 932 | zSNIa | 0.391335 | 3.13e-05 | 3.35e-06 | 3.39 | 1.38 | 0.01 | 0.07 | 53619.0 | 0.8 | 41.84 | 0.40 | 0.796 | 58.20 | 68 |
| 986 | zSNIa | 0.280578 | 4.22e-05 | 2.74e-06 | −0.23 | 1.03 | 0.01 | 0.06 | 53619.8 | 1.6 | 40.86 | 0.30 | 0.991 | 43.40 | 68 |
| ⋯ | |||||||||||||||
Notes.
aSelected columns relating to 4-parameter SALT2 light curve fits are shown here for guidance regarding the form and content of these columns. bIn the electronic edition z, x0, δx0, x1, δx1, c, δc, tmax, and δtmax are called zspecHelio, x0SALT2zspec, x1SALT2zspec, x1errSALT2zspec, cSALT2zspec, cerrSALT2zspec, peakMJDSALT2zspec, peakMJDerrSALT2zspec, respectively. cIn the electronic edition μ, δμ, P, χ2, and dof are called muSALT2zspec, muerrSALT2zspec, fitprobSALT2zspec, chi2SALT2zspec, and ndofSALT2zspec, respectively.Only a portion of this table is shown here to demonstrate its form and content. A machine-readable version of the full table is available.
Download table as: DataTypeset image
Similar data for the MLCS2k2 fits and SALT2 5-parameter fits may be found in the full machine readable table (see Table 1). The additional free parameter (z) introduces strong covariances between color (or extinction), light-curve width, and redshift. They are not shown in Figure 11, but we note that no obvious differences are seen in their distributions compared to the SN Ia and zSN Ia samples.

Figure 11. SALT2 color (top) and x1 as a function of redshift for the spectroscopic SN Ia (black) and zhost-Ia (red) samples. The zhost-Ia sample is noticeably redder (more positive values of c) than the spec-Ia sample, but the x1 distributions are indistinguishable.
Download figure:
Standard image High-resolution imageWe have also compared the SALT2 parameters x1 and c in Figure 11 for the 4-parameter fit sample, showing separately the sample where the redshift is obtained from the SN spectrum as opposed to the host galaxy spectrum. Both samples are affected in the same way by the photometric detection efficiency. We expect the sample with SN spectra to be biased because of the spectroscopic target selection and the efficiency of obtaining a usable spectrum. There is probably also some bias in the photometric selection, but the bias is constrained by highly efficiency for selecting SN Ia (see Section 4). Figure 11 shows no evidence of a bias in x1 between the spectroscopic and photometric samples, but a clear difference in c, which is consistent with the findings of Campbell et al. (2013) where the weighted mean SALT2 colors of the spectroscopically confirmed SN Ia where slightly bluer than for the whole sample (including many photometrically classified SN Ia). This effect is presumably because reddened Type Ia SN were less likely to be selected for spectroscopy. Both the spectroscopically identified and the photometrically identified samples show an increase in the average value of x1 with redshift: the spectroscopically identified sample has a slope of 1.27 ± 0.7 and the photometrically identified sample was 1.75 ± 0.60. These slopes are consistent with each other, but not consistent with zero, suggesting that the value of x1 is an important factor in the detection efficiency but less important in the spectroscopic identification efficiency.
7.1. Distance Moduli
We have used the results of our 4-parameter SALT2 fits to compute the distance modulus to the SDSS-II SN, excluding those events where the fit parameter uncertainty was large (δt0 > 1 or δx1 > 1). The distance moduli are presented in the on-line version of Table 1; a subset is displayed in Table 11. We used SALT2mu (Marriner et al. 2011), which is also part of SNANA, to compute the SALT2 α and β parameters and computed the distance modulus according to the relationship

where μ is the distance modulus, and Mx = −29.967 is the average magnitude of the SALT2 x0 parameter for a x1 = c = 0 SN Ia at 10 kpc, as determined from the SDSS SN Ia data. The parameter Mx is equivalent to the more commonly used SN Ia B-band magnitude except that it does not depend on any particular filter band-pass. The units of x0 are fixed in the SALT2 training but are arbitary in the sense that the scale is not fixed to any particular physical scale. We do not include a correction for host galaxy stellar masses as discussed in Lampeitl et al. (2010b) and Johansson et al. (2013). The results of the fit are α = 0.155 ± 0.010 and β = 3.17 ± 0.13. Only the spectroscopically confirmed SN Ia were used to determine these parameters and the intrinsic scatter was assumed to be entirely due to variations in peak B-band magnitude with no color variations (Marriner et al. 2011). Including the photometric SN Ia sample, we get α = 0.187 ± 0.009 and β = 2.89 ± 0.09. There is some tension between these between these results: the results for α differ by 2.4σ and the results for β differ by 1.8σ ignoring the fact that the samples are not statistically significant. However, we do not attach any particular significance to the difference since our errors ignore systematic effects.
There are differences in these distance moduli compared to the light curve fits reported for the SN Ia reported in Kessler et al. (2009a) and elsewhere (Lampeitl et al. 2010a). The differences arise from the following changes:
- 1.Re-calibration and updated AB offsets (Betoule et al. 2013).
- 2.Fitting ugriz instead of gri.
- 3.For MLCS2k2 an approximation of host-galaxy extinction from JRK07 was replaced with an exact calculation (effect is negligible).
- 4.
For the 103 SN previously published in Kessler et al. (2009a), the difference in μ versus redshift is shown in Figure 12 for MLCS2k2 and SALT2. For MLCS2k2 the difference is more nearly constant with redshift than SALT2 except in the lowest-redshift bin where the u band has an important effect. The change in the calibration is significant and is the most important improvement in the accuracy distance moduli.

