






























![classmethod.jp
spark-env.shの生成とライブラリの追加
MASTER=$(grep -i "job.tracker<" /home/hadoop/conf/mapred-site.xml | grep -o '[0-9]{1,3}.[0-9]{1,3}
.[0-9]{1,3}.[0-9]{1,3}')
SPACE=$(mount | grep mnt | awk '{print $3"/spark/"}' | xargs | sed 's/ /,/g')
PUB_HOSTNAME=$(GET http://169.254.169.254/latest/meta-data/public-hostname)
!
touch /home/hadoop/spark/conf/spark-env.sh
echo "export SPARK_CLASSPATH=/home/hadoop/spark/jars/*">> /home/hadoop/spark/conf/spark-env.sh
echo "export SPARK_MASTER_IP=$MASTER">> /home/hadoop/spark/conf/spark-env.sh
echo "export MASTER=spark://$MASTER:7077" >> /home/hadoop/spark/conf/spark-env.sh
echo "export SPARK_LIBRARY_PATH=/home/hadoop/native/Linux-amd64-64" >> /home/hadoop/spark/conf/spark-
env.sh
echo "export SPARK_JAVA_OPTS="-Dspark.local.dir=$SPACE"" >> /home/hadoop/spark/conf/spark-env.sh
echo "export SPARK_WORKER_DIR=/mnt/var/log/hadoop/userlogs/" >> /home/hadoop/spark/conf/spark-env.sh
cp /home/hadoop/spark/conf/metrics.properties.aws /home/hadoop/spark/conf/metrics.properties
!
cp /home/hadoop/lib/gson-* /home/hadoop/spark/jars/
##cp /home/hadoop/lib/aws-java-sdk-* /home/hadoop/spark/jars/
cp /home/hadoop/conf/core-site.xml /home/hadoop/spark/conf/
cp /home/hadoop/lib/EmrMetrics*.jar /home/hadoop/spark/jars/
cp /home/hadoop/hive/lib/hive-builtins-0.9.0-shark-0.8.1.jar /home/hadoop/spark/jars/
cp /home/hadoop/hive/lib/hive-exec-0.9.0-shark-0.8.1.jar /home/hadoop/spark/jars/
cp /home/hadoop/shark/target/scala-2.9.3/shark_2.9.3-0.8.1.jar /home/hadoop/spark/jars/
31](https://image.slidesharecdn.com/runsparkonemr-140628011134-phpapp02/85/Run-Spark-on-EMR-31-320.jpg)
![classmethod.jp
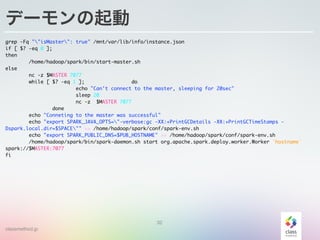
デーモンの起動
grep -Fq ""isMaster": true" /mnt/var/lib/info/instance.json
if [ $? -eq 0 ];
then
/home/hadoop/spark/bin/start-master.sh
else
nc -z $MASTER 7077
while [ $? -eq 1 ]; do
echo "Can't connect to the master, sleeping for 20sec"
sleep 20
nc -z $MASTER 7077
done
echo "Conneting to the master was successful"
echo "export SPARK_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -
Dspark.local.dir=$SPACE"" >> /home/hadoop/spark/conf/spark-env.sh
echo "export SPARK_PUBLIC_DNS=$PUB_HOSTNAME" >> /home/hadoop/spark/conf/spark-env.sh
/home/hadoop/spark/bin/spark-daemon.sh start org.apache.spark.deploy.worker.Worker `hostname`
spark://$MASTER:7077
fi
33](https://image.slidesharecdn.com/runsparkonemr-140628011134-phpapp02/85/Run-Spark-on-EMR-33-320.jpg)


















Run Spark on EMRってどんな仕組みになってるの?
- 1. classmethod.jp Run Spark on EMRって どんな仕組みになってるの? AWS勉強会 in 北北海道札幌! Developers.IO Meetup 05 1 2014/06/28 能登 諭
- 2. classmethod.jp 2 注意!!! ! このスライドの内容は現在は一部適切ではない内容になっています。! ! このスライドの元ネタであるAWSの記事が2014-10-22にアップデートされま した。! https://aws.amazon.com/articles/Elastic-MapReduce/4926593393724923! ! このアップデートでYARNに対応したSparkのBootstrap ActionがAWSより 提供されるようになりました。! http://blogs.aws.amazon.com/bigdata/post/Tx15AY5C50K70RV/Installing- Apache-Spark-on-an-Amazon-EMR-Cluster! ! このスライドはアップデート前のSpark 0.8.1 on Hadoop 1.0.3 (AMI 2.x)に ついて書かれたものです。Bootstrap Actionの概要を知るにはいいですが、 現状はAWSからYARNに対応したBootstrap Actionが提供されたという部分 が異なりますのでご注意下さいm(_ _)m!
