
Main objectives of Impresso2 as presentend in the workshop
The workshop began with a look back at the first Impresso project (2017-2020) by Maud Ehrmann on major challenges, achievements and Impresso’s modus operandi. The main challenges of Impresso 1 also remain in the second project: Cultural heritage data is stored in digital silos and maintained by separate institutions, there are large amounts of messy and noisy textual data encoded in various standards which requires significant transformation to effectively support visualisation and exploration to enable the conduct of historically meaningful scholarship based on data and interfaces. A short demo by Marten Düring gave an insight into the interplay of the different interface components and illustrated the intended usage of the Impresso app whilst also serving as a sneak preview of a gentle design update reserved for an upcoming release.
A recap of Impresso 2’s main research objectives and its overall ambition to become “the tool of reference for the exploration of interconnected media sources” across languages, time, and countries followed. For the realisation of this ambitious goal, Impresso can build on recent advances in NLP, digital humanities research practices and a shift in research objectives in media history. Still, a number of challenges remain on the level of system architecture, data representation and legal access to data.
Impresso’s NLP team presented the ongoing work to achieve one of the project’s biggest goals, to “develop mono- and multilingual NLP and image processing components that consolidate, process, enrich, index, link and connect historical sources and external knowledge bases.” This session began with a short report on efforts by University of Zurich to integrate BNL’s pipeline Nautilus for the re-OCRisation of Impresso data formats and continued with a report on preliminary mixed results obtained during post-correction of ASR using LLMs. Shifting to named entities, Maud Ehrmann and Emanuela Boros presented past and future HIPE evaluation campaigns for the detection of named entities in historical texts as well as efforts to improve named entity processing in Impresso2 together with earlier efforts to detect press agencies in historical newspaper text.
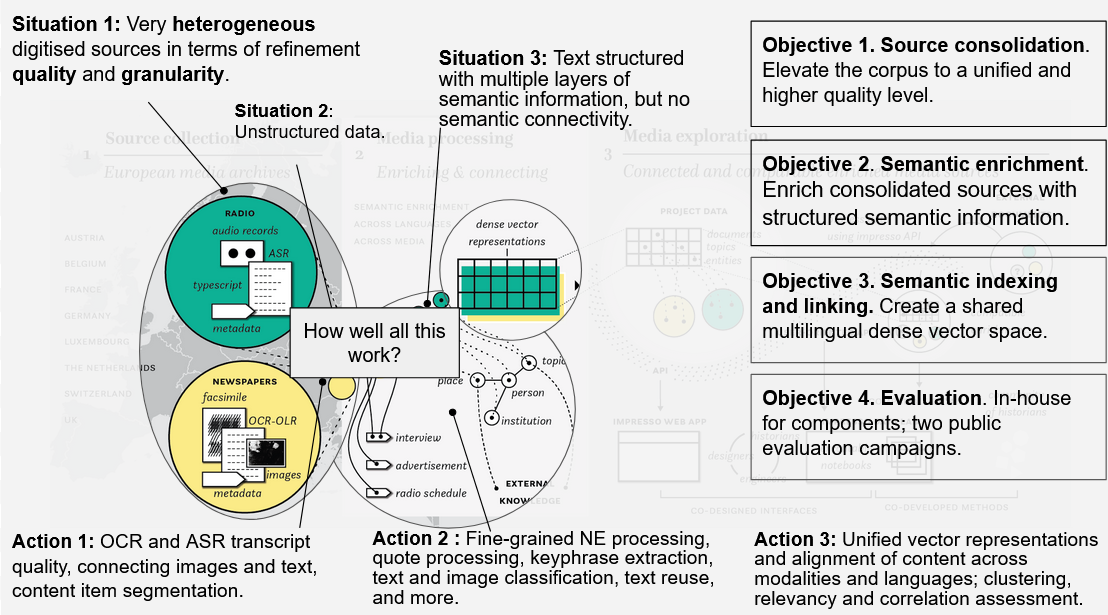
Impresso’s approach to enrich and connect historical media collections
For NLP, dense vector representations enable the effective linking of different types of documents (newspaper articles, manuscripts, tapuscripts, speech-to-text transcripts, images, programming information, …) across languages. Juri Opitz introduced the topic and gave real-world examples to illustrate the potential inherent in different types of embeddings.