Figure 12. Differences in distance modulus between the results in this paper and the results published in Kessler et al. (2009a) for (a) MLCS2k2 and (b) SALT2 are shown as a function of redshift.
Download figure:
Standard image High-resolution image7.2. SALT2 Versions
The results of the SALT2 fits depend on the version of the code used, the spectral templates, and the color law. Our fits use the SALT2 model as implemented in SNANA version 10.38 and the spectral templates and color law reported in Guy et al. (2010, G10). Most of the prior work with the SDSS sample used the earlier versions of the spectral templates and color law given in Guy et al. (2007, G07) with the notable exception of Campbell et al. (2013), which used G10. For the SDSS data, the largest differences in the fitted parameters arises from the difference in the color law between G07 and G10. The SDSS-II- SNLS joint light curve analysis paper on cosmology (Betoule et al. 2014) releases a new version of the SALT2 model that is based on adding the full SDSS-II spectroscopically confirmed SN sample to the SALT2 training set.
Figure 13 shows the different versions of the color law and the range of wavelengths sampled for each photometric band assuming an SDSS redshift range of 0 < z < 0.4. The color laws are significantly different, particularly at bluer wavelengths. Figure 14 shows a comparison of the SN fits for the SALT2 color parameter (c), where each point is a particular SN with both fits using the spectral templates from G10 but different color laws.

Figure 13. Color laws from Guy et al. (2007, dotted line) and (Guy et al. 2010, solid line). The horizontal lines (ugriz) indicate the range for the mean wavelength response of each filter, respectively, over the redshift range of 0.0 < z < 0.4. There is a significant difference for i-band and, at higher redshift, in g-band.
Download figure:
Standard image High-resolution image
Figure 14. Comparison of derived SALT2 c using color laws from Guy et al. (2007, 2010) for the spectroscopically confirmed SN Ia sample. The curve is a nominal straight line fit, where the errors along the horizontal axis are ignored and all data is given equal weight. The result is δc = 0.18 ∗ c + 0.00.
Download figure:
Standard image High-resolution imageAlthough there is some scatter, the relationship between the two fits can be described approximately by a line:

We conclude that the G07 color law results in a value of the c parameter that is 20% higher than G10 on average. The effects of the differences in the spectral templates and changes to the SNANA code are much smaller.
7.3. Comparison of SDSS u-band with Model
To address concerns about ultraviolet measurements, we compared our u-band data with the predictions of the SALT2 and MLCS2k2 models by fitting the gri band data and comparing the measured u-band flux with that predicted by the model. The results are shown in Figure 15 for the G07 model, the G10 model, and MLCS2k2. All the models predict too much u-band flux compared to our data at early times with the exception of the earliest point for the G10 model. Both the G07 and G10 models lie above MLCS2k2 in Figure 15, indicating that these models predict lower flux. We determine that the G10 model is on average 0.050 ± 0.008 magnitudes higher than our data, G07 is 0.038 ± 0.009 and mlcs2k2 is 0.156 ± 0.010 higher. These conclusions confirm the observations of Kessler et al. (2009a), who found that the first year of SDSS u-band data agree better with SALT2 than MLCS2k2. The SDSS light curve fits are relatively insensitive to this difference because of the poor instrumental sensitivity in the u-band; it is more important for the high redshift data where an accurate rest-frame u-band measurement is necessary to obtain an accurate measurement of the color.

Figure 15. Average u band residual for the SALT2 (G07 and G10) models and the MLCS2k2 model are shown (top). The measured u-band flux is compared with the prediction from the fit using g, r, and i band data only. The points are a weighted average of the residuals shown in 3-day intervals measured in the SN Ia rest frame. The bottom panel shows the same weighted average for the G10 model, but also shows the individual points that comprise the average.
Download figure:
Standard image High-resolution image7.4. Hubble Diagram and Cosmological Constraints
We compare the redshift determination from the 5-parameter SALT2 fit and spectroscopic redshift in Figure 16. This figure differs from Figure 4 in that we have used the more sophisticated SALT2 model for the fits. Good agreement between the two redshifts is seen for the SALT2 model although the photometric error is often large. Averaging SN in bins of redshift reveals a net redshift bias of the photometric redshifts relative to those measured spectroscopically. The bias has been seen previously (Kessler et al. 2010b; Campbell et al. 2013), and was shown to agree well with the bias observed with simulated SN Ia light curves. The lower panel in Figure 16 underscores the need to correct biases in the photometrically identified sample when a host redshift is not available.

