🤗 Chat UI
Open source chat interface with support for tools, web search, multimodal and many API providers. The app uses MongoDB and SvelteKit behind the scenes. Try the live version of the app called HuggingChat on hf.co/chat or setup your own instance.
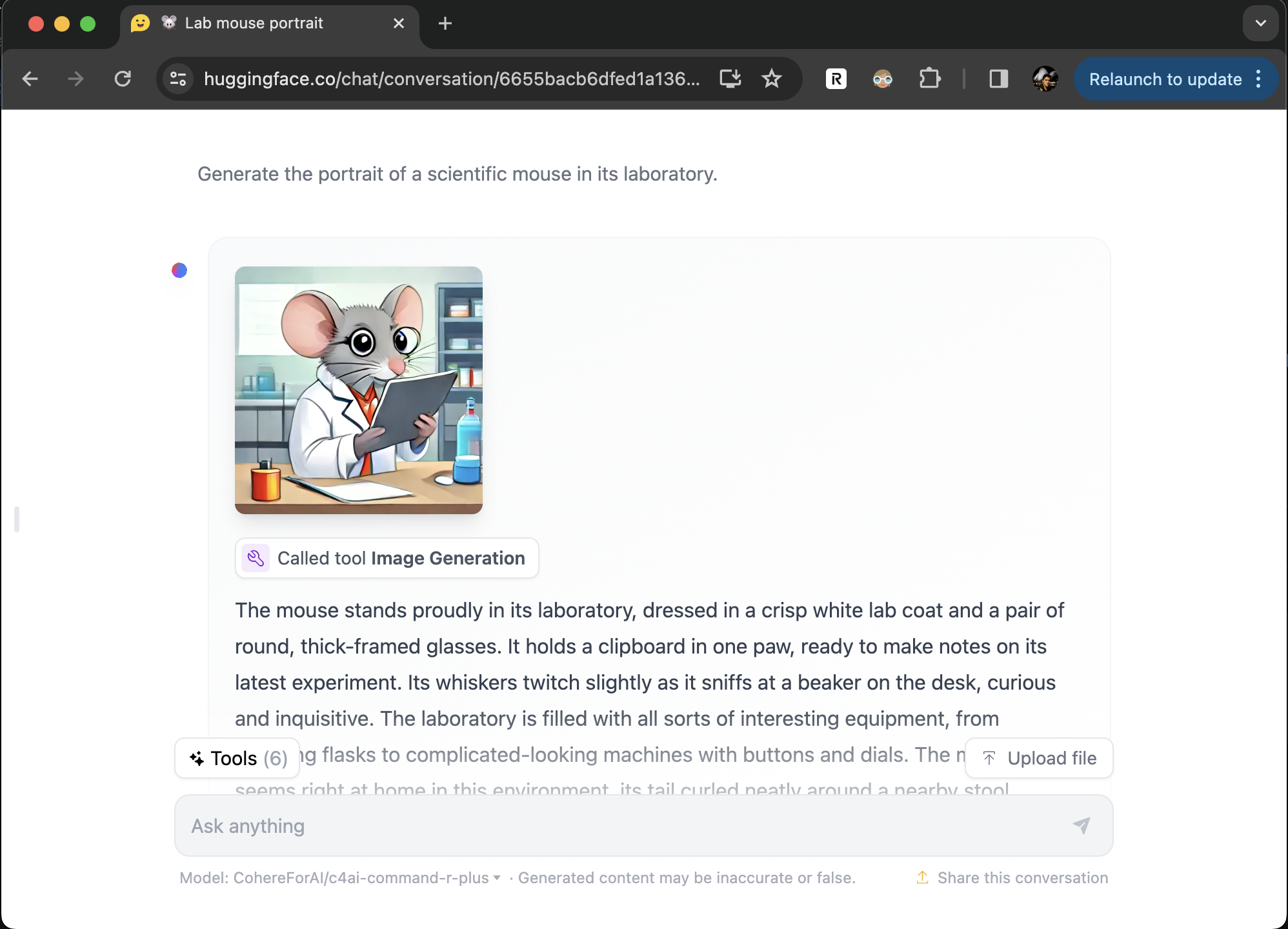
🔧 Tools: Function calling with custom tools and support for Zero GPU spaces
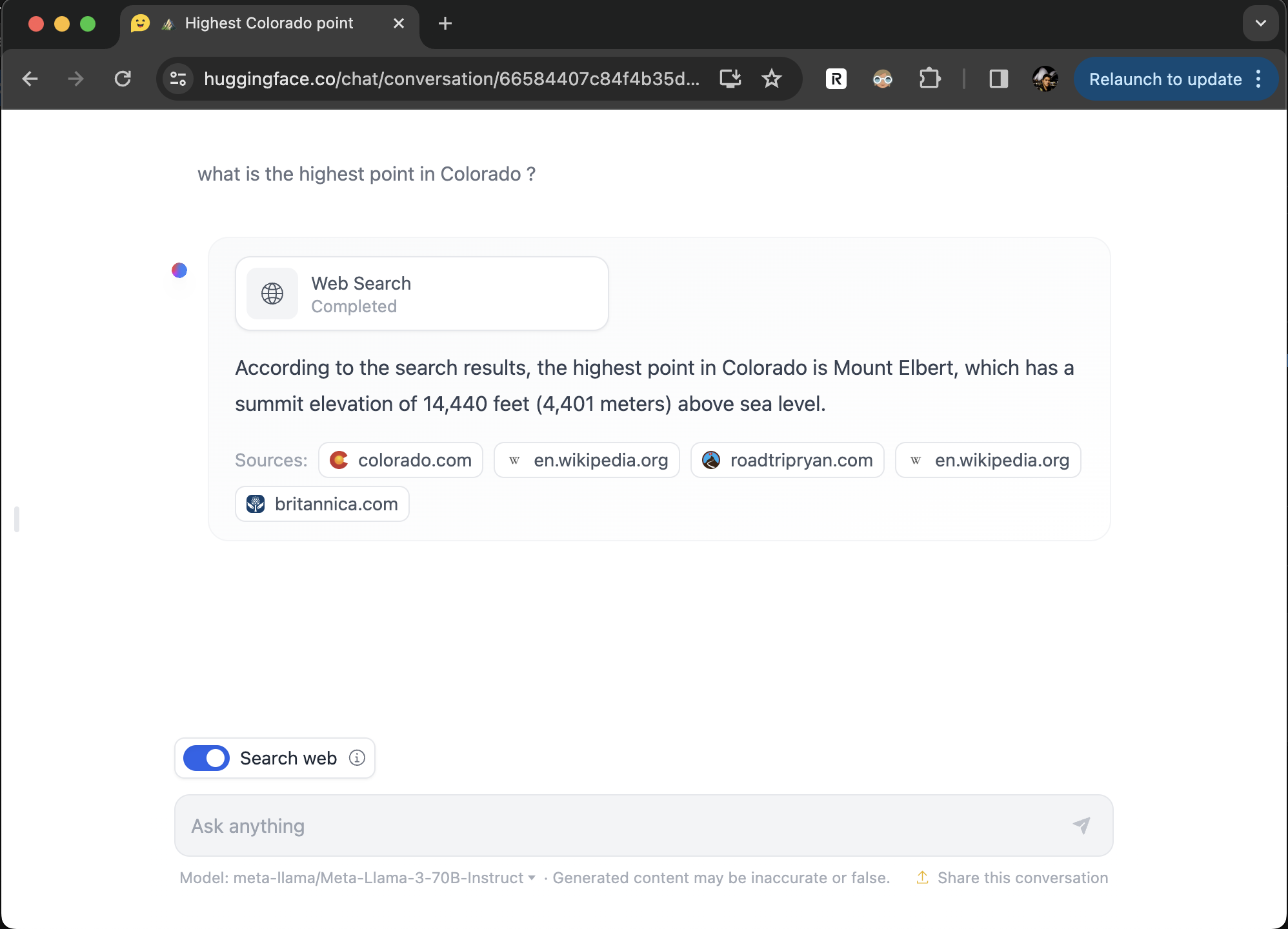
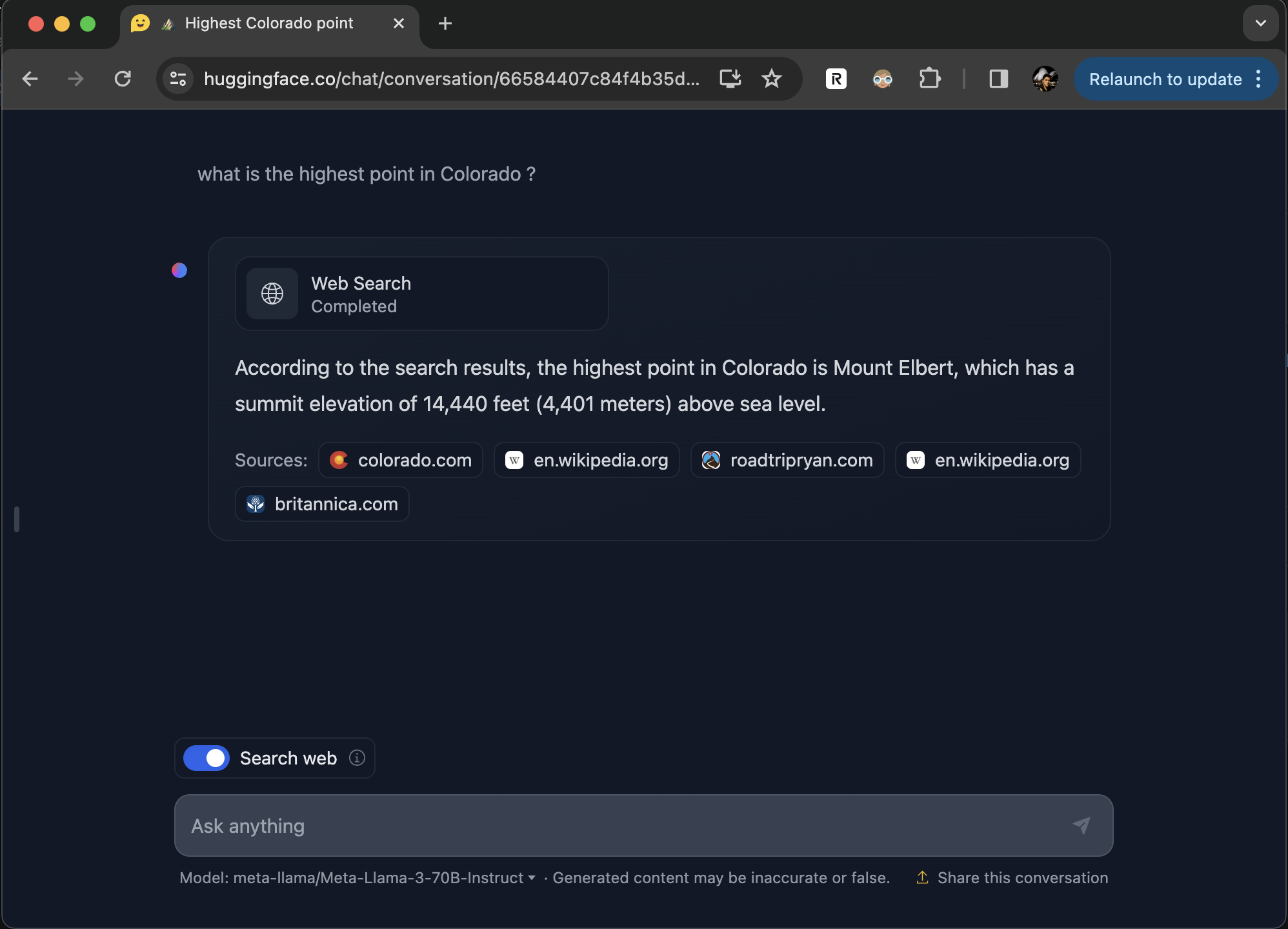
🔍 Web Search: Automated web search, scraping and RAG for all models