Case study of cross-lingual embeddings to link semantically related articles across languages, using the Kaiseraugst nuclear plant project as an example
A first case study presented by Andrianos Michail and Simon Clematide demonstrated how cross-lingual embeddings can already effectively link semantically related articles. Using the example of the failed project to build a nuclear plant in Kaiseraugst (CH), they were able to effectively link closely related articles in German and French-language.

Participants engaged in a session at the Impresso workshop in Lausanne
Integration of different types of data: From acquisition to frontend and annotation services
An often overlooked “hidden work” concerns the acquisition and preprocessing of data. Described as a “data journey”, Pauline Conti, Emanuela Boros and Maud Ehrmann presented and exemplified the workflow from data acquisition, data preparation, enrichment, ingestion and representation in Impresso’s frontend. This with special emphasis on the documentation of workflows and versions as a means to achieve greater efficiency and transparency. Impresso’s system architecture will add new forms of access to the data: apart from the web app, direct API access will enable research as part of the Impresso data lab and the creation of annotation services hosted by Hugging Face.
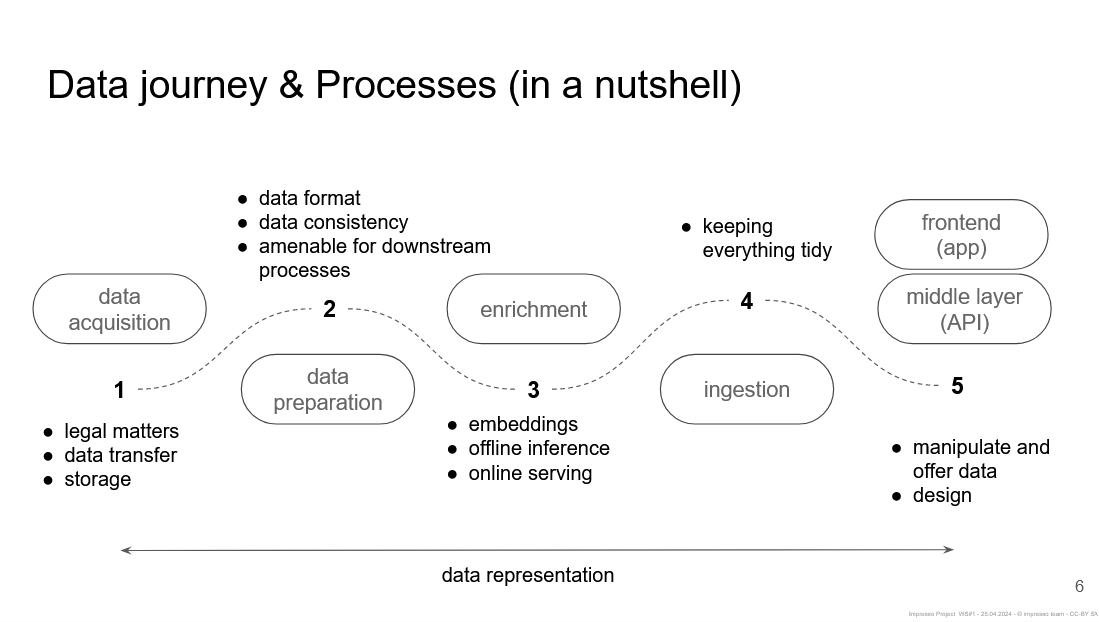
Overview of the data journey and processes in the Impresso project: from acquisition and preparation to enrichment, ingestion, and frontend integration

Maud Ehrmann and Pauline Conti presenting the complexities of organizing radio broadcasts and aligning them with newspaper publications
Are radio broadcasts conceptually analogous to podcasts? Whereas the first Impresso project could rely on the straightforward structure of newspapers (titles, issues, pages, content items), radio content is far more complex: How to name individual broadcasts? How to group them? How to align them with newspaper publications in a meaningful way? These questions were presented and discussed by Maud Ehrmann and Pauline Conti with active discussion among all participants.