Figure 16. Comparison of spectroscopic and light curve photometric redshifts for the confirmed SN Ia sample.
Download figure:
Standard image High-resolution imageFigure 17 shows the Hubble diagram for the SN that meet our fit selection criteria and have spectroscopic redshifts (δz < 0.01): the top panel (a) shows the 457 SN that have been typed with spectra and the bottom panel (b) shows the 827 SN where the redshift is determined from the host galaxy. The obvious outlier at z = 0.043 is the under-luminous SN2007qd, which was discussed by McClelland et al. (2010) as a possible explosion by pure deflagration (see also, Foley et al. 2013). The photometrically identified sample (b) in Figure 17 shows a considerably larger scatter as seen before in Campbell et al. (2013). The larger scatter is due to two effects: the lower signal-to-noise light curves of the fainter, higher redshift photometric sample and the contamination of CC SN at lower redshifts. The variance in magnitude relative to the nominal cosmology of the 451 spectroscopically identified SN Ia is 0.250 while we expect 0.234 when an intrinsic scatter of 0.14 is assumed. For the photometrically identified sample of 854 SN Ia the variance is 0.510 while 0.385 is expected. However, outliers in the photometrically defined sample account for much of the excess variance: if the 15 SN that lie more than 5σ from the nominal cosmology are removed, the variance of the photometrically identified sample drops to 0.437. Selection criteria to obtain a sample of photometrically identified SN for determination of cosmological parameters were presented previously (Campbell et al. 2013).

Figure 17. Hubble diagram of the spectroscopic SN Ia (top) and zhost-Ia (bottom). The large scatter in the zhost-Ia sample especially at low redshift (z < 0.2) is most likely due to contamination from CC SN.
Download figure:
Standard image High-resolution imageThe Hubble diagrams shown in Figure 17 are not corrected for biases due to selection effects. Since the SDSS SN survey is a magnitude limited survey a bias toward brighter SN is expected, particularly at the higher redshifts. Correction for bias was a particularly important effect in the analysis of Campbell et al. (2013) and Betoule et al. (2014), who used photometrically identified SN in addition to the spectroscopically confirmed sample. Figure 18 shows the bias expected from a simulation of the SDSS SN survey for two sample detection thresholds: requiring at least one light curve point to be observed in each of 3 filters above background by 5σ (SNRMAX3) and 10σ. The expected bias for a 5σ threshold, which is typical for SDSS-II, is small but still significant for a precise determination of cosmological parameters. Requiring a higher signal to noise ratio means that only brighter SN are detected, producing a bias in the average recovered distance modulus that increases with higher detection threshhold and increases with redshift as the apparent magnitudes increase. These two different bias corrections illustrate that the correction is important and that it depends on the selection criteria for each particular analysis. The SN detection efficiency is discussed in more detail elsewhere (Dilday et al. 2010b).

Figure 18. Bias in distance modulus as a function of redshift for the SDSS spectroscopic sample for two different example selection criteria.
Download figure:
Standard image High-resolution imageWe present a brief cosmological analysis of our full three-year spectroscopically confirmed SN Ia sample in Table 3. Requiring the SALT2 fit parameters in the range of normal SN Ia (−0.3 < c < 0.5 and −2.0 < x1 < 2.0) removes 3 and 32 SN Ia respectively, resulting in a sample of 415 SN Ia. Assuming a ΛCDM cosmology, we simultaneously fit ΩM and ΩΛ using the sncosmo_mcmc module within SNANA, and show their joint constraints in Figure 19. In this analysis, we have corrected for the expected selection biases (including Malmquist bias) using the 5σ threshhold curve (Figure 18), and have marginalised over H0 and the peak absolute magnitude of SN Ia, but only show statistical errors in Figure 19. Acceleration ( ) is detected at a confidence of 3.1σ. If we further assume a flat geometry, then we determine ΩM = 0.315 ± 0.093 and ΩΛ > 0 is required at 5.7σ confidence (statistical error only). In Figure 20, we show the residuals of the distance moduli with respect to this best fit cosmology, including varying ΩM by ±2σ from this best fit. Overall, our cosmological constraints are not as competitive as higher redshift samples of SN Ia because of the limited redshift range of our SDSS-II SN sample. Therefore, we refer the reader to Betoule et al. (2014) for a more extensive analysis of the full SDSS-II spectroscopically confirmed SN sample combined with other SN data sets (low redshift samples, SNLS, HST) and other cosmological measurements.
) is detected at a confidence of 3.1σ. If we further assume a flat geometry, then we determine ΩM = 0.315 ± 0.093 and ΩΛ > 0 is required at 5.7σ confidence (statistical error only). In Figure 20, we show the residuals of the distance moduli with respect to this best fit cosmology, including varying ΩM by ±2σ from this best fit. Overall, our cosmological constraints are not as competitive as higher redshift samples of SN Ia because of the limited redshift range of our SDSS-II SN sample. Therefore, we refer the reader to Betoule et al. (2014) for a more extensive analysis of the full SDSS-II spectroscopically confirmed SN sample combined with other SN data sets (low redshift samples, SNLS, HST) and other cosmological measurements.