🐙 Multimodal: Accepts image file uploads on supported providers
👤 OpenID: Optionally setup OpenID for user authentication
Quickstart
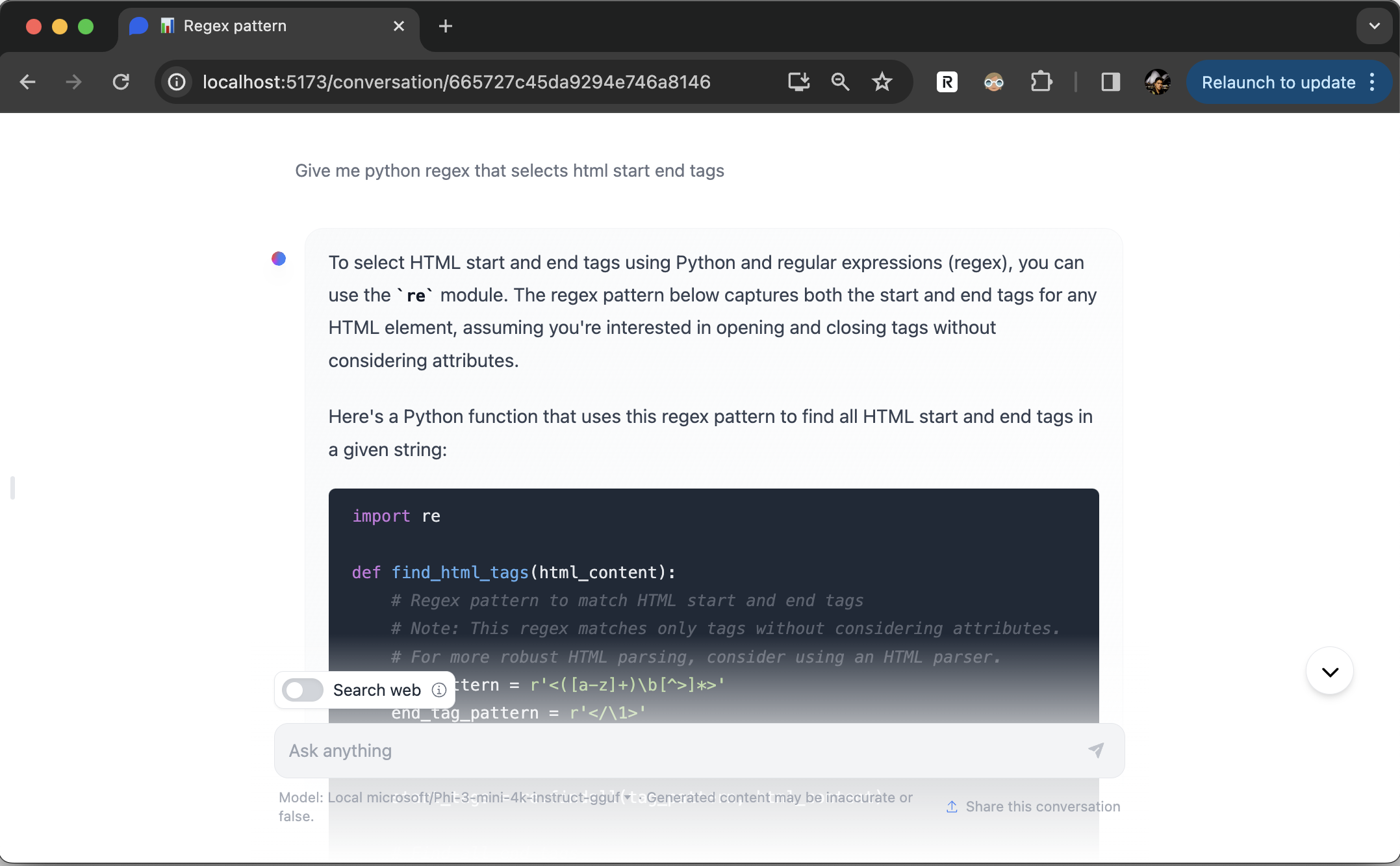
You can quickly have a locally running chat-ui & LLM text-generation server thanks to chat-ui’s llama.cpp server support.
Step 1 (Start llama.cpp server):
# install llama.cpp
brew install llama.cpp
# start llama.cpp server (using hf.co/microsoft/Phi-3-mini-4k-instruct-gguf as an example)
llama-server --hf-repo microsoft/Phi-3-mini-4k-instruct-gguf --hf-file Phi-3-mini-4k-instruct-q4.gguf -c 4096A local LLaMA.cpp HTTP Server will start on http://localhost:8080. Read more here.
Step 2 (tell chat-ui to use local llama.cpp server):
Add the following to your .env.local:
MODELS=`[
{
"name": "Local microsoft/Phi-3-mini-4k-instruct-gguf",
"tokenizer": "microsoft/Phi-3-mini-4k-instruct-gguf",
"preprompt": "",
"chatPromptTemplate": "<s>{{preprompt}}{{#each messages}}{{#ifUser}}<|user|>\n{{content}}<|end|>\n<|assistant|>\n{{/ifUser}}{{#ifAssistant}}{{content}}<|end|>\n{{/ifAssistant}}{{/each}}",
"parameters": {
"stop": ["<|end|>", "<|endoftext|>", "<|assistant|>"],
"temperature": 0.7,
"max_new_tokens": 1024,
"truncate": 3071
},
"endpoints": [{
"type" : "llamacpp",
"baseURL": "http://localhost:8080"
}],
},
]`Read more here.
Step 3 (make sure you have MongoDb running locally):
docker run -d -p 27017:27017 --name mongo-chatui mongo:latest
Read more here.
Step 4 (start chat-ui):
git clone https://github.com/huggingface/chat-ui
cd chat-ui
npm install
npm run dev -- --openRead more here.