Updates to the Impresso web app and a first look at the forthcoming Impresso data lab
The arrival of new types of data (manuscripts, tapuscripts, audio, etc.) also requires an update and expansion of the Impresso web app - together with an effort towards smoother usage experience. Our biggest design efforts will however go towards the creation of the Impresso data lab. The data lab enables question-specific, and especially data-driven research which goes beyond the capabilities of the web app with its focus on data exploration. Access to integrated semantic enrichments via API, a dedicated Impresso Python library and easy access to interactive notebooks open up countless opportunities to analyse Impresso’s data.
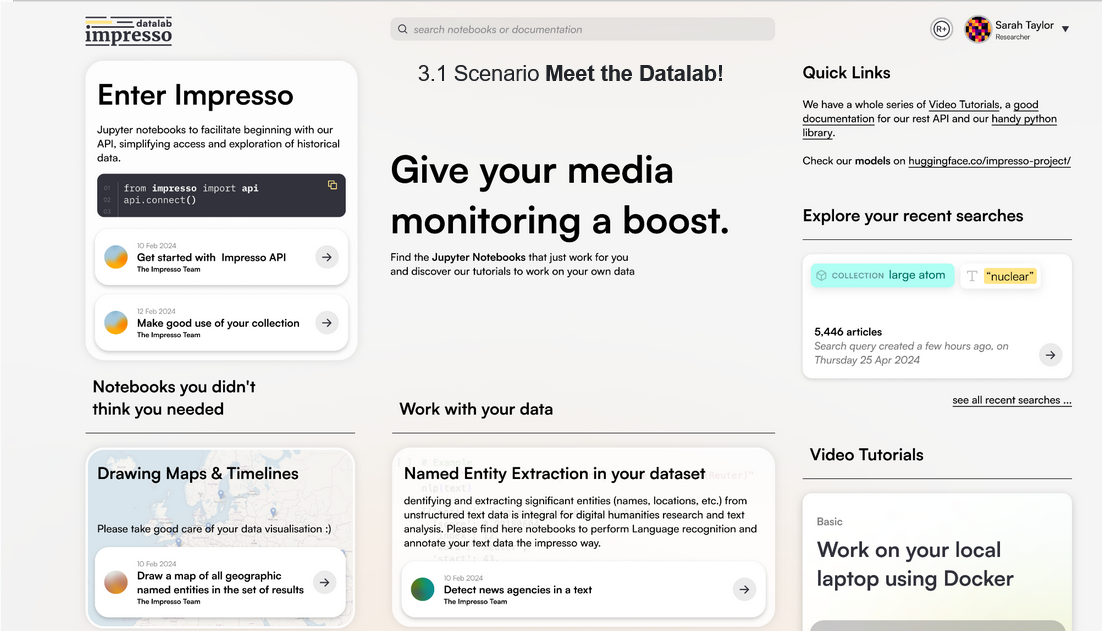
First overview of the forthcoming Impresso data lab
Daniele Guido presented the future vision of the data lab as a site to access and reuse pre-published notebooks which allow custom analysis and visualisation of Impresso data but also the additional enrichment of external data using models provided by the project. A first example is the detection of press agencies in historical newspaper articles based on a model developed by former EPFL student Lea Marxen. In line with Impresso’s emphasis on legal compliance, the presentation also included a proposition for different access groups and a workflow to validate user access to protected materials.
Influences, transnational media history and computational humanities
That the cross-lingual and multimodal research objectives of Impresso’s NLP team align nicely with those of media historians and increasingly data-driven research workflows in the humanities was underlined by Raphaelle Ruppen Coutaz and Marten Düring. Media history as a field increasingly moves away from a focus of institutional histories to a broader interest in the evolution of historical media ecosystems in transnational context - not least evidenced by the long-standing research activities of the Entangled Media Histories research network, represented on-site by Hans-Ulrich Wagner.

Impresso’s historical research objectives and case studies
Parallel to this transnational perspective on history, the “Collections as Data” movement to enable data-driven research, the rise of interactive notebooks as research media and an increased interest in the computational analysis of audiovisual materials together create a fertile space to undertake innovative “digital media history”. To this end, Impresso will strive to provide a methodological framework for collaborative and data-driven research and establish a community of researchers.