Figure 19. The 68% and 95% contours (statistical errors only) for the joint fit to ΩM and ΩΛ for the full three-year SDSS-II spectroscopic sample. The dashed line represents  . Assuming a flat ΛCDM cosmology, we determine ΩM = 0.315 ± 0.093.
. Assuming a flat ΛCDM cosmology, we determine ΩM = 0.315 ± 0.093.
Download figure:
Standard image High-resolution image
Figure 20. Residuals of Hubble diagram for the full three-year SDSS-II spectroscopic sample relative to a best-fit cosmology assuming a flat ΛCDM cosmology with ΩM = 0.315. Reference lines showing the expected trend for ΩM two standard deviations higher and lower are also shown.
Download figure:
Standard image High-resolution image8. Host Galaxies
A wealth of data on the SN host galaxies is available from the SDSS Data Release 8 (DR8; Aihara et al. 2011). In Section 8.1 we describe the host-galaxy identification method used in this paper, which we suggest for future analyses. In Section 8.2 we describe the host-galaxy properties computed from SDSS data and presented in Table 1, and explain differences with values reported in previous analyses (Lampeitl et al. 2010b; Gupta et al. 2011; Smith et al. 2012).
8.1. Host Galaxy Identification
We use a more sophisticated methodology for selecting the correct SN host galaxy than trivially selecting the nearest galaxy with the smallest angular separation to the supernova. We instead use a technique that accounts for the probability based on the local surface brightness similar to that used in Sullivan et al. (2006).
We begin by searching DR8 for primary objects within a 30'' radius of each SN candidate position and consider all the objects as possible host galaxy candidates. We characterize each host galaxy by an elliptical shape. We chose the elliptical approximation, because the model-independent isophotal parameters were determined to be less reliable48 and were therefore not included in DR8. The shape of the ellipse was determined from second moments of the distribution of light in the r-band. The second moments are given in DR8 in the form of the Stokes parameters Q and U, from which one can compute the ellipticity and orientation of the ellipse. The major axis of the ellipse is set equal to the Petrosian half-light radius (SDSS parameter PetroR50) in the r-band; this radius encompasses 50% of the observed galaxy light. We found this parameter to be a more robust representation of the galaxy size than the deVRad and expRad profile fit radii, which too often had values that indicated a failure of the profile fit.
For each potential host galaxy, we calculate the elliptical light radius in the direction of the SN and call this the directional light radius (DLR). Next, we compute the ratio of the SN-host separation to the DLR and denote this normalized distance as dDLR. We then order the nearby host galaxy candidates by increasing dDLR and designate the first-ranked object as the host galaxy. For particular objects where this fails (the mechanism for determining this is described later), due to values of Q, U or PetroR50 that are missing or poorly measured, we select the next nearest object in dDLR as the host. In addition, we impose a cut on the maximum allowed dDLR for a nearby object to be a host. This cut is chosen to maximize the fraction of correct host matches while minimizing the fraction of incorrect ones as explained below. If there is no host galaxy candidate meeting these criteria, we consider the candidate to be hostless.
Determining an appropriate dDLR cutoff requires that we first estimate the efficiency of our matching algorithm. We estimate our efficiency by selecting a sample of positively identified host galaxies based on the agreement between the SN redshift and the redshift of the host galaxy from SDSS DR8 spectra. We select host galaxies from our sample of several hundred spectroscopically confirmed SN of all types via visual inspection of images. We then consider the 172 host galaxies that have redshifts in DR8. The distribution of differences in the SN redshift and host galaxy redshift for this sample is shown in Figure 21. The prominent peak at zero and lack of extreme outliers is proof that these SN are correctly matched with the host galaxy. The small offset between the host galaxy redshift and the redshift obtained from the SN spectrum was discussed in Section 6. The offset and the non-Gaussian tails of the distribution are probably due to the fact that we use a single normal Ia spectrum template to determine redshifts. Of the 172 host galaxies, 150 have a redshift agreement of ±0.01 or better, and we designate this sample of SN-host galaxy pairs as the "truth sample." We plot the distribution as a function of dDLR normalized to the data, as the dashed blue curve in Figure 22 (top panel).