- 3. classmethod.jp 自己紹介 • 氏名:能登 諭(のと さとし)! • Twitter:@n3104! • 得意分野:Hadoop! • 好きなAWSサービス:EMR 3
- 6. classmethod.jp EMRとは • http://aws.amazon.com/jp/elasticmapreduce/! • 正式名称はAmazon Elastic MapReduce。! • AWSが提供するHadoopのディストリビューショ ン。! • オンプレとの一番の違いは保守が不要な点。! • 基本的にS3に入出力ファイルを置くことになるため! • HDFSの障害を考慮しなくてよくなる。! • 容量制限を気にする必要がなくなる。 6
- 7. classmethod.jp そもそもHadoopとは • http://hadoop.apache.org/! • HDFS(分散ファイルシステム)とMapReduce(分 散処理基盤)をコアとするミドルウェア群。! • 中心はHDFS(分散ファイルシステム)。これがある おかけでMapReduceで効率的に分散処理ができる。! • 最近はYARN(次世代MapReduce)が出てきたの で、MapReduce以外の処理モデルもサポートし、よ り汎用的な分散処理基盤という位置づけに。 7
- 14. classmethod.jp 14 はい。EMR の一部のお客様は、処理 エンジンとして Spark および Shark (インメモリ MapReduce およびデー タウェアハウス)を使用できます。使 用方法については、この記事を参照し てください。
- 15. classmethod.jp 15 Run Spark and Shark on Amazon Elastic MapReduce! http://aws.amazon.com/articles/ Elastic-MapReduce/ 4926593393724923
- 18. classmethod.jp 18 elastic-mapreduce --create --alive -- name "Spark/Shark Cluster" -- bootstrap-action s3:// elasticmapreduce/samples/spark/ 0.8.1/install-spark-shark.sh -- bootstrap-name "Spark/Shark" -- instance-type m1.xlarge --instance- count 3
- 20. classmethod.jp Sparkとは • https://spark.apache.org/! • Hadoopと同じ分散処理基盤。! • 繰り返し処理とインメモリ処理をサポートするDAG(有向非循環グラフ) 実行エンジン。! • DAGはDriverプログラムから生成されるのでDAGを直接記述するわけで はない。! • RDDs(Resilient Distributed Datasets)というモデルで、DAGの終端か ら先頭のデータソースに向かってデータを生成していくのが特徴。! • Hadoopと比べて繰り返し処理が得意で、100倍ぐらい早く処理できる場合 がある。! • http://dev.classmethod.jp/etc/hadoop-reading-16/ を見れば概ね分かるはずw 20
- 21. classmethod.jp Driverのプログラム val file = sc.textFile("s3://bigdatademo/sample/wiki/")! ! val reducedList = file.map(l => l.split(" "))! ! .map(l => (l(1), l(2).toInt)).reduceByKey(_+_, 3)! ! reducedList.cache! ! val sortedList = reducedList! ! .map(x => (x._2, x._1)).sortByKey(false).take(50) 21
- 22. classmethod.jp Sharkとは • http://shark.cs.berkeley.edu/! • 分散SQLエンジン。! • HiveをMapReduceではなくSparkで実行でき るようにしたもの。! • なのでクエリによってはSpark同様、Hiveより も100倍ぐらい早く処理できる場合がある。 22
- 25. classmethod.jp 25 Run Spark on EMRって! どんな仕組みになってるの?