The viewpoints of the libraries
One of Impresso’s central goals is to establish productive partnerships with all associated institutions such as libraries, archives and research networks. We were therefore grateful to learn more about their ongoing activities with digitised collections and the opportunities and challenges they have identified along the way.
Simone Comte of Radio Television Suisse (RTS) pointed to ongoing efforts in speech-to-text recognition and reported from promising experiments for the creation of novel metadata such as speaker identification.
Max Kaiser and Christoph Steindl of the National Library of Austria (ONB) presented their work with ONB labs and showcased, for example, the Annolyzer platform with its roots in the NewsEye project.
Jean-Philippe Moreux of the National Library of France (BNF) highlighted an internal project to enrich Gallica’s image collections with the help of OpenCLIP to effectively enable text-to-image and image-to-text searches.
Steven Claeyssens of the National Library of the Netherlands (KB) discussed the KB’s stance in light of the mass scraping of content provided by cultural heritage institutions in breach of existing copyright laws which they published in form of a Statement on commercial and generative AI.
Finally, Carlo Blum of the National Library of Luxembourg (BNL) presented the legal framework behind their newspaper collections, inherent restrictions and their practices in data sharing for research purposes, highlighting their policy to have their data used as much as possible.
Access policies across institutions, copyrights and access for research purposes
Our goal to compile, enrich and make available for research purposes a corpus of historical media encompassing eight countries brings legal alongside technical challenges. The former were discussed in a final session. Maud Ehrmann and Simon Clematide led the discussion and presented Impresso’s vision to give access to research data in compliance with diverse copyright restrictions and varying data access policies by the partnering institutions. This included different user plans as well as a fine grained access management control which respects the complex legal framework which characterise historical media data.

Impresso team and partners at first Impresso workshop in Lausanne
We would like to thank all partners who made the trip to Lausanne and those who joined us online for their interest in Impresso and their willingness to support our efforts. To be continued!

Participants enjoying the scenic surroundings of EPFL, Lausanne, as the first Impresso workshop comes to a close
List of Participants
Impresso Doppio Partners
- Rossitza Atanassova – British Library, Great Britain
- Carlo Blum – National Library of Luxemburg, Luxemburg
- Steven Claeyssens – National Library of the Netherlands, The Netherlands
- Simone Comte – Radio Télévision Suisse, Switzerland
- Brecht Deseure – Royal Library of Belgium, Belgium
- Beth Gaskell – British Library, Great Britain
- Martina Hoffmann – Swiss National Library, Switzerland
- Max Kaiser – Austrian National Library, Austria
- Michael Kubina – Hamburg State and University Library, Germany
- Margaux L’Eplattenier – Bibliothèque Cantonale Universitaire de Lausanne, Switzerland
- Jean-Philippe Moreux – Bibliothèque nationale de France, France
- Théophile Naito – Bibliothèque Cantonale Universitaire de Lausanne, Switzerland
- Enrico Natale – Infoclio.ch, Switzerland
- Olivier Perrin – Le Temps Journal, Switzerland
- Christoph Steindl – Austrian National Library, Austria
- Simon Tamyalew – Deutschlandradio, Germany
- Hans-Ulrich Wagner – EMHIS, Germany
Impresso Doppio Project Members
- Emanuela Boros – EPFL, Switzerland
- Simon Clematide – UZH, Switzerland
- Pauline Conti – EPFL, Switzerland
- Marten Düring – C2DH, Luxemburg
- Maud Ehrmann – EPFL, Switzerland
- Daniele Guido – C2DH, Luxemburg
- Raphaëlle Ruppen Coutaz – UNIL, Switzerland
- Martin Grandjean – UNIL, Switzerland
- Andrianos Michail – UZH, Switzerland
- Arthur Michelet – UNIL, Switzerland
- Juri Opitz – UZH, Switzerland
- Lars Wieneke – C2DH, Luxemburg
This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License.
A Creative Commons Attribution-NoDerivatives 4.0 (CC BY-ND 4.0) license applies
to all contents published in impresso. While articles published on impresso can
be copied by anyone for noncommercial purposes if proper credit is given,
all materials are published under an open-access license with authors retaining
full and permanent ownership of their work.