Figure 21. Distribution of the difference in redshift (SN spectrum redshift minus host galaxy spectrum redshift) for the sample of spectroscopically confirmed SNe whose hosts have redshifts in DR8.
Download figure:
Standard image High-resolution image
Figure 22. Top: the distribution in dDLR is shown for the truth sample (dashed blue line), the contamination of false host galaxy matches (dotted red line) and the sum of the two distributions (solid blackline). The full sample is shown as the open circles with Poisson error bars and should be compared to the solid line. Bottom: the efficiency and purity of the host galaxy selection is shown as a function of dDLR and the matching criterion at dDLR = 4 indicated.
Download figure:
Standard image High-resolution imageThe efficiency for the identification of the full SDSS sample needs to include the SN which are hostless. Using the sample of spectroscopic SN Ia with z < 0.15, the redshift below which the SDSS-II SN survey is estimated to be 100% efficient (Dilday et al. 2010b) for spectroscopic measurement, we estimated the rate of hostless SN under the assumption that this low-z host sample is representative of the true SN Ia host distribution. We obtained SDSS ugriz model magnitudes and errors for the low-z host sample from the DR8 Catalog Archive Server (CAS)49 and used them and the measured redshifts to compute the best-fit model spectral energy distributions (SED) using the code kcorrect v4_2 (Blanton & Roweis 2007). The spectra were shifted to redshift bins of 0.05 up to z = 0.45, and we computed the expected apparent magnitudes of the hosts at those redshifts. We then weighted these magnitudes in the various z-bins by the redshift distribution of the entire spectroscopic SN Ia sample to mimic the observed r-band distribution for the whole redshift range. We identified those hosts that fell outside the DR8 r-band magnitude limit of 22.2 as hostless. From this analysis, we predict a hostless rate of 12% for the SDSS sample. Normalizing the truth distribution to 88% and taking the cumulative sum gives us an estimate of the efficiency of our matching method as a function of dDLR, which is shown as the blue curve in Figure 22 (bottom panel).
Unfortunately, we do not have spectroscopic redshifts for all candidates nor all potential host galaxies, so we can not rely on agreement between redshifts for the purity of the sample. In order to estimate the rate of misidentification, we chose a set of 10,000 random coordinates in the SN survey footprint and applied our matching algorithm using the DR8 catalog. We use these random points to determine the distribution in dDLR of SN candidates with unrelated galaxies. We realize that in reality, SN will occur in galaxies rather than randomly on the sky but a more sophisticated background estimate involving random galaxies and an assumed dDLR distribution is left for future work. The top panel of Figure 22 summarizes the situation: the distribution in dDLR is shown for the truth galaxies (dashed blue line), the expected distribution of background galaxies is shown as the dotted red line, and the solid black line is the sum of the two. The data sample is shown as the open circles. While the data is similar to expectations, it is notably more peaked at low values of dDLR than the truth sample would lead us to expect. The difference in the distributions is partly due to the fact that the truth sample (being constructed from the sample of spectroscopically confirmed SN) is biased against SN that occur near the core of their host galaxy where a spectroscopic confirmation is very difficult or impossible. We therefore expect that many more SN will reside at low dDLR than the truth sample predicts. In addition, there may be difficulty in determining accurate galaxy shape parameters for the fainter galaxies that comprise our full sample. Normalizing the host distribution for the random points and taking the cumulative sum yields the contamination rate as a function of dDLR. In the bottom panel we plot the estimated sample purity (1− contamination) as the red curve on the bottom panel of Figure 22.
We choose dDLR = 4 as our matching criterion in order to obtain high purity (97%) while still obtaining a good efficiency (80%). For that criterion we find that 16% of our SN candidates are hostless. We expect the observed rate of hostless SN to be higher than the predicted rate because of the inefficiency of our dDLR < 4 selection, partly offset by candidates added by visual scanning and an estimated contamination of incorrect matches of 2% at dDLR = 4. While the measured rate of hostless galaxies agrees fairly well with expectations, we suspect that our efficiency is underestimated because of the difference in dDLR distributions between the truth sample and the full sample and also the corrections made by visual scanning, which are described below.
There are many ways in which a host galaxy can be misidentified. If the true host is not found (which can happen when it is too faint or near a bright star or satellite track), it will not be selected. Even having a matching SN redshift and host galaxy redshift does not guarantee a correct match in the presence of galaxy groups, clusters, or mergers. For nearby (z ≲ 0.05) candidates, the SN can be offset by more than 30'' from the center of the host galaxy or the SDSS galaxy reconstruction may erroneously detect multiple objects in a large, extended galaxy. More distant candidates suffer from a higher density of plausible host galaxies, which also tend to be fainter and more point-like.