- 29. classmethod.jp s3://elasticmapreduce/samples/spark/0.8.1/install-spark-shark.sh • SparkとSharkをEMRクラスタにインストールするためのシェル! • 最初に必要なソフトウェアをダウンロード&展開! • 既にセットアップ済みのHadoopの設定ファイルを元にspark- env.shを生成! • Sparkで利用するライブラリをコピー! • Sharkのセットアップ! • Sparkのデーモンを起動! • マスターの場合はstart-master.shを実行! • スレーブの場合はspark-daemon.shを実行 29
- 30. classmethod.jp ソフトウェアのダウンロード&展開 cd /home/hadoop/ ! ##Download Spark EMR wget http://bigdatademo.s3.amazonaws.com/0.8.1-dev1/spark-0.8.1-emr.tgz ##Download Shark wget https://github.com/amplab/shark/releases/download/v0.8.1/shark-0.8.1-bin-hadoop1.tgz ##Download Scala wget http://www.scala-lang.org/files/archive/scala-2.9.3.tgz ##DOwnload hive wget https://github.com/amplab/shark/releases/download/v0.8.1/hive-0.9.0-bin.tgz ! tar -xvzf scala-2.9.3.tgz tar -xvzf spark-0.8.1-emr.tgz tar -xvzf shark-0.8.1-bin-hadoop1.tgz tar -xvzf hive-0.9.0-bin.tgz ! ln -sf spark-0.8.1-emr spark ln -sf /home/hadoop/shark-0.8.1-bin-hadoop1/ /home/hadoop/shark ln -sf /home/hadoop/hive-0.9.0-bin /home/hadoop/hive ln -sf /home/hadoop/scala-2.9.3 /home/hadoop/scala 30
- 31. classmethod.jp spark-env.shの生成とライブラリの追加 MASTER=$(grep -i "job.tracker<" /home/hadoop/conf/mapred-site.xml | grep -o '[0-9]{1,3}.[0-9]{1,3} .[0-9]{1,3}.[0-9]{1,3}') SPACE=$(mount | grep mnt | awk '{print $3"/spark/"}' | xargs | sed 's/ /,/g') PUB_HOSTNAME=$(GET http://169.254.169.254/latest/meta-data/public-hostname) ! touch /home/hadoop/spark/conf/spark-env.sh echo "export SPARK_CLASSPATH=/home/hadoop/spark/jars/*">> /home/hadoop/spark/conf/spark-env.sh echo "export SPARK_MASTER_IP=$MASTER">> /home/hadoop/spark/conf/spark-env.sh echo "export MASTER=spark://$MASTER:7077" >> /home/hadoop/spark/conf/spark-env.sh echo "export SPARK_LIBRARY_PATH=/home/hadoop/native/Linux-amd64-64" >> /home/hadoop/spark/conf/spark- env.sh echo "export SPARK_JAVA_OPTS="-Dspark.local.dir=$SPACE"" >> /home/hadoop/spark/conf/spark-env.sh echo "export SPARK_WORKER_DIR=/mnt/var/log/hadoop/userlogs/" >> /home/hadoop/spark/conf/spark-env.sh cp /home/hadoop/spark/conf/metrics.properties.aws /home/hadoop/spark/conf/metrics.properties ! cp /home/hadoop/lib/gson-* /home/hadoop/spark/jars/ ##cp /home/hadoop/lib/aws-java-sdk-* /home/hadoop/spark/jars/ cp /home/hadoop/conf/core-site.xml /home/hadoop/spark/conf/ cp /home/hadoop/lib/EmrMetrics*.jar /home/hadoop/spark/jars/ cp /home/hadoop/hive/lib/hive-builtins-0.9.0-shark-0.8.1.jar /home/hadoop/spark/jars/ cp /home/hadoop/hive/lib/hive-exec-0.9.0-shark-0.8.1.jar /home/hadoop/spark/jars/ cp /home/hadoop/shark/target/scala-2.9.3/shark_2.9.3-0.8.1.jar /home/hadoop/spark/jars/ 31
- 32. classmethod.jp Shark関係のセットアップ touch /home/hadoop/shark/conf/shark-env.sh cp /home/hadoop/lib/gson-* /home/hadoop/shark/lib_managed/jars/ cp /home/hadoop/lib/aws-java-sdk-* /home/hadoop/shark/lib_managed/jars/ cp /home/hadoop/lib/EmrMetrics*.jar /home/hadoop/shark/lib_managed/jars/ cp /home/hadoop/hadoop-core.jar /home/hadoop/shark/lib_managed/jars/org.apache.hadoop/hadoop-core/ hadoop-core-1.0.4.jar cp /home/hadoop/conf/core-site.xml /home/hadoop/hive/conf/ ! echo "export HIVE_HOME=/home/hadoop/hive/" >> /home/hadoop/shark/conf/shark-env.sh echo "export SPARK_HOME=/home/hadoop/spark" >> /home/hadoop/shark/conf/shark-env.sh echo "source /home/hadoop/spark/conf/spark-env.sh">> /home/hadoop/shark/conf/shark-env.sh echo "export SCALA_HOME=/home/hadoop/scala" >> /home/hadoop/shark/conf/shark-env.sh ! cat > /home/hadoop/hive/conf/hive-site.xml << EOF <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property><name>mapred.job.tracker</name><value>yarn</value></property><property><name>fs.default.name</ name> <value>hdfs://$MASTER:9000</value></property> </configuration> EOF 32
- 33. classmethod.jp デーモンの起動 grep -Fq ""isMaster": true" /mnt/var/lib/info/instance.json if [ $? -eq 0 ]; then /home/hadoop/spark/bin/start-master.sh else nc -z $MASTER 7077 while [ $? -eq 1 ]; do echo "Can't connect to the master, sleeping for 20sec" sleep 20 nc -z $MASTER 7077 done echo "Conneting to the master was successful" echo "export SPARK_JAVA_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps - Dspark.local.dir=$SPACE"" >> /home/hadoop/spark/conf/spark-env.sh echo "export SPARK_PUBLIC_DNS=$PUB_HOSTNAME" >> /home/hadoop/spark/conf/spark-env.sh /home/hadoop/spark/bin/spark-daemon.sh start org.apache.spark.deploy.worker.Worker `hostname` spark://$MASTER:7077 fi 33