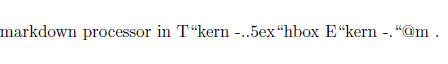この記事はTeX & LaTeX Advent Calendar 2017の3日めのために書きましたが、宣伝目的です。
TeX & LaTeX Advent Calendar 2017の重点テーマは「TeXでつくるアレ」とのことですが、偶然にも2017年、よく似たタイトルの『RubyでつくるRuby』(遠藤侑介著)という本が出ました。
プログラミング言語を学ぶときの例題としてプログラミング言語をつくる以上に格好のネタはない、という趣旨の本です。
プログラミング言語をつくるというと、なにやら難しく聞こえるかもしれませんが、『RubyでつくるRuby』では、わずか150ページのなかにそのエッセンスを凝縮しています。
本文の理解を助けるかわいらしいイラストもフルカラーでふんだんに用意されているので、はじめてプログラムを書いてみようかなという人でも、おそらく(願わくば)読み通せる内容です。
電子書籍はなく、古き良き紙の本のみですが、電子版がいいという人はAscii.jpでもとになった連載が読めるので、そちらをどうぞ!
プログラミング言語の処理系が扱うデータは「木」
『RubyでつくるRuby』では、プログラミング言語Rubyで書かれたプログラムを処理して実行するプログラミング言語を、プログラミング言語Rubyでつくります。
つまり、本書の読者が書くことになるプログラムが処理するのは、Rubyのプログラムです。
Rubyに限りませんが、多くのプログラミング言語では、プログラマーが書いたプログラムを実行する前に、そのプログラムをまず「木」と呼ばれる種類のデータへと変換します。
この「木」は、その名のとおり樹木のような姿をしていて、「枝がのびる節」と「葉」があります。
このへんは、文章で説明するよりも、絵で見るほうがはやいでしょう。
たとえば、次のようなRubyのプログラム(四則演算だけですが)がどんな木になるかというと……
(1 + 2) / 3 * 4 * (56 / 7 + 8 + 9)
こんな木になります。式で見るより、項どうしの演算の関係がわかりやすいですね。
本書の解説には「木」を扱う場面がたくさん出てくるので、説明文やコードに加えてこんな具合に木の絵をたくさん用意できれば、いま説明しているデータの姿がどんなようすなのか「ひとめ」でわかります。
なので、ぜひ木の絵はたくさん載せたい。
かといって、こういう木の絵をぜんぶイラストレーターさんに描いてもらうのもたいへんです。
描くほうだけでなく、間違ってないかチェックするほうもめんどくさい。
それなりの見た目で、なおかつ間違いなくプログラムの木を描くには、どうすればいいでしょうか?
そう、TeXを使えばいいのです。
実際、上に例として出した木もTeXで生成しています。
TeXで木を描く
というわけで、前置きが長くなりましたが、『RubyでつくるRuby』の木の絵をTeXでどう描いたかをちょっと紹介します。
書籍『RubyでつくるRuby』では、プログラムの木を、Rubyにおける配列表現からTeXで生成しました。
これなら手間もかからず、なにより作図にともなう間違いもありません。
tikz-qtreeパッケージの使い方
木は、プログラムに限らずいろいろな場面に出てくるデータ構造なので、関連するTeXパッケージがわりとたくさん出そろっています。
そのなかで『RubyでつくるRuby』の木を描くのに選んだのは、 tikz-qtree というTikZベースのパッケージです。
https://ctan.org/pkg/tikz-qtree
この tikz-qtree パッケージを選んだ理由のひとつは、上下逆向きの木構造を手軽に描けることです。
木構造を描くときは、根を上にする(つまり本物の樹木でいったら上下逆)ことが多いのですが、本書の場合にはイラストにある本物っぽい木の絵とシームレスに読み替えてもらいたいので、根を下にして木構造を描ける機能が重要だったのです。
tikz-qtree のミニマルな例を示します。これは 2 * 4 というRubyプログラムの「木」の例です。
\documentclass[tikz,convert={outext=.png}]{standalone}
\usepackage{tikz-qtree}
\begin{document}
\begin{tikzpicture}
\Tree [.*
[2
\node[draw]{4};
]]
\end{tikzpicture}
\end{document}
\Tree[ ] のなかに、木を描いてきます。
[ ] を入れ子にすると、その中に書いたものが子どもの要素になります。
要素としてスペース区切りで値を書き込めば、それが葉になります。
子を持つ要素には、値の前に「 . 」をつけます。
上の例では、根にあたる「 * 」に「 . 」が必要です。
さらに上の例では、TikZの \node 命令がそのまま使えることを示すために、「4」のほうだけ枠をつけてみました( \node 命令なので末尾に ; を忘れずに!)。
上記を tree.tex として保存し、以下のようにpdflatexで処理すれば……
$ pdflatex --shell-escape tree.tex
こんな絵が得られます。
この木の上下をさかさまにするには、 tikzpicture 環境に [grow'=up] というオプションをつけるだけです。
\documentclass[tikz,convert={outext=.png}]{standalone}
\usepackage{tikz-qtree}
\begin{document}
\begin{tikzpicture}[grow'=up]
\Tree [.*
[2
\node[draw]{4};
]]
\end{tikzpicture}
\end{document}
このままだと絵として味気ないので、色をぬったり、枠の形を変えたり、線の幅を調整したりするわけですが、そのへんはTikZの \node をごにょごにょいじるというつまらない話なので割愛します。
TikZのマニュアル(むかしは400ページくらいでしたが、いまでは1000ページ超)を片手にがんばってみてください。
TikZソースを木のソースから生成する
木の見た目を整えたら、毎回TikZを手描きするのはばかばかしいので、プログラムで生成するようにします。
『RubyでつくるRuby』で描きたいのはプログラムを表す木で、その木はRubyコードとしてはこんなふうな姿をしています。
本当は、 2 とか 4 が何ものであるかを表すために、もうちょっとメタ情報がついていますが、だいたいこんな感じです。
(そもそも、配列でプログラムの木を表すのはあくまでも『RubyでつくるRuby』の中に限定した話で、じっさいのRubyではまったくべつの表現方法です。)
これはどう見てもS式なので、カンマを削除してGaucheで直接読み込んで変換し、 tikz-qtree パッケージを使った木を描くTeXソースを吐くようにしましょう。
(use srfi-13)
(use text.tree)
(define (deco-b b)
#"\\node[text=white,inner sep=4pt,drop shadow,fill={rgb:blue,5;white,1;green,1},draw,rounded corners]{\\small ~b};")
(define (deco-l l)
#"\\node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\\mystrut\\smash{~l}};")
(define *before-tikz* "\
\n\\begin{tikzpicture}[grow'=up] \
\n \\tikzset{ \
\n every tree node/.style={font=\\ttfamily\\large}, \