We attempted to mitigate these issues by examining a subset of all candidates and manually correcting any obvious mistakes made by the host-matching algorithm. In total, only 116 host galaxies were corrected and the details regarding their selection are given below. First we examined the images of several hundred of the lowest redshift candidates, since there are relatively few of them and they can exhibit some of the issues with host matching listed in the previous paragraph. In addition, of the 3000 host galaxies targeted by BOSS (Campbell et al. 2013; Olmstead et al. 2014) we found that for ≈350 candidates either the DR8 host was not found or the host coordinates differed from the BOSS target coordinates by more than 15. We visually inspected these ≈350 cases as well. Based on the inspection of the images from the lowest redshift candidates and the discrepant BOSS targets, the dDLR algorithm choice was changed for 116 host galaxies. The majority of these (69) had no host identified because of our selection criterion of dDLR < 4, but 4 had no host identified because of highly inaccurate galaxy shape parameters that gave incorrect estimates for dDLR. However, we did not assign a host based on visual inspection if there was no corresponding object in the DR8 catalog. We found 36 cases where the host selected by choosing the smallest dDLR disagreed with the visual scanning result. Most of these were caused by improperly deblended galaxies or regions where there were multiple candidates and visual pattern recognition proved superior; poor estimate of the galaxy size parameters was likely a factor in these corrections. There are seven candidates that were changed to be hostless because the dDLR < 4 candidate was a foreground star, a spurious source, or a host galaxy with an incompatible spectroscopically measured redshift.
8.2. Host Galaxy Properties
Much can be learned about SN through the properties of their host galaxies. We can derive several such properties by fitting host galaxy photometry to galaxy SED models. We begin by retrieving the SDSS ugriz model magnitudes (which yield the most accurate galaxy colors) and their errors from DR8 for the SN host galaxy sample. For all SN host galaxies with a spectroscopic redshift from either the host or the SN we use the redshifts, host magnitudes, and magnitude errors in conjunction with stellar population synthesis (SPS) codes to estimate physical properties of our hosts such as stellar mass, star formation rate, and average age. In this work, we obtain these properties using two different methods Gupta et al. (2011) and Smith et al. (2012), respectively. The galaxy properties described in this section provide supplementary data for those previously published papers. Researchers interested in using the SDSS data may wish to consider newer, more sophisticated models. Gupta et al. (2011) utilized SED models from the code Flexible Stellar Population Synthesis (FSPS; Conroy et al. 2009; Conroy & Gunn 2010) while Smith et al. (2012) utilized SED models from the code PÉGASE.2 (Fioc & Rocca-Volmerange 1997; Le Borgne et al. 2004). The current results, however, are not identical to the previously published results in that SDSS DR8 photometry, reported as asinh magnitudes (Lupton et al. 1999; Aihara et al. 2011), is now used while magnitudes from the SDSS co-add catalog (Annis et al. 2014) were used previously, and Gupta et al. (2011) augmented SDSS photometry with UV and NIR data. While the co-add catalog is certainly deeper, it is more prone to problems like artifacts or galactic substructures being detected as objects. The previous works cited above used relatively small SN samples and identified host galaxies by visual inspection, while in this paper we must rely on our automated algorithm which would fail on such problematic cases in the co-add catalogs.
In Table 12, we display the host properties calculated using FSPS for a few SN candidates. We have used only the SDSS photometric data for this analysis as did Smith et al. (2012), primarily because we have SDSS host galaxy photometric data for almost the full sample of SN Ia. Table 1 contains the full sample and also calculations using PÉGASE.2 of the analogous quantities using the same photometric data. The galaxy stellar mass (log(M), where M is expressed in units of M⊙) is shown in Table 12 with its uncertainty while the same information is presented as a range ( ) and
) and  ) in Table 1). All the calculated parameters are presented in the same way: Table 12 shows the uncertainties while Table 1 gives the range. Table 12 also shows the logarithm of the specific star formation rate
) in Table 1). All the calculated parameters are presented in the same way: Table 12 shows the uncertainties while Table 1 gives the range. Table 12 also shows the logarithm of the specific star formation rate  ), where sSFR is the mass of stars formed in M⊙ per year per galaxy stellar mass) averaged over the most recent 250 Myr. The mass-weighted average age of the galaxy is also given in units of Gyr. We give analogous quantities for PÉGASE.2 in Table 1 except that we give the logarithm of the star formation rate (i.e., not normalized to the galaxy stellar mass).
), where sSFR is the mass of stars formed in M⊙ per year per galaxy stellar mass) averaged over the most recent 250 Myr. The mass-weighted average age of the galaxy is also given in units of Gyr. We give analogous quantities for PÉGASE.2 in Table 1 except that we give the logarithm of the star formation rate (i.e., not normalized to the galaxy stellar mass).
Table 12. Derived Host Galaxy Parameters from FSPS and PÉGASE.2a
| FSPS | PÉGASE.2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| CID | objIDHost |
 b
b
|
log(sSFR)b | log(age)b |
 c
c
|
 d
d
|
log(SFR)d | log(age)d | χ2e |
| 679 | 1237656238472888902 |

|

|

|
0.33 |

|

|
9.0 | 5.03 |
| 682 | 1237678617405227407 |

|

|

|
0.13 |

|

|
3.5 | 99.90 |
| 688 | 1237656906347708594 |

|

|

|
0.20 |

|

|
3.0 | 51.05 |
| 691 | 1237663542608986381 |

|

|

|
0.06 |

|

|
2.0 | 20.44 |
| 694 | 1237663542609183155 |

|

|

|
0.19 |

|

|
3.0 | 136.10 |
| 695 | 1237656906351968456 |

|

|

|
0.17 |

|

|
4.0 | 839.30 |
| 697 | 1237663542611280181 |

|

|

|
1.61 |

|

|
1.8 | 18.40 |
| 700 | 1237663542611542434 |

|

|

|
5.60 |

|

|
1.8 | 33.07 |
| 701 | 1237663544221761583 |

|

|

|
0.02 |

|

|
3.5 | 40.46 |
| 702 | 1237663542612001229 |

|

|

|
8.65 |

|

|
7.0 | 65.39 |
| 703 | 1237663544222483004 |

|

|

|
0.15 |

|

|
1.8 | 0.68 |
| 708 | 1237663544224186552 |

|

|

|
37.19 |

|

|
7.0 | 454.80 |
| 710 | 1237663544224645704 |

|

|

|
4.51 |

|

|
6.0 | 11.01 |
| 717 | 1237663462608535732 |

|

|

|
0.08 |

|

|
4.5 | 20.42 |
| 719 | 1237663462608797948 |

|

|

|
7.20 |

|

|
2.0 | 60.31 |
| ⋯ | |||||||||
Notes.
aThis table is a portion of the full SN catalog, which is published in its entirety as Table 1 in the electronic edition. Selected columns relating to host galaxy properties are shown here for guidance regarding the form and content of these columns. bIn the electronic edition log(M) is called logMassFSPS and the upper limit is logMasshiFSPS and the lower limit is logMassloFSPS. is called logSSFRFSPS and the upper and lower limits are logSSFRhiFSPS and logSSFRloFSPS, respectively, and age is called ageFSPS with upper and lower limits agehiFSPS and ageloFSPS.
cThe reduced χ2 value of the fit. This column is called minredchi2FSPS in the electronic edition.
dIn the electronic edition log(M) is called logMassPEGASE and the upper limit is logMasshiPEGASE and the lower limit is logMassloPEGASE.
is called logSSFRFSPS and the upper and lower limits are logSSFRhiFSPS and logSSFRloFSPS, respectively, and age is called ageFSPS with upper and lower limits agehiFSPS and ageloFSPS.
cThe reduced χ2 value of the fit. This column is called minredchi2FSPS in the electronic edition.
dIn the electronic edition log(M) is called logMassPEGASE and the upper limit is logMasshiPEGASE and the lower limit is logMassloPEGASE.  is called logSFRPEGASE and the upper and lower limits are logSFRhiPEGASE and logSFRloPEGASE, respectively, and age is called agePEGASE.
eThe χ2 value of the fit. This column is called minchi2PEGASE in the electronic edition.
is called logSFRPEGASE and the upper and lower limits are logSFRhiPEGASE and logSFRloPEGASE, respectively, and age is called agePEGASE.
eThe χ2 value of the fit. This column is called minchi2PEGASE in the electronic edition.
Only a portion of this table is shown here to demonstrate its form and content. A machine-readable version of the full table is available.
Download table as: DataTypeset image
Figure 23 shows the distribution of galaxies as a function of logarithm of galaxy stellar mass versus the logarithm of star formation rate for PÉGASE.2 (top) and FSPS (bottom). The two distributions are similar overall but there are significant differences as well. In the analysis of Smith et al. (2012), galaxies are split into groups based on their sSFR: highly star-forming galaxies have  , moderately star-forming galaxies have
, moderately star-forming galaxies have  , and passive galaxies have
, and passive galaxies have  . Galaxies classified as passive by PÉGASE.2 were assigned random
. Galaxies classified as passive by PÉGASE.2 were assigned random  values between −4 and −3 for plotting purposes. Additionally, as noted in Smith et al. (2012), a population of galaxies with
values between −4 and −3 for plotting purposes. Additionally, as noted in Smith et al. (2012), a population of galaxies with  is present; these galaxies lie on a boundary of the PÉGASE.2 templates between star-forming and completely passive galaxies. The FSPS calculations do not provide such a clear distinction between passive and star-forming, so we somewhat arbitrarily define passive galaxies as those with
is present; these galaxies lie on a boundary of the PÉGASE.2 templates between star-forming and completely passive galaxies. The FSPS calculations do not provide such a clear distinction between passive and star-forming, so we somewhat arbitrarily define passive galaxies as those with  . Childress et al. (2013) remarked that SFR values derived from optical photometry are biased especially for low-SFR galaxies, but we have not corrected for that bias in our data release. For both analyses we see that, with a few exceptions, the most massive galaxies are classified as passive compared to the less massive galaxies which are classified as star-forming.
. Childress et al. (2013) remarked that SFR values derived from optical photometry are biased especially for low-SFR galaxies, but we have not corrected for that bias in our data release. For both analyses we see that, with a few exceptions, the most massive galaxies are classified as passive compared to the less massive galaxies which are classified as star-forming.