\n edge from parent/.append style={very thick}} \
\n \\Tree ")
(define *end-tikz* "\n\\end{tikzpicture}\n\\clearpage\n")
(define *before-doc* "\
\n\\documentclass[tikz,border=10pt,convert={outext=.png}]{standalone} \
\n\\def\\mystrut{\\rule{0pt}{1.3ex}} \
\n\\usepackage{tikz} \
\n\\usepackage{tikz-qtree} \
\n\\usetikzlibrary{shapes.geometric,shadows}% \
\n\\begin{document}\n")
(define *end-doc* "\n\\end{document}\n")
(define (tikzqtree ts)
(list *before-tikz* (mkqtree ts) *end-tikz*))
(define (mkqtree ts)
(cond ((null? ts) "")
((pair? ts) (mkbranch
(car ts)
(map mkqtree (cdr ts))))
(else (mkleaf ts))))
(define (mkbranch b l)
(list "[." (deco-b (x->string b)) "\n " l "]"))
(define (mkleaf l)
(list (deco-l (x->string l)) " "))
(define (main args)
(call-with-input-file (cadr args)
(lambda (p)
(print
(tree->string
(list
*before-doc*
(map tikzqtree (port->sexp-list p))
*end-doc*))))))
カンマをプログラムで削除しないのは、カンマなしならS式としてそのままreadできるからです。この手のユーティリティはコーディングが簡単なほうに倒してガッっと書いてしまうのが肝要だと思います。
実行結果
最初に紹介した、わりと複雑なかっこうをしている次のようなRubyの計算式について、プログラムの木を描いてみましょう。
(1 + 2) / 3 * 4 * (56 / 7 + 8 + 9)
この計算式は、『RubyでつくるRuby』ではこんな感じの木(配列の配列)として表されます。
["*", ["*", ["/", ["+", 1, 2], 3], 4], ["+", ["+", ["/", 56, 7], 8], 9]]
この一行をファイルに保存して、カンマだけエディタで削除し、先ほどのGaucheスクリプトで読み込むと……
$ gosh mktree.scm temp.rb > temp.tex
こんな気持ちの悪いLaTeXのソースができます。
\documentclass[tikz,border=10pt,convert={outext=.png}]{standalone}
\def\mystrut{\rule{0pt}{1.3ex}}
\usepackage{tikz}
\usepackage{tikz-qtree}
\usetikzlibrary{shapes.geometric,shadows}%
\begin{document}
\begin{tikzpicture}[grow'=up]
\tikzset{
every tree node/.style={font=\ttfamily\large},
edge from parent/.append style={very thick}}
\Tree [.\node[text=white,inner sep=4pt,drop shadow,fill={rgb:blue,5;white,1;green,1},draw,rounded corners]{\small *};
[.\node[text=white,inner sep=4pt,drop shadow,fill={rgb:blue,5;white,1;green,1},draw,rounded corners]{\small *};
[.\node[text=white,inner sep=4pt,drop shadow,fill={rgb:blue,5;white,1;green,1},draw,rounded corners]{\small /};
[.\node[text=white,inner sep=4pt,drop shadow,fill={rgb:blue,5;white,1;green,1},draw,rounded corners]{\small +};
\node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\mystrut\smash{1}}; \node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\mystrut\smash{2}}; ]\node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\mystrut\smash{3}}; ]\node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\mystrut\smash{4}}; ][.\node[text=white,inner sep=4pt,drop shadow,fill={rgb:blue,5;white,1;green,1},draw,rounded corners]{\small +};
[.\node[text=white,inner sep=4pt,drop shadow,fill={rgb:blue,5;white,1;green,1},draw,rounded corners]{\small +};
[.\node[text=white,inner sep=4pt,drop shadow,fill={rgb:blue,5;white,1;green,1},draw,rounded corners]{\small /};
\node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\mystrut\smash{56}}; \node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\mystrut\smash{7}}; ]\node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\mystrut\smash{8}}; ]\node[text=white,inner sep=2pt,drop shadow,fill={rgb:green,6;white,1;black,4},draw,ellipse]{\mystrut\smash{9}}; ]]
\end{tikzpicture}
\clearpage
\end{document}
これをコンパイルすると……
$ pdflatex --shell-escape temp.tex
冒頭に掲載したような、こんなきれいなpngファイルが得られるというわけでした。
まとめ
『RubyでつくるRuby』を読むと、このような「木」がプログラムそのものだということがわかります。
このように生成された図だけでなく、hirekoke画伯描きおろしカラーイラストも豊富に掲載された『RubyでつくるRuby』をいますぐ買おう!
繰り返しになりますが、電子版はラムダノートでは出版していないものの、Ascii.jpでもとになった連載が読めます。ぜんぶ無料!