Figure 23. Distribution stellar mass and star formation rate for the SN candidate host galaxies with a spectroscopic redshift for the PÉGASE.2 analysis (Smith et al. 2012, top panel) and the FSPS analysis (Gupta et al. 2011, bottom panel). Lines of constant specific star formation rate separate the regions of high and moderate star formation (top panel) and the separation between star-forming and passive galaxies is shown with dashed lines in each panel. For PÉGASE.2, galaxies with a  are displayed with an artificial
are displayed with an artificial  , which is number randomly chosen between −4 and −3.
, which is number randomly chosen between −4 and −3.
Download figure:
Standard image High-resolution imageFigure 24 (top) compares the stellar mass calculated with PÉGASE.2 and FSPS. Galaxies are split according to the sSFR scheme described above, with red circles indicating passive, green triangles indicating moderately star-forming, and blue diamonds indicating highly star-forming. The mass estimates show generally good agreement, with the stellar mass estimated from FSPS being marginally higher than that estimated from the PÉGASE.2 templates. In addition, the FSPS mass estimates are relatively larger than PÉGASE.2 for the passive galaxies and relatively smaller for the moderately star-forming galaxies. Figure 24 (bottom) compares the SFR estimated by both methods. We find that 68% (24%) of galaxies are found to be star-forming (passive), respectively, by both analyses, and 6% are found to be passive by PÉGASE.2 and star-forming by FSPS and 2% vice versa. In general, the SFR show good agreement between the two methods, with a larger scatter than that observed for the mass estimates. For galaxies classified as star-forming, the SFR estimated by PÉGASE.2 are systematically higher than those estimated by FSPS. The differences in derived galaxy properties are likely due to the differences in the available SED templates and how they are parametrized in FSPS compared with PÉGASE.2.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 24. Comparison between PÉGASE.2 and FSPS galaxy stellar masses and SFRs for the the SN candidate host galaxies with a spectroscopic redshift. As in Figure 23 for PÉGASE.2, galaxies with  are displayed with an artificial
are displayed with an artificial  value randomly chosen between −4 and −3.
value randomly chosen between −4 and −3.
Download figure:
Standard image High-resolution image{kind=link}
9. Summary
This paper represents the final Data Release of the SDSS-II SN Survey of 10,258 candidates. A new method of classification based on the light curve data has been presented and applied to the candidates. Reference light curve fits are provided for SALT2 and MLCS2k2. A new method to associate SN observations with their host galaxies was presented, including a quantitative estimate of efficiency and false-positive association. Host galaxy properties were computed from the photometric data using two computer programs: PÉGASE.2 and FSPS. A table listing the 1360 spectra that were obtained in conjunction with the SDSS SN search was presented. A web page reference to the complete light curve data and reduced spectra was given. A complete set of photometric data for all the SDSS SN candidates has been presented and is released on the SDSS SN data release web page. All the spectra taken in conjunction with the SDSS-II SN survey are also released. In addition, we have provided light curve fits and host galaxy identifications and estimated host galaxy parameters.
Funding for the SDSS and SDSS-II has been provided by the Alfred P. Sloan Foundation, the Participating Institutions, the National Science Foundation, the U.S. Department of Energy, the National Aeronautics and Space Administration, the Japanese Monbukagakusho, the Max Planck Society, and the Higher Education Funding Council for England. The SDSS Web Site is http://www.sdss.org/.
The SDSS is managed by the Astrophysical Research Consortium for the Participating Institutions. The Participating Institutions are the American Museum of Natural History, Astrophysical Institute Potsdam, University of Basel, Cambridge University, Case Western Reserve University, University of Chicago, Drexel University, Fermilab, the Institute for Advanced Study, the Japan Participation Group, Johns Hopkins University, the Joint Institute for Nuclear Astrophysics, the Kavli Institute for Particle Astrophysics and Cosmology, the Korean Scientist Group, the Chinese Academy of Sciences (LAMOST), Los Alamos National Laboratory, the Max-Planck-Institute for Astronomy (MPIA), the Max-Planck-Institute for Astrophysics (MPA), New Mexico State University, Ohio State University, University of Pittsburgh, University of Portsmouth, Princeton University, the United States Naval Observatory, and the University of Washington.
The Hobby-Eberly Telescope (HET) is a joint project of the University of Texas at Austin, the Pennsylvania State University, Stanford University, Ludwig-Maximillians-Universität München, and Georg-August-Universität Göttingen. The HET is named in honor of its principal benefactors, William P. Hobby and Robert E. Eberly. The Marcario Low-Resolution Spectrograph is named for Mike Marcario of High Lonesome Optics, who fabricated several optics for the instrument but died before its completion; it is a joint project of the Hobby-Eberly Telescope partnership and the Instituto de Astronomía de la Universidad Nacional Autónoma de México. The Apache Point Observatory 3.5 m telescope is owned and operated by the Astrophysical Research Consortium. We thank the observatory director, Suzanne Hawley, and site manager, Bruce Gillespie, for their support of this project. The Subaru Telescope is operated by the National Astronomical Observatory of Japan. The William Herschel Telescope is operated by the Isaac Newton Group, and the Nordic Optical Telescope is operated jointly by Denmark, Finland, Iceland, Norway, and Sweden, both on the island of La Palma in the Spanish Observatorio del Roque de los Muchachos of the Instituto de Astrofisica de Canarias. Observations at the ESO New Technology Telescope at La Silla Observatory were made under programme IDs 77.A-0437, 78.A-0325, and 79.A-0715. Kitt Peak National Observatory, National Optical Astronomy Observatory, is operated by the Association of Universities for Research in Astronomy, Inc. (AURA) under cooperative agreement with the National Science Foundation. The WIYN Observatory is a joint facility of the University of Wisconsin-Madison, Indiana University, Yale University, and the National Optical Astronomy Observatories. The W.M. Keck Observatory is operated as a scientific partnership among the California Institute of Technology, the University of California, and the National Aeronautics and Space Administration. The Observatory was made possible by the generous financial support of the W.M. Keck Foundation. The South African Large Telescope of the South African Astronomical Observatory is operated by a partnership between the National Research Foundation of South Africa, Nicolaus Copernicus Astronomical Center of the Polish Academy of Sciences, the Hobby-Eberly Telescope Board, Rutgers University, Georg-August-Universität Göttingen, University of Wisconsin-Madison, University of Canterbury, University of North Carolina-Chapel Hill, Dartmough College, Carnegie Mellon University, and the United Kingdom SALT consortium. The Telescopio Nazionale Galileo (TNG) is operated by the Fundación Galileo Galilei of the Italian INAF (Istituo Nazionale di Astrofisica) on the island of La Palma in the Spanish Observatorio del Roque de los Muchachos of the Instituto de Astrofísica de Canarias.
The Penn group was supported by DOE grant DE-FOA-0001358 and NSF grant AST-1517742. This work was completed in part with resources provided by the University of Chicago Research Computing Center. A.V. Filippenko has received generous financial assistance from the Christopher R. Redlich Fund, the TABASGO Foundation, and NSF grant AST-1211916. Supernova research at Rutgers University is supported in part by NSF CAREER award AST-0847157 to S.W. Jha. G. Leloudas is supported by the Swedish Research Council through grant No. 623-2011-7117. M.D. Stritzinger gratefully acknowledges generous support provided by the Danish Agency for Science and Technology and Innovation realized through a Sapere Aude Level 2 grant.
Footnotes
- 45
- 46
- 47
The meaning of the photometric flags is detailed in Holtzman et al. (2008).
- 48
- 49